MongoDB设计模式
Posted liekkas01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB设计模式相关的知识,希望对你有一定的参考价值。
介绍列转行、版本字段、近似计算、预聚合四个文档设计模式和它们的应用场景。
列转行
以存储电影信息的文档为例,因为各个国家的首映时间不同,我们的最简单的想法可能为了统计方便,会每增加一个上映地点,就增加一个统计字段,然后再给这个字段建一个索引。这样统计查询的速度是快了,但是系统写入的效率却下降了。

利用mongdb的特色,将多列数据转换为多行数组。字段数变少,只需要建立由两个字段的组合索引即可。解决了要管理不同国家的上映日期,也使用了单索引快速检索数据。避免使用过多索引造成的性能影响。


版本字段
文档模型的优势就是可以灵活的组织数据,但是面临的问题,就是到底什么时候对文档进行了更改,无法直观的看出来。通过增加版本字段。这样就可以直观看出来,当前文档是什么版本,当前这个版本的文档与上一个版本有什么区分,在不同版本上创建json schema。


近似计算
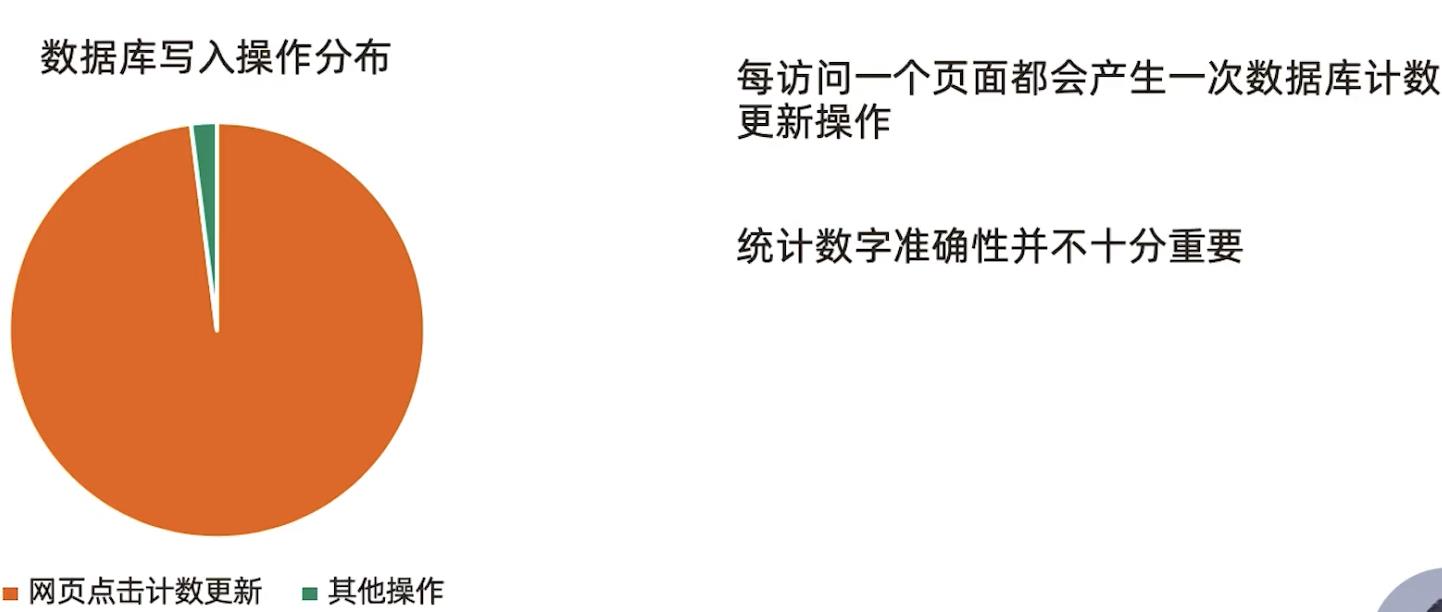
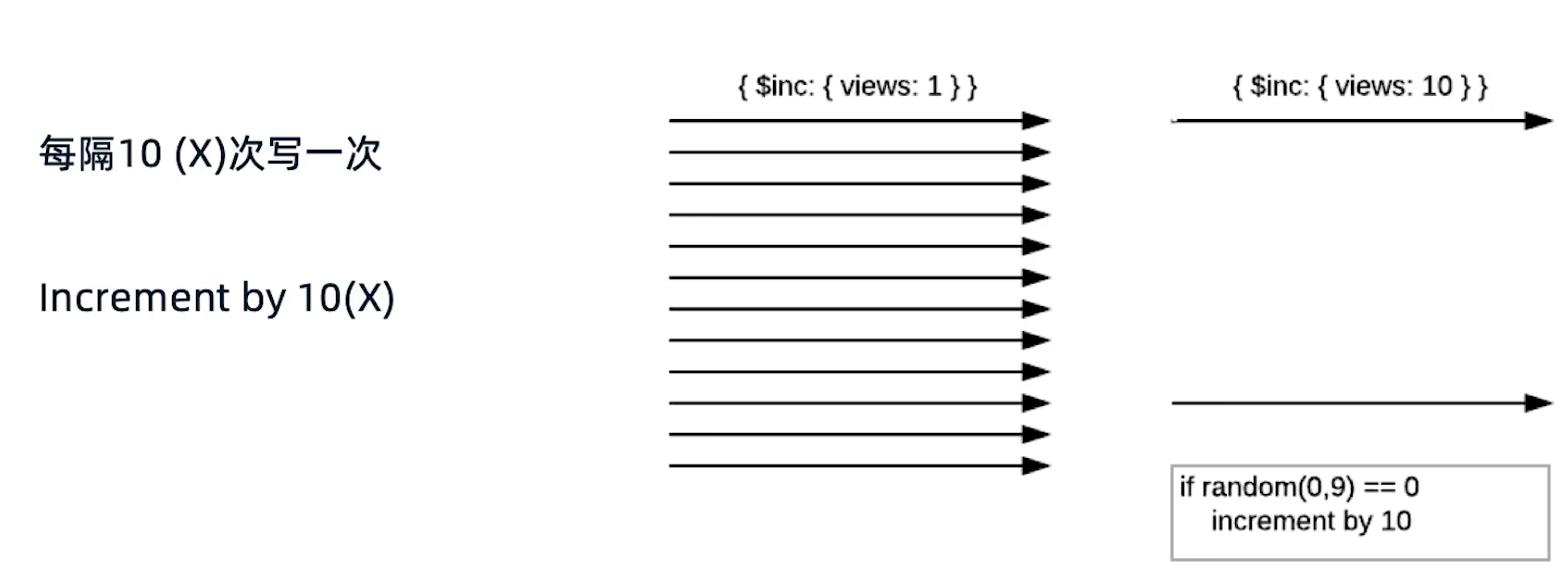
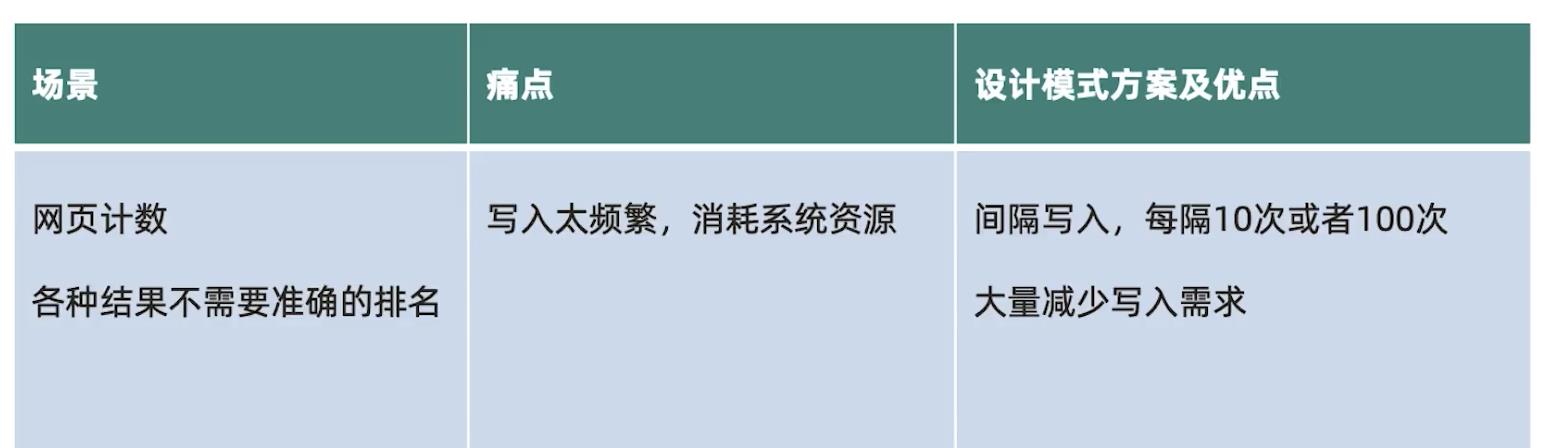
要对一个页面的点击量进行统计,页面每点击一次,就更新一下统计数据,但通常我们的统计并不是要求非常精确的。这样造成的问题就是,系统大部分压力都产生在更新点击数量上了。使用近似计算,原来每点击一次就更新一下,调整为每隔N次,比如10次更新一下数据。
预聚合
对于销售业绩,游戏排名这样的要求统计精确的数据,我们基本就是通过聚合计算来进行数据的汇总。但这样造成的问题就是每次统计都会造成系统计算压力过大。

将统计分解到文档中,也就是给文档预置统计字段,每次更新都更新一下统计数据,减少集中统计时候的系统压力。


以上是关于MongoDB设计模式的主要内容,如果未能解决你的问题,请参考以下文章