大数据 hadoop ------ pig hiveMahouthbase
Posted caicai920
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据 hadoop ------ pig hiveMahouthbase相关的知识,希望对你有一定的参考价值。
pig
Pig最早是雅虎公司的一个基于Hadoop的并行处理架构,后来Yahoo将Pig捐献给Apache的一个项目,由Apache来负责维护,Pig是一个基于 Hadoop的大规模数据分析平台。
Pig为复杂的海量数据并行计算提供了一个简 易的操作和编程接口,这一点和FaceBook开源的Hive一样简洁,清晰,易上手!
Pig包括 两部分
1:用于描述数据流的语言,称为 Pig Latin (拉丁猪,个人翻译)
2:用于运行PigLatin程序的 执行环境 。一个是 本地 的单JVM执行环境,一个就是在 hadoop集群上 的分布式执行环境。
作用:
雅虎公司主要使用Pig:
1)吸收和分析用户的行为日志数据(点击流分析、搜索内容分析等),改进匹配和排名算法,以提高检索和广告业务的质量。
2)构建和更新search index。对于web-crawler抓取了的内容是一个流数据的形式,这包括去冗余、链接分析、内容分类、基于点击次数的受欢迎程度计算(PageRank)、最后建立倒排表。
3)处理半结构化数据订阅(data seeds)服务。包括:deduplcaitin(去冗余),geographic location resolution,以及 named entity recognition.
优势与不足
MapReducer能够让我们自己定义 连续执行的map和reduce函数 ,但是数据处理往往需要很多的MapReducer过程才能实现,所以将数据处理要求改写成MapReducer模式是很 复杂的 。和MapReducer相比,Pig提供了更加 丰富的数据结构 ,一般都是 多值 和 嵌套 的数据结构。Pig还提供了一套更强大的 数据交换操作 ,包括了MapReducer中被忽视的" join "操作
使用Pig来操作hadoop处理海量数据,是非常简单的,如果没有Pig,我们就得手写MapReduce代码,这可是一件非常繁琐的事,因为MapReduce的任务职责非常明确,清洗数据得一个job,处理得一个job,过滤得一个job,统计得一个job,排序得一个job,每次只要改动很小的一个地方,就得重新编译整个job,然后打成jar提交到Hadoop集群上运行,是非常繁琐的,调试还很困难。
但是,Pig并不适合处理所有的“数据处理”任务。和MapReducer一样,它是为数据 批处理 而设计的,如果想执行的查询只涉及一个大型数据集的一小部分数据,Pig的实现不是很好, 因为它要扫描整个数据集或其中的很大一部分。
Pig 有两种运行模式:
1、local 模式 : Pig 运行local模式,只涉及单独一台计算的
2、mapReduce 模式:需要可以访问一个hadoop集群,并且需要装上HDFS
