透彻理解redis
Posted 一支会记忆的笔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了透彻理解redis相关的知识,希望对你有一定的参考价值。
前言......

Redis 作为一个开源的,高级的键值存储和一个适用的解决方案,已经越来越在构建 「高性能」、「可扩展」 的 Web 应用上发挥着举足轻重的作用。
当今互联网技术架构中 Redis 已然成为了应用得最广泛的中间件之一,它也是中高级后端工程 技术面试 中面试官最喜欢问的工程技能之一,
不仅仅要求着我们对 基本的使用 进行掌握,更要深层次地理解 Redis 内部实现 的细节原理。
什么是 Redis ?
Redis (Remote Dictionary Server) 是一个使用 C 语言 编写的,开源的 (BSD许可) 高性能 非关系型 (NoSQL) 的 键值对数据库。
简单提一下 Redis 数据结构
Redis 可以存储 键 和 不同类型数据结构值 之间的映射关系。键的类型只能是字符串,而值除了支持最 基础的五种数据类型 外,还支持一些 高级数据类型
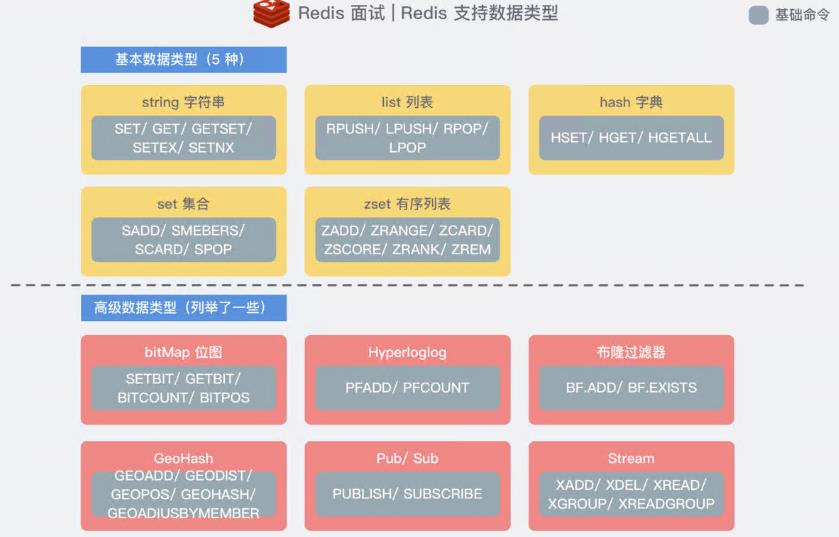
Redis 小总结
与传统数据库不同的是 Redis 的数据是 存在内存 中的,所以 读写速度 非常 快,因此 Redis 被广泛应用于 缓存 方向,每秒可以处理超过 10 万次读写操作,
是已知性能最快的 Key-Value 数据库。另外,Redis 也经常用来做 分布式锁。除此之外,Redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
Redis 应用场景
-
缓存
-
共享Session
-
消息队列系统
-
分布式锁
Redis 优缺点
优点
读写性能优异, Redis能读的速度是 110000 次/s,写的速度是 81000 次/s。 支持数据持久化,支持 AOF 和 RDB 两种持久化方式。 支持事务,Redis 的所有操作都是原子性的,同时 Redis 还支持对几个操作合并后的原子性执行。 数据结构丰富,除了支持 string 类型的 value 外还支持 hash、set、zset、list 等数据结构。 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
数据库 容量受到物理内存的限制,不能用作海量数据的高性能读写,因此 Redis 适合的场景主要局限在较小数据量的高性能操作和运算上。
Redis 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的 IP 才能恢复。
主机宕机,宕机前有部分数据未能及时同步到从机,切换 IP 后还会引入数据不一致的问题,降低了 系统的可用性。
Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费
为什么要用缓存?为什么使用 Redis?
