MySQL优化
Posted 農農
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL优化相关的知识,希望对你有一定的参考价值。
1. 数据库三大范式
第一范式:1NF是对属性的原子性约束,要求属性(列)具有原子性,不可再分解;(只要是关系型数据库都满足1NF)
第二范式:2NF是对记录的惟一性约束,表中的记录是唯一的, 就满足2NF, 通常我们设计一个主键来实现,主键不能包含业务逻辑。
第三范式:3NF是对字段冗余性的约束,它要求字段没有冗余。 没有冗余的数据库设计可以做到。
但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。
2. 分表分库
2.1 垂直拆分
垂直拆分就是要把表按模块划分到不同数据库表中(当然原则还是不破坏第三范式),这种拆分在大型网站的演变过程中是很常见的。当一个网站还在很小的时候,只有小量的人来开发和维护,各模块和表都在一起,当网站不断丰富和壮大的时候,也会变成多个子系统来支撑,这时就有按模块和功能把表划分出来的需求。其实,相对于垂直切分更进一步的是服务化改造,说得简单就是要把原来强耦合的系统拆分成多个弱耦合的服务,通过服务间的调用来满足业务需求看,因此表拆出来后要通过服务的形式暴露出去,而不是直接调用不同模块的表,淘宝在架构不断演变过程,最重要的一环就是服务化改造,把用户、交易、店铺、宝贝这些核心的概念抽取成独立的服务,也非常有利于进行局部的优化和治理,保障核心模块的稳定性
垂直拆分用于分布式场景。
2.2 水平拆分
上面谈到垂直切分只是把表按模块划分到不同数据库,但没有解决单表大数据量的问题,而水平切分就是要把一个表按照某种规则把数据划分到不同表或数据库里。例如像计费系统,通过按时间来划分表就比较合适,因为系统都是处理某一时间段的数据。而像SaaS应用,通过按用户维度来划分数据比较合适,因为用户与用户之间的隔离的,一般不存在处理多个用户数据的情况,简单的按user_id范围来水平切分
通俗理解:水平拆分行,行数据拆分到不同表中, 垂直拆分列,表数据拆分到不同表中
2.3 水平分割案例
思路:在大型电商系统中,每天的会员人数不断的增加。达到一定瓶颈后如何优化查询。
可能大家会想到索引,万一用户量达到上亿级别,如何进行优化呢?
使用水平分割拆分数据库表。
2.4 如何使用水平拆分数据库
使用水平分割拆分表,具体根据业务需求,有的按照注册时间、取摸、账号规则、年份等
3. 取模算法:利用id取模进行表的拆分
3.1. 创建applcation.yml文件
spring: datasource: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/levelof username: root password: 123
3.2. 创建service层
@Service public class LevelServce { @Resource private JdbcTemplate jdbcTemplate; //用户注册的方法 public String register(String name,String password){ //向uuid表中插入数据 jdbcTemplate.update("insert into uuid values(null)"); //取模算法 //获取插入数据的id Integer id=jdbcTemplate.queryForObject("select last_insert_id()",Integer.class); //计算表 String tableName="user"+id%3; //向分表中插入数据 jdbcTemplate.update("insert into "+tableName+" values (\'"+id+"\',\'"+name+"\',\'"+password+"\')"); return "success"; } public String getUser(Integer id){ String tableName="user"+id%3; return jdbcTemplate.queryForObject(("select name from "+tableName),String.class); } }
3.3. 创建Controller层
@RestController public class LevelController { @Resource private LevelServce levelServce; @RequestMapping("/register") public String regster(String name,String password){ return levelServce.register(name,password); } @RequestMapping("/get") public String get(Integer id){ String tableName="user"+id%3; return levelServce.getUser(id); } }
3.4. 创建启动类
@SpringBootApplication public class StartLevel { public static void main(String[] args) { SpringApplication.run(StartLevel.class); } }
3.5.页面访问插入方法