Pig 的调用方式:
grunt shell 方式:通过交互方式,输入命令执行任务
Pig script 方式:通过script脚本方式来运行任务
嵌入式方式:嵌入java源码中,通过java调用运行任务
Pig 工作原理:
Apache PIG提供一套高级语言平台,用于对结构化与非结构化数据集进行操作与分析。这种语言被称为Pig Latin,其属于一种脚本形式,可直接立足于PIG shell执行或者通过Pig Server进行触发。用户所创建的脚本会在初始阶段由Pig Latin处理引擎进行语义有效性解析,而后被转换为包含整体执行初始逻辑的定向非循环图(简称DAG)。
为了理解这一优化机制的原理,我们假定用户编写了一套脚本,该脚本对两套数据集进行一项连接操作,而后是一条过滤标准。PIG优化器能够验证过滤操作是否能够在连接之前进行,从而保证连接负载最小化。如果可以,则其将据此进行逻辑规划设计。如此一来,用户即可专注于最终结果,而非将精力分散在性能保障身上。
只有在经过完全优化的逻辑规划准备就绪之后,编译才会生效。其负责生成物理规划,即为最终驻留于HDFS中的数据分配与之交互的执行引擎。
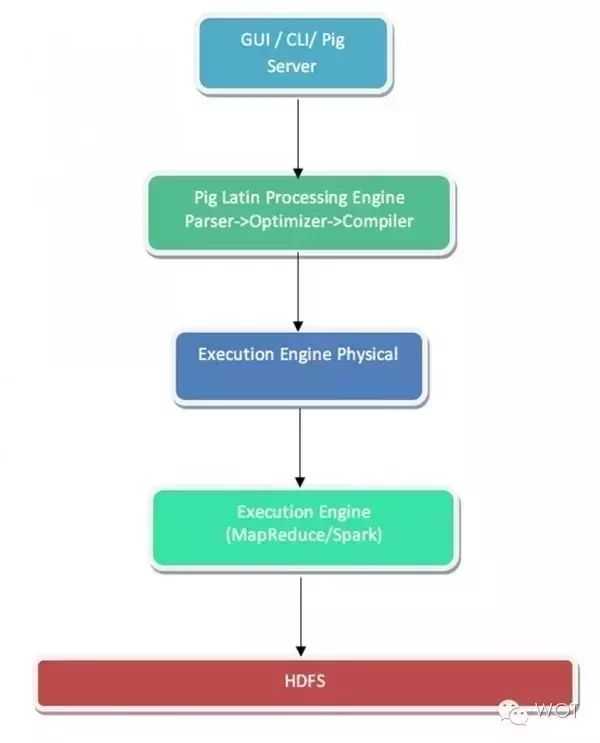
测试案例:
某网站访问日志,请大家使用 pig 计算出每个 ip 的点击次数
//加载HDFS中访问日志,使用空格进行分割,只加载ip列
records = LOAD ‘hdfs://hadoop:9000/class7/input/website_log.txt‘ USING PigStorage(‘ ‘) AS (ip:chararray);
// 按照ip进行分组,统计每个ip点击数
records_b = GROUP records BY ip;
records_c = FOREACH records_b GENERATE group,COUNT(records) AS click;
// 按照点击数排序,保留点击数前10个的ip数据
records_d = ORDER records_c by click DESC;
top10 = LIMIT records_d 10;
// 把生成的数据保存到HDFS的class7目录中
STORE top10 INTO ‘hdfs://hadoop:9000/class7/out‘;
Hive
尽管Apache Pig性能优异,但是它要求程序员要掌握SQL之外的知识。Hive和SQL非常相似,虽然Hive查询语言(HQL)有一定的局限性,但它仍然是非常好用的。Hive为MapReduce提供了很好的开源实现。它在分布式处理数据方面表现很好,不像SQL需要严格遵守模式。
hive 工作原理:
Apache Hive在本质上属于一套数据仓储平台,用于同存储在HDFS或者HBase内的大规模结构化数据集进行交互。Hive查询语言在这一点上类似于SQL,二者都能够与Hadoop实现良好集成。而Pig则不同,其执行流程为纯声明性,因此适合供数据科学家用于实现数据呈现与分析。
