MongoDB查询
Posted coisini
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB查询相关的知识,希望对你有一定的参考价值。
一、MongoDB查询文档
1.MongoDB 查询文档使用 find() 方法。
find() 方法以非结构化的方式来显示所有文档。 语法MongoDB 查询数据的语法格式如下:
db.collection.find(query, projection)
query :可选,使用查询操作符指定查询条件
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可 (默认省略)。
2. 实例:

3.如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
>db.col.find().pretty()
pretty() 方法以格式化的方式来显示所有文档。
4.实例:

二、MongoDB 与 RDBMS Where 语句比较
如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:

1.MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件
语法:
>db.col.find({key1:value1, key2:value2}).pretty()
实例:

以上实例中类似于 WHERE 语句:WHERE name=\'wan\' AND age=\'18\'
2.MongoDB OR 条件MongoDB OR 条件语句使用了关键字 $or,
语法格式如下:
>db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
实例:

3.AND 和 OR 联合使用
实例:
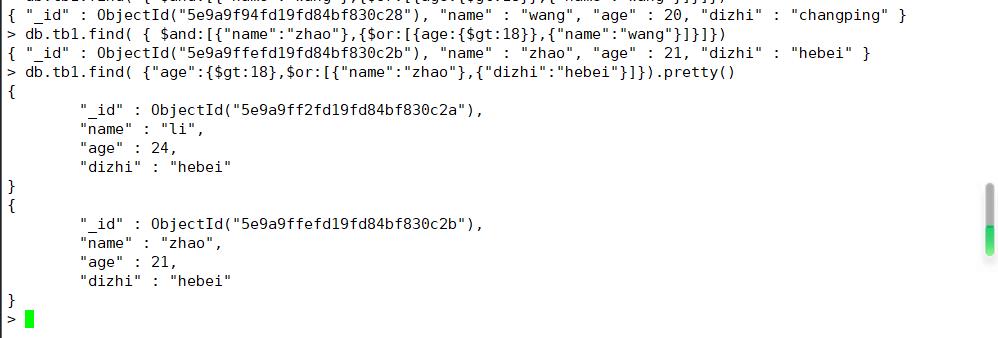
两种方式 都可以
三、MongoDB 排序
1. MongoDB sort() 方法
在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来 指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
语法:
>db.COLLECTION_NAME.find().sort({KEY:1})
实例:

四:MongoDB 索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选 取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对 网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进 行排序的一种结构
1. createIndex() 方法
MongoDB使用 createIndex() 方法来创建索引。
注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(),之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。
1.语法:
>db.collection.createIndex(keys, options)
语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可
2.实例:
先查询数据看搜索时间花费多久
db.tb2.find({age:6666}).explain(true)
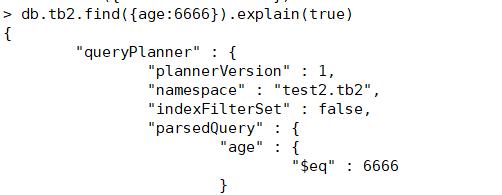
搜索时间:"executionTimeMillis" : 30,

绑定索引:
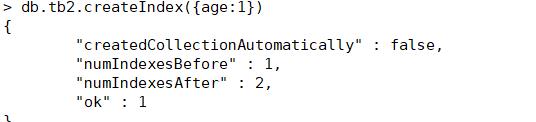
查看索引:

再次搜索
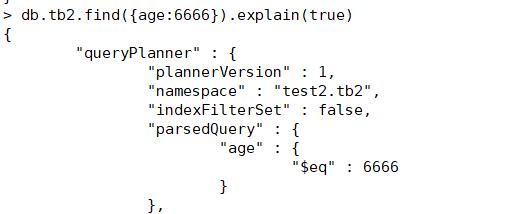
createIndex() 方法中你也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)。
>db.col.createIndex({"title":1,"description":-1})
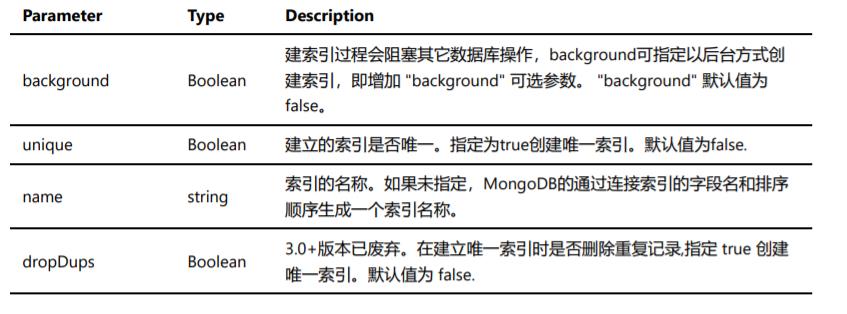
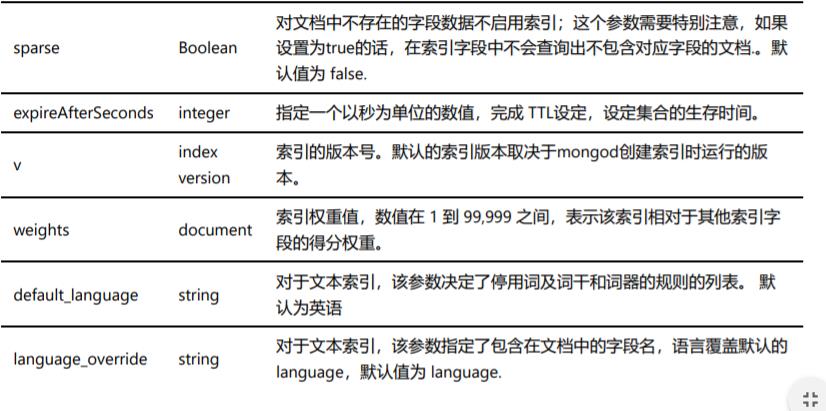
createIndex() 接收可选参数,可选参数列表如下:
在后台创建索引:
db.values.createIndex({open: 1, close: 1}, {background: true})
通过在创建索引时加 background:true 的选项,让创建工作在后台执行
五、 MongoDB聚合
MongoDB 聚合 MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似 sql语句中的 count(*)。
1.aggregate() 方法 MongoDB中聚合的方法使用aggregate()。
语法:
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
实例:
在我们通过以上集合计算每个作者所写的文章数,使用aggregate()计算结果如下:
db.mycol.aggregate(
[
{
$group:{_id:"$by_user",num_tutorial:{$sum:1}}
}
]
)

下表展示了一些聚合的表达式:

六、 管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以 重复的。
表达式:处理输入文档并输出。
表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文 档。
这里我们介绍一下聚合框架中常用的几个操作:
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文 档。
db.account.aggregate( [ { $project:{ _id:0, balance:1, clientName:"$name.firstname" } } ] )
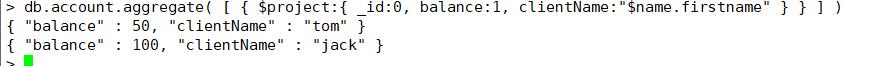
没有数据则报null

$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
db.account.aggregate( [ { $match:{"name.firstname":"jack"} } ] )

$limit:用来限制MongoDB聚合管道返回的文档数。

$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。

$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
$group:将集合中的文档分组,可用于统计结果。
$sort:将输入文档排序后输出。
$geoNear:输出接近某一地理位置的有序文档。
七、索引查询
查看索引
db.tt10.getIndexes()
删除索引
db.tt10.dropIndex("age_1")
分析查询
db.tt10.find({age:66666}).explain(true)
db.tt10.find({age:66666}).explain(true).executionStats.totalDocsExamined
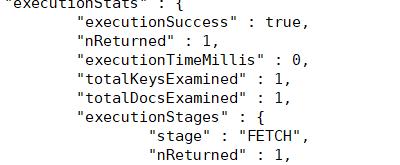
executionStats" : {
"executionSuccess" : true,
"nReturned" : 1,
"executionTimeMillis" : 0, ***执行时间
"totalKeysExamined" : 1, ***
"totalDocsExamined" : 1, ***扫描个数
"executionStages" : {
以上是关于MongoDB查询的主要内容,如果未能解决你的问题,请参考以下文章