Mysql之索引
Posted 大圣
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql之索引相关的知识,希望对你有一定的参考价值。
索引的产生
当数据库引擎为InnoDB时插入数据的时候则会根据主键排序(如果没有主键呢?mysql会有一个隐藏的字段来排序)
当数据库引擎为MyISAM时插入数据的时候则会根据插入时的顺序来排序
在InnoDB下建议建表时必须创建主键,并且建议使用整型且为自增;在维护索引B+树的时候会相对来说性能会好很多
索引结构:
- Hash结构:根据索引进行hash运算,但是当where条件为范围查询的时候就无法查询。估计这就是不太常用的原因吧
- B+树结构:B+树结构比较常用,3~5层树结构就能排序上千万的数据。查询速率还是很牛逼了。
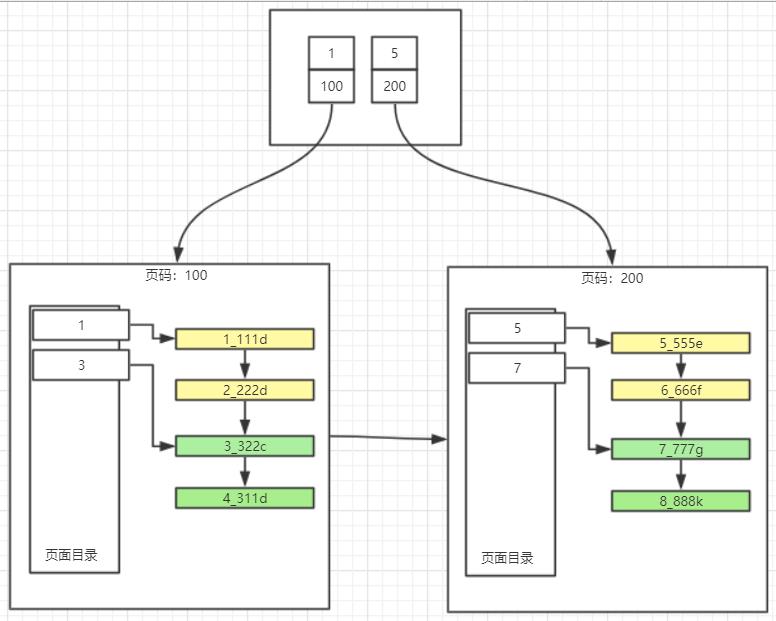
聚簇(聚集)索引
聚簇索引的特点:
1. 按主键值的大小进行记录和页的排序:
- 数据页(叶子节点)里的记录是按照主键值从小到大排序的一个单向链表。
- 数据页(叶子节点)之间也是是按照主键值从小到大排序的一个双向链表。
- B+树中同一个层的页目录也是按照主键值从小到大排序的一个双向链表。
2. B+树的叶子节点存储的是完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。
具有这两种特性的B+树称为聚簇索引,所有完整的用户记录都存放在这个聚簇索引的叶子节点处。这种聚簇索引并不需要我们在MySQL语句中显式的使用INDEX语句去创建。InnoDB存储引擎会自动的为我们创建聚簇索引。
在InnoDB存储引擎中,聚簇索引就是数据的存储方式(所有的用户记录都存储在了叶子节点),也就是所谓的索引即数据,数据即索引。
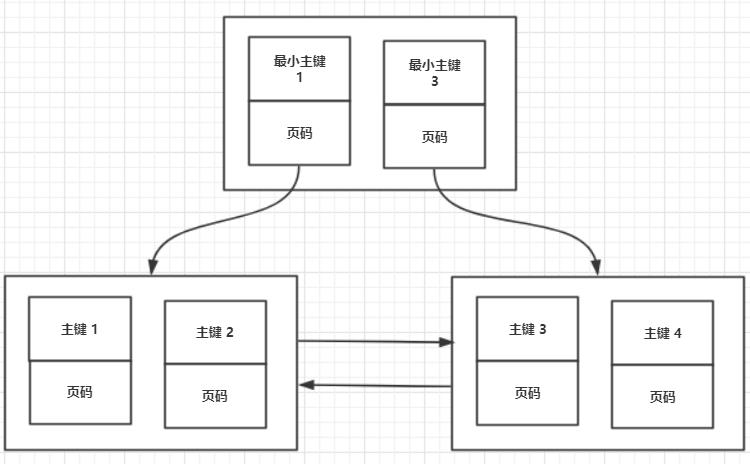
二级索引(复制索引)
聚簇索引只能在搜索条件是主键值时才能发挥作用,因为B+树中的数据都是按照主键进行排序的。当我们想以别的列作为搜索条件时我们可以多建几棵B+树,不同的B+树中的数据采用不同的排序规则。
二级索引与聚簇索引有几处不同:
1. 按指定的索引列的值来进行排序
2. 叶子节点存储的不是完整的用户记录,而只是索引列+主键。
3. 目录项记录中不是主键+页号,变成了索引列+页号。
4. 在对二级索引进行查找数据时,需要根据主键值去聚簇索引中再查找一遍完整的用户记录,这个过程叫做回表
联合索引
以多个列的大小为排序规则建立的B+树称为联合索引,本质上也是一个二级索引
目录项记录的唯一性
我们需要保证在B+树的同一层内节点的目录项记录除页号这个字段以外是唯一的。所以对于二级索引的内节点的目录项记录的内容实际上是由三个部分构成的:
- 索引列的值
- 主键值
- 页号
B+树总结
1. 每个索引都对应一棵B+树。用户记录都存储在B+树的叶子节点,所有目录记录都存储在非叶子节点。
2. InnoDB存储引擎会自动为主键(如果没有它会自动帮我们添加)建立聚簇索引,聚簇索引的叶子节点包含完整的用户记录。
3. 可以为指定的列建立二级索引,二级索引的叶子节点包含的用户记录由索引列 + 主键组成,所以如果想通过二级索引来查找完整的用户记录的话,需要通过回表操作,也就是在通过二级索引找到主键值之后再到聚簇索引中查找完整的用户记录。
4. B+树中每层节点都是按照索引列值从小到大的顺序排序而组成了双向链表,而且每个页内的记录(不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单链表。如果是联合索引的话,则页面和记录先按照联合索引前边的列排序,如果该列值相同,再按照联合索引后边的列排序。
5. 通过索引查找记录是从B+树的根节点开始,一层一层向下搜索。由于每个页面都按照索引列的值建立了页目录,所以在这些页面中的查找非常快
以上是关于Mysql之索引的主要内容,如果未能解决你的问题,请参考以下文章