在与Hive进行交互时,用户可以直接通过Hive命令行界面直接接入,或者与Hiveserver交互。任何提交查询都会首先由该驱动程序占用,而后由编译器进行语法及语义验证。另外,Hive metastore负责保存全部与Hive相关数据的模式/映射关系,其在验证查询中信息语义方面扮演着重要角色。
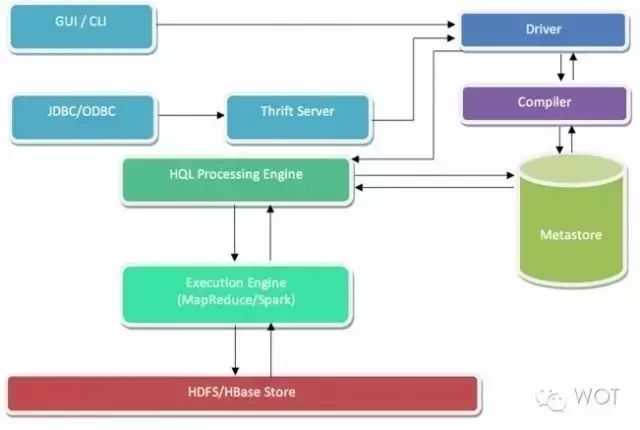
服务端组件:
Driver 组件:该组件包括 Complier、Optimizer 和 Executor,它的作用是将 HiveQL(类 SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的 MapReduce 计算框架;Metastore 组件:元数据服务组件,这个组件存储 Hive 的元数据,Hive 的元数据存储在关系数据库里,Hive 支持的关系数据库有 derby 和 mysql。元数据对于 Hive 十分重要,因此 Hive 支持把 metastore 服务独立出来,安装到远程的服务器集群里,从而解耦 Hive 服务和 metastore 服务,保证 Hive 运行的健壮性;Thrift 服务:Thrift 是 facebook 开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发
客户端组件:
CLI:command line interface,命令行接口。Thrift 客户端:上面的架构图里没有写上 Thrift 客户端,但是 Hive 架构的许多客户端接口是建立在 Thrift 客户端之上,包括 JDBC 和 ODBC 接口。WEBGUI:Hive 客户端提供了一种通过网页的方式访问 hive 所提供的服务。这个接口对应 Hive 的 hwi 组件(hive web interface),使用前要启动 hwi 服务。
Tips mysql 首次安装修改密码
sudo mysqld_safe --skip-grant-tables & sudo service mysql status
mysql -u root mysql> use mysql;
mysql> update user set password = password(‘root‘) where user = ‘root‘;
mysql> flush privileges;
mysql> quit;
sudo service mysql restart
sudo service mysql status
# 创建 hive 用户,若已经存在则无需再创建
mysql> create user ‘hive‘ identified by ‘hive‘;
# 赋予权限
mysql> grant all on *.* TO ‘hive‘@‘%‘ identified by ‘hive‘ with grant option;
mysql> grant all on *.* TO ‘hive‘@‘localhost‘ identified by ‘hive‘ with grant option;