数据库效果 刚刚插入的id是6 用6%3=0所以刚刚内条数据插入到了user0表中
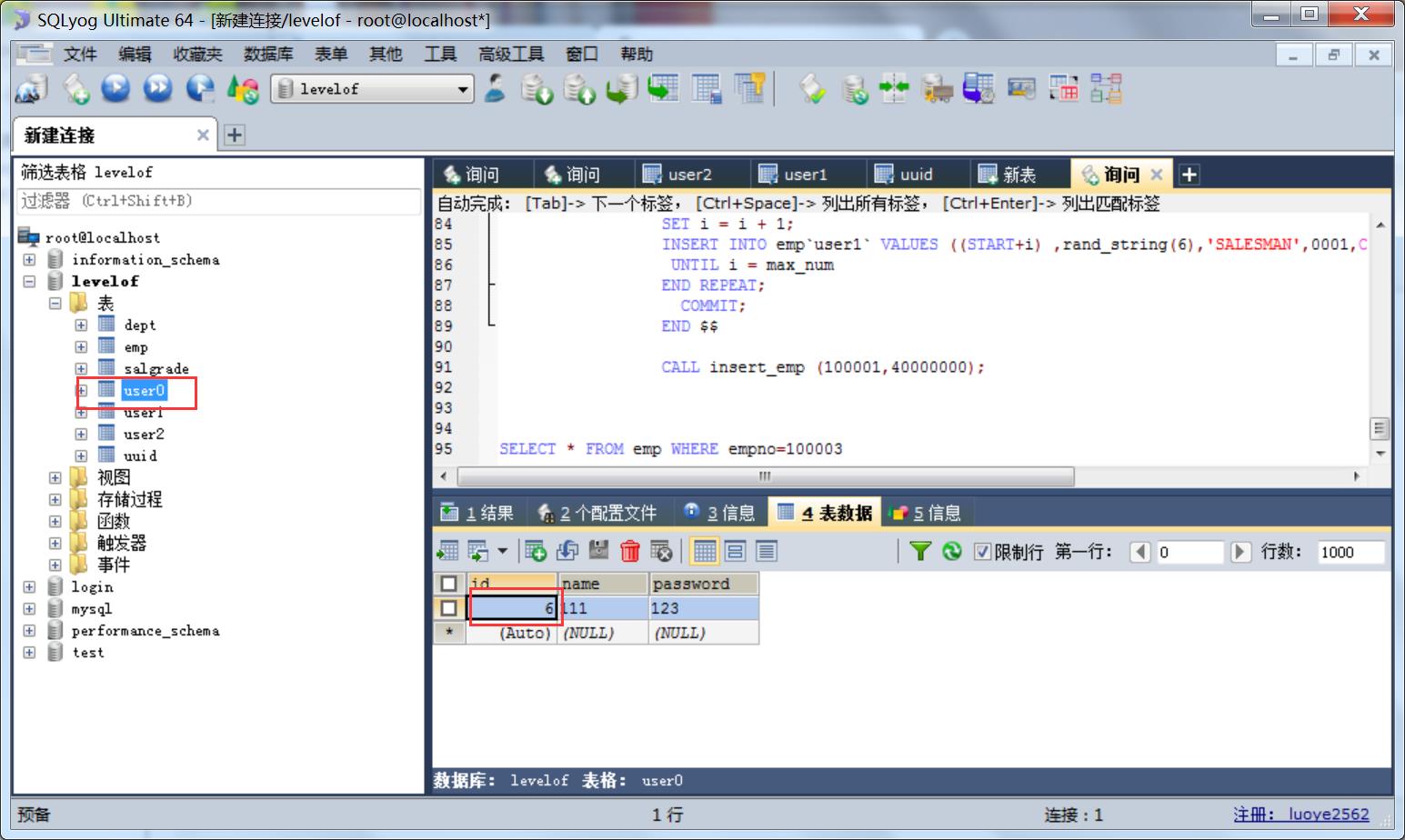
