mysql系列--索引
Posted leskang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql系列--索引相关的知识,希望对你有一定的参考价值。
事务
事务,你肯定会想到 ACID(Atomicity、Consistency、Isolation、Durability,即原⼦性、⼀致性、隔离性、持久性)
读未提交:⼀个事务还没提交时,它做的变更就能被别的事务看到。
读提交:⼀个事务提交之后,它做的变更才会被其他事务看到。
可重复读:⼀个事务执⾏过程中看到的数据,总是跟这个事务在启动时看到的数据是⼀致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可⻅的。
串⾏化:顾名思义是对于同⼀⾏记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前⼀个事务执⾏完成,才能继续执⾏。

若隔离级别是“串⾏化”,则在事务 B 执⾏“将 1 改成 2”的时候,会被锁住。直到事务 A 提交后,事务 B 才可以继续执⾏。所以从 A 的⻆度看, V1、V2 值是 1,V3 的值是 2。
总结即一个事物无法操作另一个执行中事物里的变量,被锁住直到事物结束。
oracle默认事物隔离级别为读提交,mysql默认为可重复读
查看数据库事物级别:
mysql:
新版方法:show variables like \'transaction_isolation\'; 或 select @@transaction_isolation;
老版方法:show variables like \'%tx_isolation%\'; 或 select @@tx_isolation;
oracle
首先创建一个事物: declare trans_id Varchar2(100); begin trans_id := dbms_transaction.local_transaction_id( TRUE ); end; 执行sql查询事物隔离级别: SELECT s.sid, s.serial#, CASE BITAND(t.flag, POWER(2, 28)) WHEN 0 THEN \'READ COMMITTED\' ELSE \'SERIALIZABLE\' END AS isolation_level FROM v$transaction t JOIN v$session s ON t.addr = s.taddr AND s.sid = sys_context(\'USERENV\', \'SID\');
可重复读场景举例:
管理一个个人银行账户表。一个表存了每个月月底的余额,一个表存了账单明细。这时候你要做数据校对,也就是判断上个月的余额和当前余额的差额,是否与本月的账单明细一致。你一定希望在校对过程中,即使有用户发生了一笔新的交易,也不影响你的校对结果。
可重复读实现原理:
实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会有类似下面的记录。
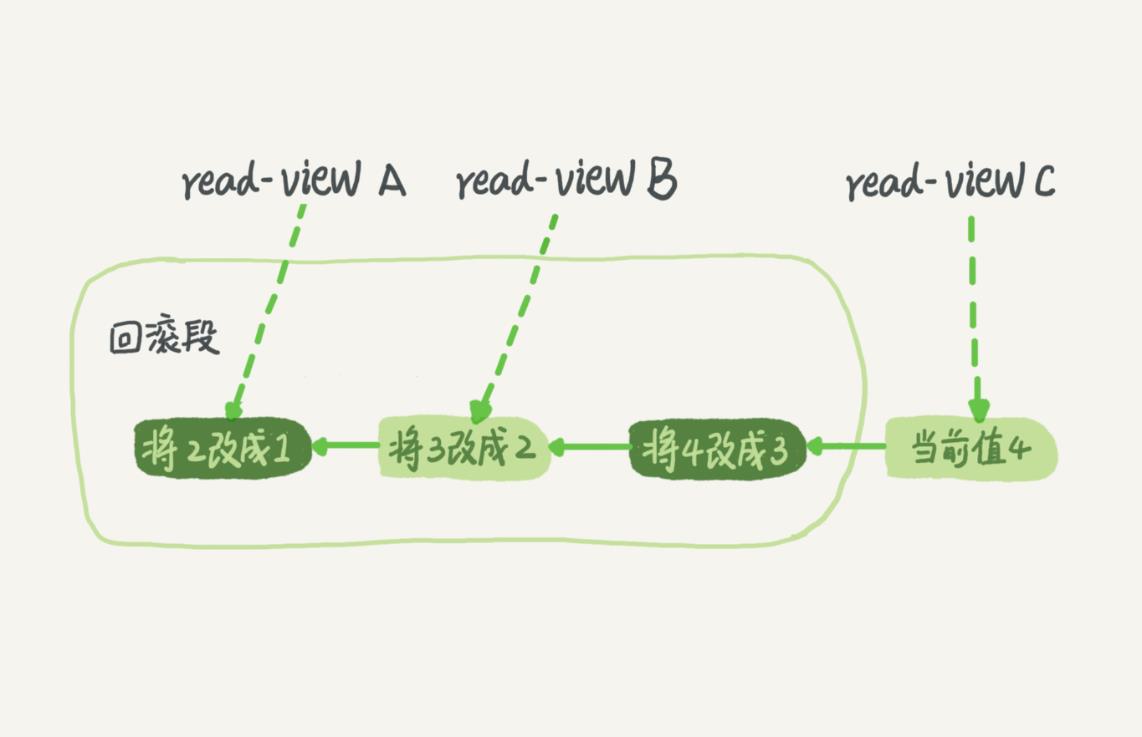
当前值是 4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的 read-view。如图中看到的,在视图 A、B、C 里面,这一个记录的值分别是 1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于 read-view A,要得到 1,就必须将当前值依次执行图中所有的回滚操作得到。
注:当事物无法引用到最早的回滚操作日志时会被删除,注意长事物长时间不释放回导致回滚日志过大。除了对回滚段的影响,长事务还占用锁资源,也可能拖垮整个库
避免长事物:
从应⽤开发端来看:
1. 减少使⽤ set autocommit=0。改为1,通过 general_log 的⽇志可以确认是否使用自动提交。
2. 只读事物多个select不要⽤ begin/commit 框起来。
3. 通过 SET MAX_EXECUTION_TIME 命令,来控制每个语句执⾏的最⻓时间,避免单个语句意外执⾏太⻓时间。
从数据库端来看:
1. 监控 information_schema.Innodb_trx 表,设置⻓事务阈值,超过就报警 / 或者 kill;
2. Percona 的 pt-kill 这个⼯具不错,推荐使⽤;
3. 在业务功能测试阶段要求输出所有的 general_log,分析⽇志⾏为提前发现问题;
4. 如果使⽤的是 MySQL 5.6 或者更新版本,把 innodb_undo_tablespaces 设置成 2(或更⼤的值)。如果真的出现⼤事务导致回滚段过⼤,这样设置后清理起来更⽅便。
begin/start transaction;启动事物
set autocommit=0自动提交关闭
commit提交事物
索引
索引的常⻅模型
1、哈希表