# 刷新 MySQL 的系统权限相关表,否则会出现拒绝访问,还有一种方法是重新启动 mysql 服务器,来使新设置生效。
mysql> flush privileges;
Hive 命令
启动:hive
hive 之前需要启动 metastore 和 hiveserver 服务
hive --service metastore &
hive --service hiveserver &
总结
Hive更适合于数据仓库的任务,Hive主要用于静态的结构以及需要经常分析的工作。Hive与SQL相似促使 其成为Hadoop与其他BI工具结合的理想交集。而且很多企业都需要对历史数据进行分析,Hive就是一款分析历史数据的利器。但是Hive只有在结构化数据的情况下才能大显神威。Hive的软肋是实时分析,如果想要进行实时分析,可以采用HBase。
Pig赋予开发人员在大数据集领域更多的灵活性,并允许开发简洁的脚本用于转换数据流以便嵌入到较大的 应用程序。并且Apache Pig适用于非结构化的数据集,可以充分利用SQL。Pig无需构建MapReduce任务,如果你有SQL学习的背景,那么入门会非常快。
以上文章来源 :https://www.cnblogs.com/yezl/p/7787336.html 、 https://www.shiyanlou.com/
Mahout简介
Apache Mahout是ApacheSoftware Foundation (ASF)旗下的一个开源项目,提供了一些经典的机器学习的算法,皆在帮助开发人员更加方便快捷地创建智能应用程序。目前已经有了三个公共发型版本,通过ApacheMahout库,Mahout可以有效地扩展到云中。Mahout包括许多实现,包括聚类、分类、推荐引擎、频繁子项挖掘。
Apache Mahout的主要目标是建立可伸缩的机器学习算法。这种可伸缩性是针对大规模的数据集而言的。Apache Mahout的算法运行在ApacheHadoop平台下,他通过Mapreduce模式实现。但是,Apache Mahout并非严格要求算法的实现基于Hadoop平台,单个节点或非Hadoop平台也可以。Apache Mahout核心库的非分布式算法也具有良好的性能。
mahout主要包含以下5部分
频繁挖掘模式:挖掘数据中频繁出现的项集。
聚类:将诸如文本、文档之类的数据分成局部相关的组。
分类:利用已经存在的分类文档训练分类器,对未分类的文档进行分类。
推荐引擎(协同过滤):获得用户的行为并从中发现用户可能喜欢的事物。
频繁子项挖掘:利用一个项集(查询记录或购物记录)去识别经常一起出现的项目。
————————————————
版权声明:本文为CSDN博主「鲍礼彬」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/baolibin528/article/details/39760443
Hadoop家族中Mahout的结构图
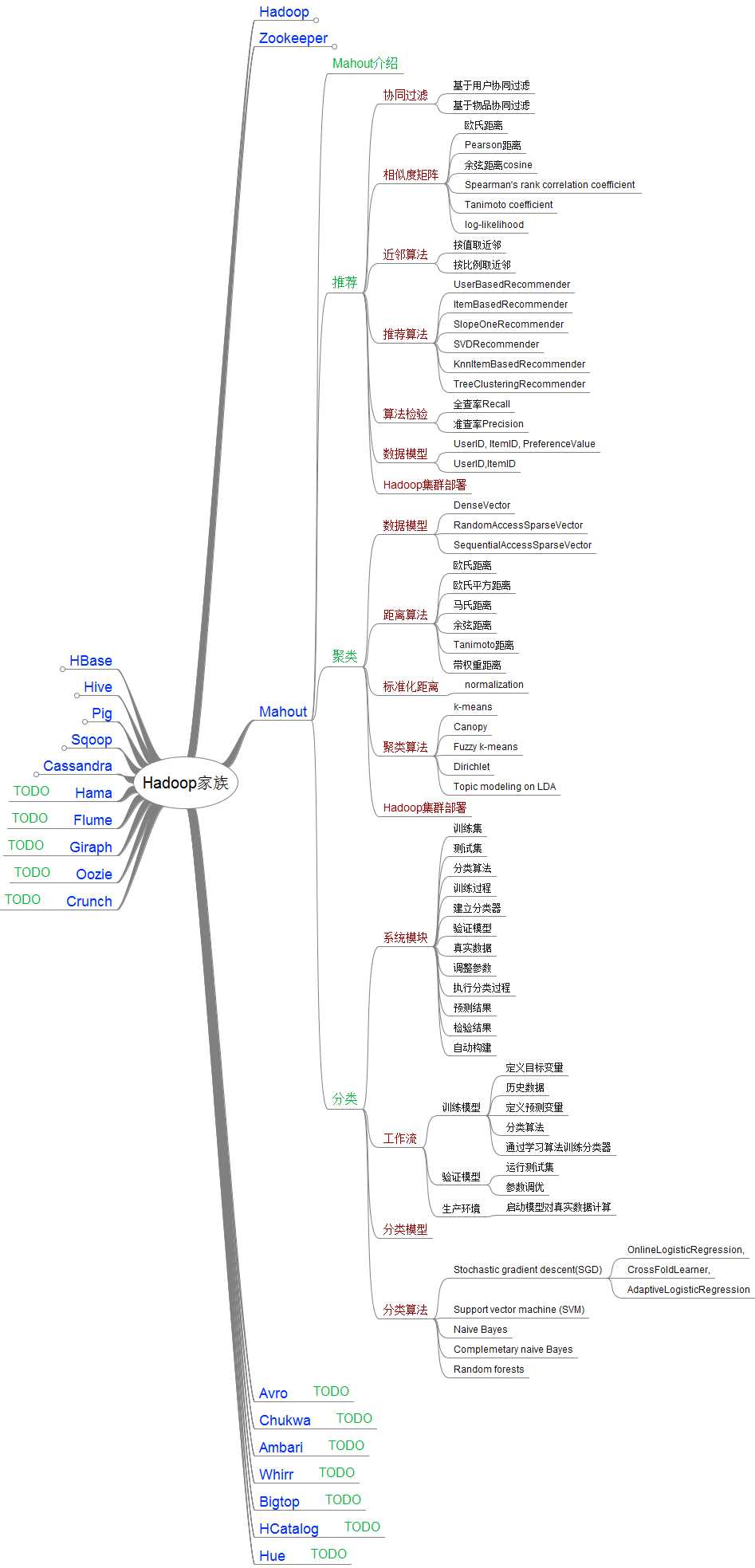
主要算法:
|
算法类 |
算法名 |