提一下现在 Web 应用的现状
在日常的 Web 应用对数据库的访问中,读操作的次数远超写操作,比例大概在 1:9 到 3:7,所以需要读的可能性是比写的可能大得多的。
频繁读写数据
当我们使用 SQL 语句去数据库进行读写操作时,数据库就会 去磁盘把对应的数据索引取回来,这是一个相对较慢的过程。
直接操作数据库不安全
使用 Redis or 使用缓存带来的优势
如果我们把数据放在 Redis 中,也就是直接放在内存之中,让服务端直接去读取内存中的数据,那么这样 速度 明显就会快上不少 (高性能),并且会 极大减小数据库的压力 (特别是在高并发情况下)。
记得是 两个角度 啊.. 高性能 和 高并发..
使用缓存会出现什么问题?
一般来说有如下几个问题,回答思路遵照 是什么 → 为什么 → 怎么解决:
缓存雪崩问题;
缓存穿透问题;
缓存和数据库双写一致性问题;
缓存雪崩问题
同一时间大量的缓存失效导致同一时刻大量的请求全部访问数据库 造成宕机
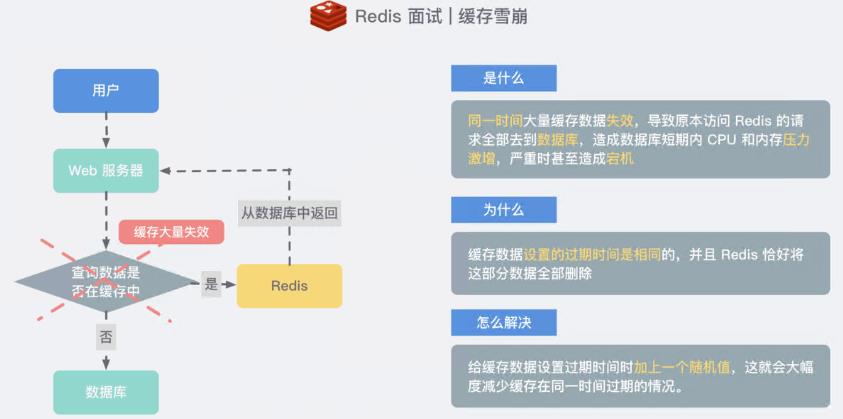
另外对于 "Redis 挂掉了,请求全部走数据库" 这样的情况,我们还可以有如下的思路:
- 事发前:实现 Redis 的高可用(主从架构 + Sentinel 或者 Redis Cluster),尽量避免 Redis 挂掉这种情况发生。
- 事发中:万一 Redis 真的挂了,我们可以设置本地缓存(ehcache) + 限流(hystrix),尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的)
- 事发后:Redis 持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
缓存穿透问题
当大量请求访问一个根本就不存在的数据如id为负数 此时就会直接访问数据库 造成数据库压力很大 导致宕机

缓存击穿问题
就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况,当这个 key 在缓存中失效的瞬间 大量用户同时访问一个数据时 导致大量请求直接走数据库 造成数据库服务宕机
缓存与数据库双写一致问题
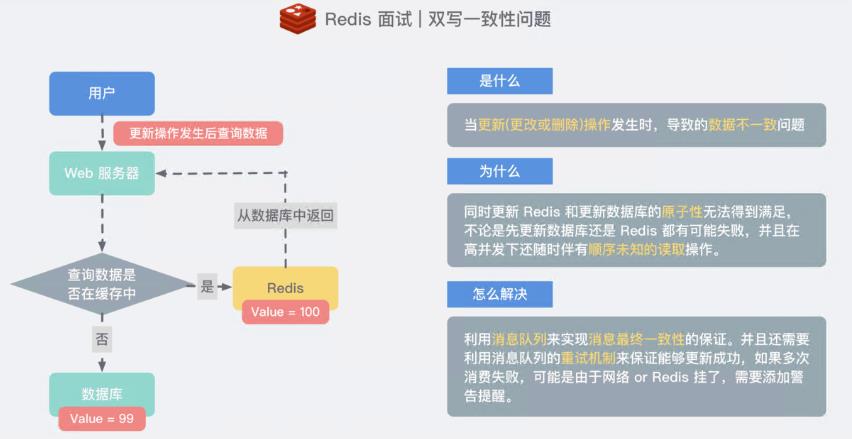
双写一致性上图还是稍微粗糙了些,你还需要知道两种方案 (先操作数据库和先操作缓存) 分别都有什么优势和对应的问题,这里不作赘述,可以参考一下下方的文章,写得非常详细。
- 面试前必须要知道的Redis面试题 | Java3y - https://mp.weixin.qq.com/s/3Fmv7h5p2QDtLxc9n1dp5A
Redis 为什么早期版本选择单线程?
