MySQL MHA架构
Posted missyou_shiyh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL MHA架构相关的知识,希望对你有一定的参考价值。
MHA
MHA目前在mysql高可用方案中应该也是比较成熟和常见的方案,它由日本人开发出来,在MySQL故障切换过程中,MHA 能做到快速自动切换操作,而且还能最大限度保持数据的一致性,该架构采用 perl 语言编写,可完成秒级别的主库故障切换。
MHA架构
MHA服务有两种角色:MHA Manager(管理节点)和 MHA Node(数据节点)。
- MHA Manager,通常单独部署在一台独立机器上管理多个master/slave集群,每个 master/slave集群称作一个application。MHA Manager用来管理统筹整个集群。
- MHA node,运行在MySQL服务器和manager节点上,它通过监控具备解析和清理logs 功能的脚本来加快故障转移。主要是接收管理节点所发出指令的代理,代理需要运行在每一个MySQL节点上。简单来讲,node就是用来收集从节点服务器上所生成的bin-log。对比打算提升为新的主节点之上的从节点的是否拥有并完成操作,如果没有发给新主节点在本地应用后提升为主节点。
MHA 架构中,manager 会定时探测集群中的主库节点,一般为每秒钟探测一次,当主库出现故障后,拉取主库和最新从库的差异日志并应用到该从库上,将该从库提升为新的主库,然后把其他所有的从库重新指向新的主库,由于主库采取 VIP 方式对外提供服务,整个故障转移的过程对应用程序是完全透明的。
为最大程度的保证数据一致性,对于核心业务的数据库参数 sync_binlog、innodb_flush_log_at_trx_commit 均设置为1,每次主库事物提交后都立即写入binlog,并且立即将缓存中的redo日志写到日志文件,并调用操作系统fsync刷新IO缓存。主从同步上采用半同步复制,主库的每个事物需要等待从库返回响应后再对外宣布成功,最大程度的保证数据的一致性。

MHA架构的主要特点如下所示:
- 安装布署简单,不影响现有架构
- 自动监控和故障转移
- 保障数据一致性
- 故障切换方式可使用手动或自动多向选择
- 适应范围大(适用任何存储引擎)
MHA原理
MHA 架构的工作原理主要步骤如下所示。
- manager 确认主库宕机后,触发 master_ip_failover 脚本,摘除 VIP。
- manager 识别最新的从库(同步主库数据最多的 slave1) binlog 的位置。
- manager 把主库和最新从库的差异 binlog 保存到 manager 本地。
- manager 将本地保存的差异 binlog 复制到最新从库上,并进行应用,应用完成后,将原主库的 VIP 设置到该从库上,提升该从库为新的主库。
- 将其他所有从库指向新的主库。
MHA安装部署
环境说明
主机名 | IP地址 | 用途 |
mysqldb01 | 192.168.56.131 | MySQL的主 |
mysqldb02 | 192.168.56.132 | MySQL的从1 |
mysqldb03 | 192.168.56.133 | MySQL的从2 |
mysqldb05 | 192.168.56.135 | MHA manager节点 |
192.168.56.100 | VIP,业务连接使用 |
搭建一主多从环境
搭建一套一主多从的环境,可以使用传统的方式,也可以使用GTID方式,本文中使用了传统方式,如下内容为各节点my.cnf的配置信息。
MASTER:
[root@mysqldb01 ~]# more /etc/my.cnf [mysqld] port = 3306 socket = /data/mysql/mysql.sock basedir = /usr/local/mysql datadir = /data/mysql user = mysql symbolic_links = 0 character_set_server = latin1 autocommit = off transaction_isolation = READ-COMMITTED
server-id = 1
## Master setting log_bin = /data/mysql/logs/binlog log_bin_index = /data/mysql/logs/binlog.index
## Slave setting relay_log = /data/mysql/logs/relay-log relay_log_index = /data/mysql/logs/relay-log.index master_info_repository=TABLE relay_log_info_repository=TABLE log_slave_updates = on relay_log_recovery = on relay_log_purge= off
[mysqld_safe] log_error = /var/log/mysqld.log
[client] socket = /data/mysql/mysql.sock default_character_set = latin1 prompt="\\\\u@\\\\h [\\\\d]>" [root@mysqldb01 ~]# |
SLAVE1:
[root@mysqldb02 ~]# more /etc/my.cnf [mysqld] port = 3306 socket = /data/mysql/mysql.sock basedir = /usr/local/mysql datadir = /data/mysql user = mysql symbolic_links = 0 character_set_server = latin1 autocommit = off transaction_isolation = READ-COMMITTED