中文名 |
|
分类算法 |
Logistic Regression |
逻辑回归 |
|
Bayesian |
贝叶斯 |
|
|
SVM |
支持向量机 |
|
|
Perceptron |
感知器算法 |
|
|
Neural Network |
神经网络 |
|
|
Random Forests |
随机森林 |
|
|
Restricted Boltzmann Machines |
有限波尔兹曼机 |
|
|
聚类算法 |
Canopy Clustering |
Canopy聚类 |
|
K-means Clustering |
K均值算法 |
|
|
Fuzzy K-means |
模糊K均值 |
|
|
Expectation Maximization |
EM聚类(期望最大化聚类) |
|
|
Mean Shift Clustering |
均值漂移聚类 |
|
|
Hierarchical Clustering |
层次聚类 |
|
|
Dirichlet Process Clustering |
狄里克雷过程聚类 |
|
|
Latent Dirichlet Allocation |
LDA聚类 |
|
|
Spectral Clustering |
谱聚类 |
|
|
关联规则挖掘 |
Parallel FP Growth Algorithm |
并行FP Growth算法 |
|
回归 |
Locally Weighted Linear Regression |
局部加权线性回归 |
|
降维/维约简 |
Singular Value Decomposition |
奇异值分解 |
|
Principal Components Analysis |
主成分分析 |
|
|
Independent Component Analysis |
独立成分分析 |
|
|
Gaussian Discriminative Analysis |
高斯判别分析 |
|
|
进化算法 |
并行化了Watchmaker框架 |
|
|
推荐/协同过滤 |
Non-distributed recommenders |
Taste(UserCF, ItemCF, SlopeOne) |
|
Distributed Recommenders |
ItemCF |
|
|
向量相似度计算 |
RowSimilarityJob |
计算列间相似度 |
|
VectorDistanceJob |
计算向量间距离 |
|
|
非Map-Reduce算法 |
Hidden Markov Models |
隐马尔科夫模型 |
|
集合方法扩展 |
Collections |
扩展了java的Collections类
|
结构图与算法 来源于:https://www.cnblogs.com/xiangfeng/p/4362301.html
HBase 介绍
HBase - Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase是Google BigTable的开源实现,类似Google BigTable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应