哈希表这种结构适⽤于只有等值查询的场景,⽐如 Memcached 及其他⼀些 NoSQL 引擎。
2、有序数组
有序数组在等值查询和范围查询场景中的性能就都⾮常优秀,不过数据更新元素大量移动,效率低,有序数组索引只适⽤于静态存储引擎,即数据不大会修改的场景。
3、树
二叉树查找效率高,但是一般不使用,索引不止存在内存中,还要写到磁盘上,数据多时数据节点过多,树过高,磁盘寻址多,效率低。
一般使用N叉树,以 InnoDB 的⼀个整数字段索引为例,这个 N 差不多是 1200。这棵树⾼是 4 的时候,就可以存1200 的 3 次⽅个值,这已经 17 亿了
InnoDB 的索引模型
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储⽅式的表称为索引组织表。每⼀个索引在 InnoDB ⾥⾯对应⼀棵 B+ 树。
主键索引和普通索引
根据叶⼦节点的内容,索引类型分为主键索引和⾮主键索引。
主键索引的叶⼦节点存的是整⾏数据。在 InnoDB ⾥,主键索引也被称为聚簇索引(clusteredindex)。
⾮主键索引的叶⼦节点内容是主键的值(MyISAM的索引叶子节点存储记录指针)。在 InnoDB ⾥,⾮主键索引也被称为⼆级索引(secondary index)。
补充:
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
如果语句是 select * from T where ID=500,即主键查询⽅式,则只需要搜索 ID 这棵 B+树;
如果语句是 select * from T where k=5,即普通索引查询⽅式,则需要先搜索 k 索引树,得
到 ID 的值为 500,再到 ID 索引树搜索⼀次。这个过程称为回表
基于⾮主键索引的查询需要多扫描⼀棵索引树。因此,我们在应⽤中应该尽量使⽤主键查询。
B+树的叶子节点是page (页),一个页里面可以存多个行
主键bigint unsigned,无符号
B+树索引一个节点上数据顺序存储,中间插入数据后面的元素需要后移,若数据页已满则需要新建页并将部分数据移动到新页上,称为页分裂,除了性能外,⻚分裂操作还影响数据⻚的利⽤率。原本放在⼀个⻚的数据,现在分到两个⻚中,整体空间利⽤率降低⼤约 50%。
当然有分裂就有合并。当相邻两个⻚由于删除了数据,利⽤率很低之后,会将数据⻚做合并。合并的过程,可以认为是分裂过程的逆过程。
自增主键每次插⼊⼀条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶⼦节点的分裂。
有业务逻辑的字段做主键,则往往不容易保证有序插⼊,这样写数据成本相对较⾼。
注意主键一般不使用长字段,主键⻓度越⼩,普通索引的叶⼦节点就越⼩,普通索引占⽤的空间也就越⼩。
不合适自增主键的场景:k-v键值对的场景,如nosql
select * from T where k between 3 and 5

语句执行过程:
1. 在 k 索引树上找到 k=3 的记录,取得 ID = 300;
2. 再到 ID 索引树查到 ID=300 对应的 R3;
3. 在 k 索引树取下⼀个值 k=5,取得 ID=500;
4. 再回到 ID 索引树查到 ID=500 对应的 R4;
5. 在 k 索引树取下⼀个值 k=6,不满⾜条件,循环结束。
即:普通索引查询先找到索引对应的主键值再到主键索引找具体的数据,索引顺序查找,知道找到不满足条件的终止查找。
在这个过程中,回到主键索引树搜索的过程,我们称为回表。可以看到,这个查询过程读了 k 索引树的 3 条记录(步骤 1、3 和 5),回表了两次(步骤 2 和 4)。
避免回表
覆盖索引
select ID from T where k between 3 and 5,只查询id,id就在普通索引上,无需回表,索引K“覆盖”了我们的查询需求,称为覆盖索引
最左前缀
联合索引先按照第一个字段顺序排列,再排列第二个字段,查询若字段顺序放反达不到索引效果
索引下推
select * from tuser where name like \'张 %\' and age=10 and ismale=1;
在 MySQL 5.6 之前,只能从第一张对应的 ID3 开始⼀个个回表。到主键索引上找出数据⾏,再对⽐字段值。
⽽ MySQL 5.6 引⼊的索引下推优化(index condition pushdown), 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满⾜条件的记录,减少回表次数。
即:若查询字段在索引中,会先按照条件筛选索引字段,再拿筛选后的结果去对比数据库数据找出无索引字段。
mysql官网:explain的输出结果Extra字段为Using index时,能够触发索引覆盖
细节:
索引只能定位到page,page内部怎么去定位行数据?内部有个有序数组,二分法
二级索引重建应该新建索引再做删除,如果有查询用到这个索引,此时索引已被删除,会导致业务抖动.
