mysql主从复制和读写分离
Mysql主从复制和读写分离
在实际的生产环境中,如果对mysql数据库的读和写都在一台数据库服务器中操作,无论是在安全性、高可用性,还是高并发等各个方面都是不能满足实际需求的。因此,一般通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。
Mysql主从复制和读写分离
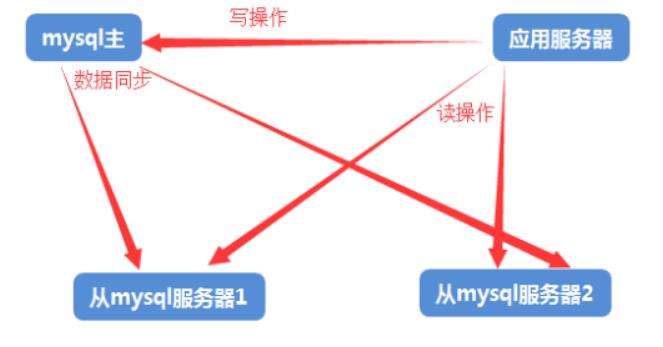
一,主从复制:
Mysql的主从复制和mysql的读写分离两者有紧密的联系,首先要部署主从复制,只有主从复制完成了,才能再此基础上进行数据的读写分离。
Mysql支持的复制类型:
1、 基于语句的复制:在主服务器上执行的sql语句,在从服务器上会执行同样的语句。Mysql默认采用基于语句的复制,效率比较高,但是有时不能实现精准复制。
2, 基于行的复制:把改变的内容复制过去,而不是把命令在从服务器上执行一遍。
3、 混合类型的复制:默认采用基于语句的复制,一旦发现基于语句的复制不能精准复制时,就会采用基于行的复制。
二,主从复制过程:
1、 在每个事物更新数据完成之前,master在二进制日志记录这些改变,写入二进制日志完成后,master通知存储引擎提交事物。
2、 Slave将master的binary log复制到其中的中继日志。首先从mysql服务器开始一个工作线程I/O线程,I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master。他会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
3、Sql从线程处理该过程的最后一步。Sql线程从中继日志中读取事件,并重放其中的事件而更新slave的数据,使其与master的数据一致。
三、读写分离
简单的来说,读写分离就是只在mysql主服务器上写,只在mysql从服务器上读。基本原理是让主数据库处理事务性查询,而从数据库处理select查询。数据库复制被用来把事务性查询导致的变更同步到集群中的数据库。
目前较为常见的mysql读写分离有两种:
1、 基于程序代码的内部实现
在代码中根据select、insert进行路由分类,这类方法也是目前生产环境中较为常用的,优点是性能较好,因为在程序代码中实现,不需要增加额外的设备作为硬件开支;缺点是需要研发人员来实现,运维人员无从下手。
2、 基于中间代理层实现
代理一般位于客户端和服务器之间,代理服务器接收到客户端请求后通过判断后转发到后端数据库。如下有两个常用代理:
Mysql-proxy:其为mysql的开源项目,通过其自带的lua脚本进行sql判断,虽然是mysql官方产品,但是mysql官方并不建议其使用到生产环境中。
Amoeba:由陈思儒开发,该程序由Java语言进行开发。这个软件致力于mysql的分布式数据库前端代理层,它主要为应用层访问mysql的时候充当sql路由功能。Amoeba能够完成多数据源的高可用、负载均衡、数据切片等功能。
常用的mysql连接工具:
phpMyAdmin
phpMyAdmin是我们常用的MySQL管理工具之一,它是用PHP开发的基于Web方式架构在网站主机上的MySQL管理工具,支持中文,管理数据库也十分方便。主要缺点在对大数据库的备份和恢复不是十分方便。
Navicat
Navicat是一款桌面版MySQL管理工具,它和微软的SQLServer的管理器很像,简单易用。Navicat的优势在于使用图形化的用户界面,可以让用户管理更加轻松。