优势:
>写入性能高,且几乎可以无限扩展。
>海量数据下(100TB级别表)的查询依然能保持在5ms级别。
>存储容量大,不需要做分库分表,切勿维护简单。
>表的列可以灵活配置,1行可以有多个非固定的列。
劣势:
>并不能保证100%时间可用,宕机回复时间根据写入流量不同在几秒到几十秒内。
>查询便利性上缺少支持sql语句。
>无索引,查询必须按照RowKey严格查询,不带RowKey的filter性能较低。
>对于查询会有一些毛刺,特别是在compact时,平均查询延迟在2~3ms,但是毛刺时会升高到几十到100多毫秒。
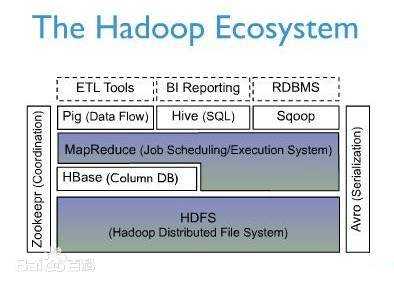
上图描述了 Hadoop EcoSystem 中的各层系统,其中 HBase 位于结构化存储层,Hadoop HDFS 为 HBase 提供了高可靠性的底层存储支持,Hadoop MapReduce 为 HBase 提供了高性能的计算能力,Zookeeper 为 HBase 提供了稳定服务和 failover 机制。
此外,Pig 和 Hive 还为 HBase 提供了高层语言支持,使得在 HBase 上进行数据统计处理变的非常简单。 Sqoop 则为 HBase 提供了方便的 RDBMS 数据导入功能,使得传统数据库数据向 HBase 中迁移变的非常方便
|
Row Key
|
Timestamp
|
Column Family
|
|
|
URI
|
Parser
|
||
|
r1
|
t3
|
url=http://
|
title=
|
|
t2
|
host=com
|
||
|
t1
|
|||
|
r2
|
t5
|
url=http://
|
content=每天…
|
|
t4
|
host=com
|


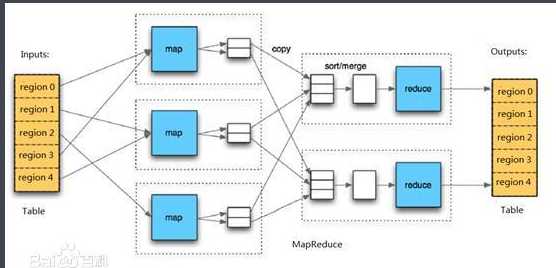
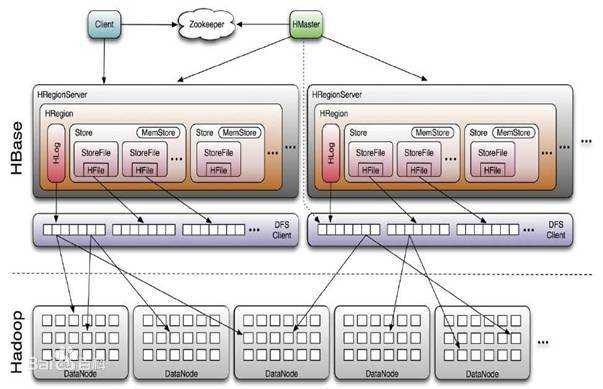
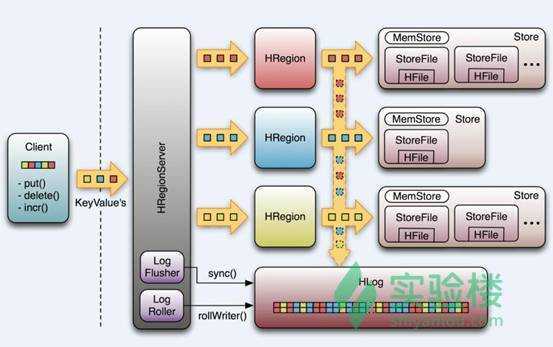
Client
Zookeeper
HMaster
HRegionServer
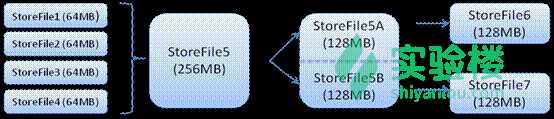
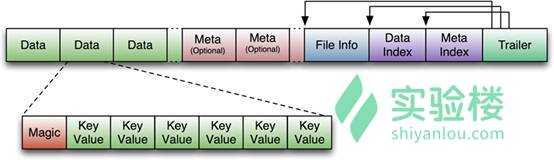
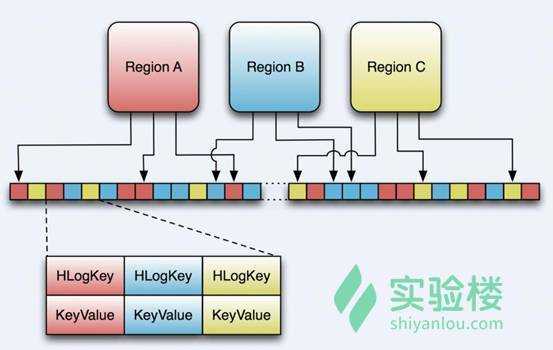
参考来源于 : https://baike.baidu.com/item/HBase/7670213?fr=aladdin 、 https://www.shiyanlou.com/ 、 https://www.cnblogs.com/xiangfeng/p/4362301.html
以上是关于大数据 hadoop ------ pig hiveMahouthbase的主要内容,如果未能解决你的问题,请参考以下文章