主键重建不能采用drop这种方式去按操作,因为所有数据都是以主键组织的,删了主键后,InnoDB会自己找一个主键组织数据,再次添加主键又会重新组织数据,重建表的次已达二次,我们可以直接Optimiz这个表
问题:如果插入的数据是在主键树叶子结点的中间,后面的所有页如果都是满的状态,是不是会造成后面的每一页都会去进行页分裂操作,直到最后一个页申请新页移过去最后一个值?
回答:不会,只会分裂它要写入的那个页面。每个页面之间是用指针串的,改指针就好了,不需要“后面的全部挪动
主键索引更改:
1. 直接删掉主键索引是不好的,它会使得所有的二级索引都失效,并且会用ROWID来作主键索引;
2. 看到mysql官方文档写了三种措施,第一个是整个数据库迁移,先dump出来再重建表(这个一般只适合离线的业务来做);
第二个是用空的alter操作,比如ALTER TABLE t1 ENGINE = InnoDB;这样子就会原地重建表结构;
第三个是用repaire table,不过这个是由存储引擎决定支不支持的(innodb就不行)。
数据删除索引还在,占用的空间不会释放,可通过ALTER TABLE t1 ENGINE = InnoDB;重建索引
问题:非聚集索引上为啥叶子节点的value为什么不是地址,这样可以直接定位到整条数据,而不用再次对整棵树进行查询?
回答:这个叫作“堆组织表”,MyISAM就是这样的,各有利弊。你想一下如果修改了数据的位置的情况,InnoDB这种模式是不是就方便些
未走索引全表扫描的是主键索引树
非叶子节点存储大约 1200个:整型4个字节,加上辅助数据差不多每个key占13字节,16k/13
表的逻辑结构 ,表 —> 段 —> 段中存在数据段(leaf node segment) /索引段( Non-leaf node segment),数据段就是主键索引的数据, 索引段就是二级索引的数据
每次新增数据每个索引都要相应增加对应值,故索引越多维护成本越高
查询数据的时候,大致的流程细化来说 , 通过执行器调用存储引擎,到表里的数据段/索引段取数据 ,数据是按照段->区->页维度去取 , 取完后先放到数据缓冲池中,再通过二分法查询叶结点的有序链表数组找到行数据返回给用户 。 当数据量大的时候,会存在不同的区,取范围值的时候会到不同的区取页的数据返回用户。
like \'j\' 或 \'j%\' 可以使用索引,并且快速定位记录。
like \'%j\' 或 \'%j%\',只是在二级索引树上遍历查找记录,并不能快速定位(扫描了整棵索引树)。
覆盖索引要覆盖查询字段和where条件字段
小惊喜
1、积少成多,下载高佣联盟,领取各大平台隐藏优惠券,每次购物省个十块八块不香吗,通过下方二维码注册的用户可添加微信liershuang123(微信号)领取价值千元海量学习视频。
为表诚意奉献部分资料:
软件电子书:链接:https://pan.baidu.com/s/1_cUtPtZZbtYTF7C_jwtxwQ 提取码:8ayn
架构师二期:链接:https://pan.baidu.com/s/1yMhDFVeGpTO8KTuRRL4ZsA 提取码:ui5v
架构师阶段课程:链接:https://pan.baidu.com/s/16xf1qVhoxQJVT_jL73gc3A 提取码:2k6j


2、本人重金购买付费前后端分离脚手架源码一套,现10元出售,加微信liershuang123获取源码


以上是关于mysql系列--索引的主要内容,如果未能解决你的问题,请参考以下文章