因为 Redis 是基于内存的操作,CPU 不是 Redis 的瓶颈,Redis 的瓶颈最有可能是 机器内存的大小 或者 网络带宽。既然单线程容易实现,而且 CPU 不会成为瓶颈,那就顺理成章地采用单线程的方案了。
简单总结一下
- 使用单线程模型能带来更好的 可维护性,方便开发和调试;
- 使用单线程模型也能 并发 的处理客户端的请求;(I/O 多路复用机制)
- Redis 服务中运行的绝大多数操作的 性能瓶颈都不是 CPU;
强烈推荐 各位亲看一下这篇文章:
- 为什么 Redis 选择单线程模型 · Why\'s THE Design? - https://draveness.me/whys-the-design-redis-single-thread
Redis 为什么这么快?
简单总结:
- 纯内存操作:读取不需要进行磁盘 I/O,所以比传统数据库要快上不少;(但不要有误区说磁盘就一定慢,例如 Kafka 就是使用磁盘顺序读取但仍然较快)
- 单线程,无锁竞争:这保证了没有线程的上下文切换,不会因为多线程的一些操作而降低性能;
- 多路 I/O 复用模型,非阻塞 I/O:采用多路 I/O 复用技术可以让单个线程高效的处理多个网络连接请求(尽量减少网络 IO 的时间消耗);
- 高效的数据结构,加上底层做了大量优化:Redis 对于底层的数据结构和内存占用做了大量的优化,例如不同长度的字符串使用不同的结构体表示,HyperLogLog 的密集型存储结构等等..
Redis的持久化
Redis持久化

什么是持久化
Redis 的数据 全部存储 在 内存 中,如果 突然宕机,数据就会全部丢失,因此必须有一套机制来保证 Redis 的数据不会因为故障而丢失,
这种机制就是 Redis 的 持久化机制,它会将内存中的数据库状态 保存到磁盘 中。
Redis持久化的两种方式:
方式一:RDB
RDB 在指定的时间间隔内将内存中的数据集以快照的方式写入磁盘

快照不是很持久。如果运行 Redis 的计算机停止运行,电源线出现故障或者发生意外,则写入 Redis 的最新数据将丢失
方式二:AOF
AOF 以日志的形式记录数据写入到磁盘(文件追加的方式写入磁盘)

RDB和AOF的区别:
RDB | 优点
- 只有一个文件
dump.rdb,方便持久化。 - 容灾性好,一个文件可以保存到安全的磁盘。
- 性能最大化,
fork子进程来完成写操作,让主进程继续处理命令,所以使 IO 最大化。使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 Redis 的高性能 - 相对于数据集大时,比 AOF 的 启动效率 更高。
RDB | 缺点
- 数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 Redis 发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候;
AOF | 优点
- 数据安全,aof 持久化可以配置
appendfsync属性,有always,每进行一次命令操作就记录到 aof 文件中一次。 - 通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据一致性问题。
- AOF 机制的 rewrite 模式。AOF 文件没被 rewrite 之前(文件过大时会对命令 进行合并重写),可以删除其中的某些命令(比如误操作的 flushall)
AOF | 缺点
- AOF 文件比 RDB 文件大,且 恢复速度慢。
- 数据集大 的时候,比 rdb 启动效率低。
Redis的 集群

Redis集群
主从同步的了解