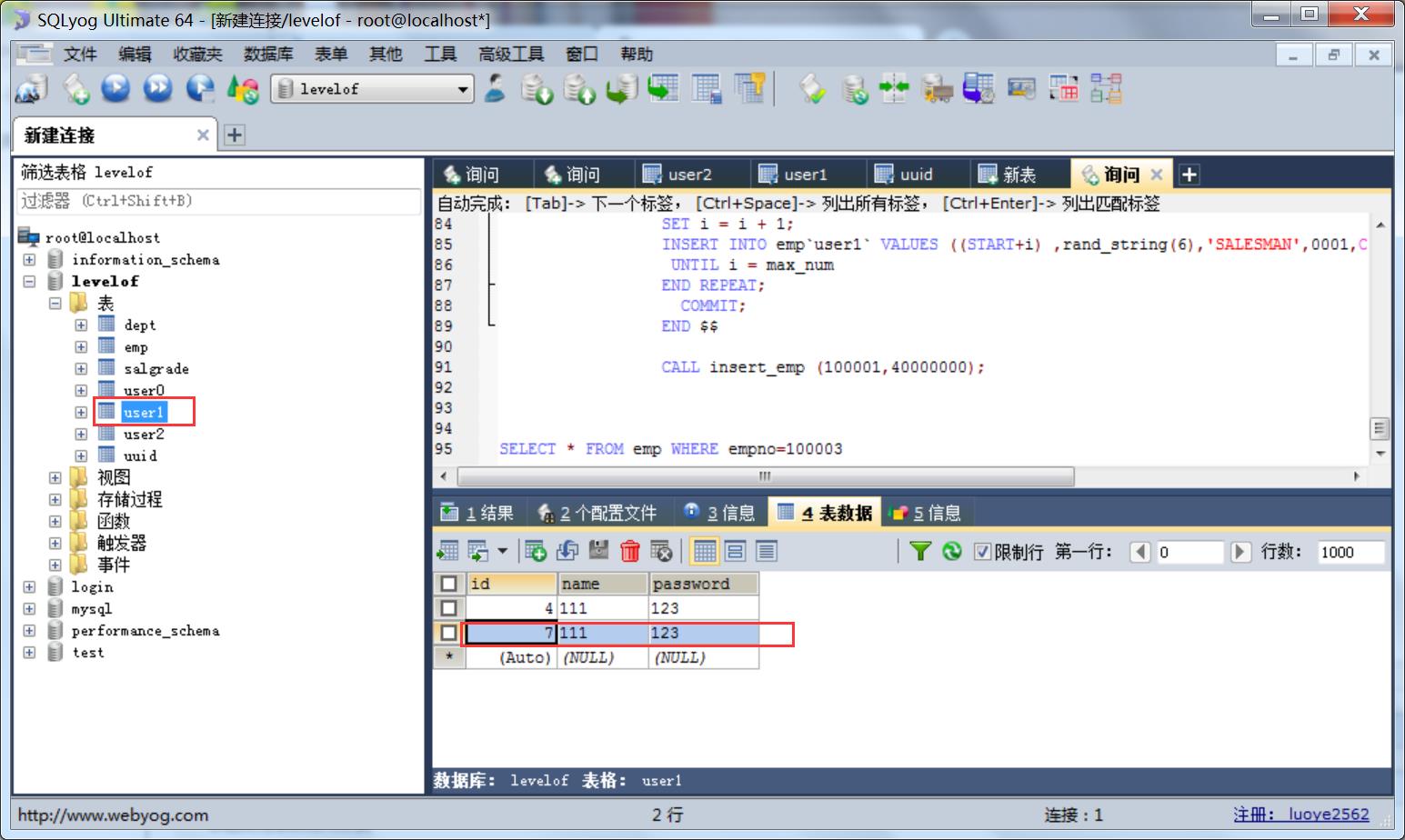
3.6. 现在再向数据库中插入一条数据