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称为 主节点(master),后者称为 从节点(slave)。且数据的复制是 单向 的,只能由主节点到从节点。Redis 主从复制支持 主从同步 和 从从同步 两种,后者是 Redis 后续版本新增的功能,以减轻主节点的同步负担。
主从复制主要的作用
- 数据冗余: 主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复: 当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复 (实际上是一种服务的冗余)。
- 负载均衡: 在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写 Redis 数据时应用连接主节点,读 Redis 数据时应用连接从节点),分担服务器负载。尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高 Redis 服务器的并发量。
- 高可用基石: 除了上述作用以外,主从复制还是哨兵和集群能够实施的 基础,因此说主从复制是 Redis 高可用的基础。
实现原理:
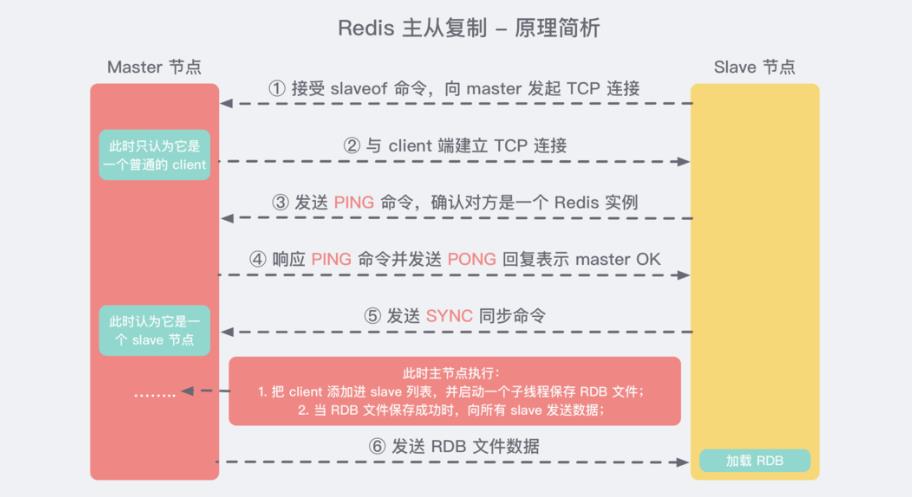
简化成三个阶段:准备阶段-----------数据同步阶段-------------命令传播阶段。
Redis如何实现分布式锁
推荐阅读 之前的系列文章: Redis(3)——分布式锁深入探究 -传送门
Redis过期健的删除策略
简单描述
先抛开 Redis 想一下几种可能的删除策略:
- 定时删除:在设置键的过期时间的同时,创建一个定时器 timer). 让定时器在键的过期时间来临时,立即执行对键的删除操作。
- 惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。
- 定期删除:每隔一段时间程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定。
在上述的三种策略中定时删除和定期删除属于不同时间粒度的 主动删除,惰性删除属于 被动删除。
三种策略都有各自的优缺点
- 定时删除对内存使用率有优势,但是对 CPU 不友好;
- 惰性删除对内存不友好,如果某些键值对一直不被使用,那么会造成一定量的内存浪费;
- 定期删除是定时删除和惰性删除的折中。
Redis 中的实现
Reids 采用的是 惰性删除和定时删除 的结合,一般来说可以借助最小堆来实现定时器,不过 Redis 的设计考虑到时间事件的有限种类和数量,使用了无序链表存储时间事件,这样如果在此基础上实现定时删除,就意味着 O(N) 遍历获取最近需要删除的数据
参考资料:
- 3w字深度好文|Redis面试全攻略,读完这个就可以和面试官大战几个回合了 - https://mp.weixin.qq.com/s/f9N13fnyTtnu2D5sKZiu9w
- 大厂面试!我和面试官之间关于Redis的一场对弈! - [https://mp.weixin.qq.com/s/DHTPSfmWTZpdTmlytzLz1g](https://mp.weixin.qq.com/s/DHTPSfmWTZpdTmlytzLz1g
- Redis面试题(2020最新版) - https://blog.csdn.net/ThinkWon/article/details/103522351
来源于---->传送门https://www.cnblogs.com/wmyskxz/p/12568926.html#_label4_0
以上是关于透彻理解redis的主要内容,如果未能解决你的问题,请参考以下文章