数据库效果 刚刚插入数据id为7 所以7%3=1 所以数据插入到表user1中
4. 定位慢查询
4.1

4.2


4.3

4.4

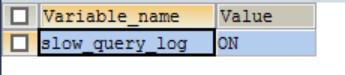
4.5

4.6


4.7 创建表
CREATE TABLE dept( deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ dname VARCHAR(20) NOT NULL DEFAULT "", /*名称*/ loc VARCHAR(13) NOT NULL DEFAULT "" /*地点*/ ) ENGINE=MYISAM DEFAULT CHARSET=utf8 ;
CREATE TABLE emp (empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/ job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/ mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/ hiredate DATE NOT NULL,/*入职时间*/ sal DECIMAL(7,2) NOT NULL,/*薪水*/ comm DECIMAL(7,2) NOT NULL,/*红利*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/ )ENGINE=MYISAM DEFAULT CHARSET=utf8 ;
CREATE TABLE salgrade ( grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, losal DECIMAL(17,2) NOT NULL, hisal DECIMAL(17,2) NOT NULL )ENGINE=MYISAM DEFAULT CHARSET=utf8;
4.8 向表中插入数据
INSERT INTO salgrade VALUES (1,700,1200); INSERT INTO salgrade VALUES (2,1201,1400); INSERT INTO salgrade VALUES (3,1401,2000); INSERT INTO salgrade VALUES (4,2001,3000); INSERT INTO salgrade VALUES (5,3001,9999);
4.9 创建函数
DELIMITER $$ CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255) #该函数会返回一个字符串 BEGIN #chars_str定义一个变量 chars_str,类型是 varchar(100),默认值\'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ\'; DECLARE chars_str VARCHAR(100) DEFAULT \'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ\'; DECLARE return_str VARCHAR(255) DEFAULT \'\'; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1)); SET i = i + 1; END WHILE; RETURN return_str; END $$
DELIMITER $$ CREATE FUNCTION rand_num() RETURNS INT(5) BEGIN DECLARE i INT DEFAULT 0; SET i =FLOOR(10+RAND()*500); RETURN i; END $$
DELIMITER $$ CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10)) BEGIN DECLARE i INT DEFAULT 0; #set autocommit =0 把autocommit设置成0 SET autocommit = 0; REPEAT SET i = i + 1; INSERT INTO emp`user1` VALUES ((START+i) ,rand_string(6),\'SALESMAN\',0001,CURDATE(),2000,400,rand_num()); UNTIL i = max_num END REPEAT; COMMIT; END $$
4.10 执行
CALL insert_emp (100001,40000000);
4.11 执行一条查询语句
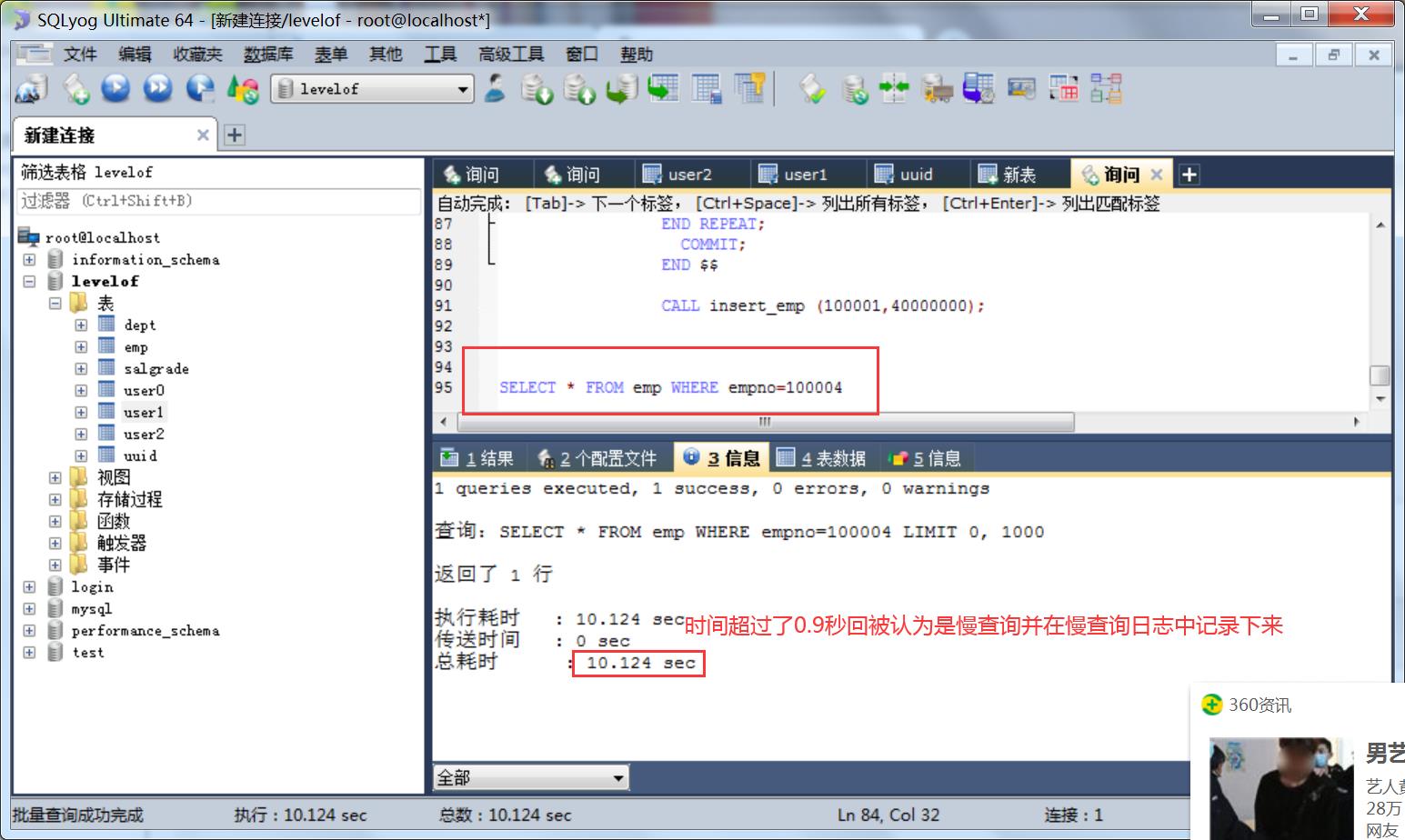
4.12 慢查询日志效果

以上是关于MySQL优化的主要内容,如果未能解决你的问题,请参考以下文章
Android 逆向整体加固脱壳 ( DEX 优化流程分析 | DexPrepare.cpp 中 dvmOptimizeDexFile() 方法分析 | /bin/dexopt 源码分析 )(代码片段