server-id = 2
## Master setting log_bin = /data/mysql/logs/binlog log_bin_index = /data/mysql/logs/binlog.index
## Slave setting relay_log = /data/mysql/logs/relay-log relay_log_index = /data/mysql/logs/relay-log.index master_info_repository=TABLE relay_log_info_repository=TABLE log_slave_updates = on relay_log_recovery = on relay_log_purge= off
[mysqld_safe] log_error = /var/log/mysqld.log
[client] socket = /data/mysql/mysql.sock default_character_set = latin1 prompt="\\\\u@\\\\h [\\\\d]>" [root@mysqldb02 ~]# |
SLAVE2:
[root@mysqldb03 ~]# more /etc/my.cnf [mysqld] port = 3306 socket = /data/mysql/mysql.sock basedir = /usr/local/mysql datadir = /data/mysql user = mysql symbolic_links = 0 character_set_server = latin1 autocommit = off transaction_isolation = READ-COMMITTED
server-id = 3
## Master setting log_bin = /data/mysql/logs/binlog log_bin_index = /data/mysql/logs/binlog.index
## Slave setting relay_log = /data/mysql/logs/relay-log relay_log_index = /data/mysql/logs/relay-log.index master_info_repository=TABLE relay_log_info_repository=TABLE log_slave_updates = on relay_log_recovery = on relay_log_purge= off
[mysqld_safe] log_error = /var/log/mysqld.log
[client] socket = /data/mysql/mysql.sock default_character_set = latin1 prompt="\\\\u@\\\\h [\\\\d]>" [root@mysqldb03 ~]# |
MHA安装配置
在master上创建监控用户
在所有MySQL节点授权拥有管理权限的用户可在本地网络中有其他节点上远程访问。 当然, 此时仅需要且只能在 master 节点运行如下SQL语句即可,它会复制到所有的slave节点。
create user \'mhaadmin\'@\'192.168.56.%\' identified by \'mhapass\'; grant all on *.* to \'mhaadmin\'@\'192.168.56.%\' ; |
配置SSH免秘钥登录
MHA集群中的各节点彼此之间均需要基于SSH互信通信,以实现远程控制及数据管理功能。
简单起见,可在Manager节点生成密钥对儿,并设置其可远程连接本地主机后, 将私钥文件及authorized_keys文件复制给余下的所有节点即可。
下面操作在所有节点上进行:
# ssh-keygen -t rsa # ssh-copy-id -i .ssh/id_rsa.pub root@mysqldb05 |
当四台机器都进行了上述操作以后,我们可以在manager机器上看到authorized_keys文件,四台机器的公钥都已经在authorized_keys这个文件中了,接着,我们只需要把这个文件发送至另外三台机器,这四台机器就可以实现SSH无密码互通了。
# scp authorized_keys root@mysqldb01:~/.ssh/ # scp authorized_keys root@mysqldb02:~/.ssh/ # scp authorized_keys root@mysqldb03:~/.ssh/ |
安装MHA
四个节点都需安装mha4mysql-node:
#下载MHA-node https://github.com/yoshinorim/mha4mysql-node/releases #安装依赖,这里遇到的报错大多事因为没有安装依赖环境 yum install -y perl-DBD-MySQL perl-ExtUtils-MakeMaker perl-CPAN #解压 tar zxf mha4mysql-node-0.58.tar.gz #移动到/usr/local/mha4mysql-node-0.58目录下 mv mha4mysql-node-0.58 /usr/local/mha4mysql-node-0.58 #编译 cd /usr/local/mha4mysql-node-0.58 perl Makefile.PL #make并安装 make make install |
Manager节点需额外安装mha4mysql-manager:
#下载MHA-manager https://github.com/yoshinorim/mha4mysql-manager/releases #安装依赖包 yum install –y perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager #解压 tar -zxf mha4mysql-manager-0.58.tar.gz #移动目录 mv mha4mysql-manager-0.58 /usr/local/mha4mysql-manager-0.58 # 编译安装 cd /usr/local/mha4mysql-manager-0.58/ perl Makefile.PL make make install |
配置及初始化MHA
Manager 节点可以为每个application指定一个配置文件,配置文件的路径可以自定义。例如:为这套一主多从的环境创建一个配置文件,命令如下。
# mkdir -p /etc/masterha/app1 # vi /etc/masterha/app1/app1.cnf |
配置管理文件内容如下所示。
[server default] manager_workdir=/etc/masterha/app1 manager_log=/etc/masterha/app1/manager.log #刚才授权的MHA管理用戶名 user=mhaadmin password=mhapass #ssh免密钥登录的帐号名 ssh_user=root #mysql复制帐号,用来在主从机之间同步二进制日志等 repl_user=repuser repl_password=welcome1 #ping间隔,用来检测master是否正常 ping_interval= 1
master_ip_failover_script= /etc/masterha/app1/master_ip_failover master_ip_online_change_script= /etc/masterha/app1/master_ip_online_change
[server1] hostname=192.168.56.131 port=3306 master_binlog_dir=/data/mysql/logs
[server2] hostname=192.168.56.132 port=3306 master_binlog_dir=/data/mysql/logs candidate_master=1
[server3] hostname=192.168.56.133 port=3306 master_binlog_dir=/data/mysql/logs candidate_master=1 |
同理:所有的node节点上也执行以上操作。
编写VIP切换脚本
这两个脚本存放在/etc/masterha/app1目录下。
[root@mysqldb05 app1]# chmod +x master_ip_failover [root@mysqldb05 app1]# chmod +x master_ip_online_change |


检测配置文件
检测各节点间SSH互信通信配置是否ok,可以在Manager机器上输入下述命令来检测:
# masterha_check_ssh -conf=/etc/masterha/app1/app1.cnf |
执行该命令时,有可能会报错,报错信息如下。
"NI_NUMERICHOST" is not exported by the Socket module "getaddrinfo" is not exported by the Socket module "getnameinfo" is not exported by the Socket module Can\'t continue after import errors at /usr/local/share/perl5/MHA/NodeUtil.pm line 29 ………. |
解决办法:
#打开cpan cpan #查看配置 >o conf #指定阿里云cpan源,国内还是这个比较稳定 >o conf urllist push http://mirrors.aliyun.com/CPAN/ #提交更改 >o conf commit #查看是否修改成功 >o conf urllist #安装相关插件,记得要按yes >install IO::Socket::INET6 #也是相关插件,记得要按yes >install ExtUtils::Constant #还是相关插件,记得要按yes >install YAML #安装上本坑的重点,socket插件 >install Socket #顺便也将坑1的问题也修复一下吧,记得要按yes >install DBD::mysql |
检查管理的MySQL复制集群的连接配置参数是否OK,可以在Manager机器上输入下述命令来检测:
# masterha_check_repl -conf=/etc/masterha/app1/app1.cnf |
此命令可能会提示错误:
Sat Apr 18 21:38:59 2020 - [info] Connecting to root@192.168.56.132(192.168.56.132:22).. Can\'t exec "mysqlbinlog": No such file or directory at /usr/local/share/perl5/MHA/BinlogManager.pm line 106. mysqlbinlog version command failed with rc 1:0, please verify PATH, LD_LIBRARY_PATH, and client options |
解决办法:
[root@mysqldb01 etc]# ln -s /usr/local/mysql/bin/mysqlbinlog /usr/local/bin/mysqlbinlog [root@mysqldb01 etc]# ln -s /usr/local/mysql/bin/mysql /usr/local/bin/mysql [root@mysqldb01 etc]# |
在所有的MySQL服务器上执行以上语句。
MHA工具及脚本说明
那么 MHA 具体是通过什么操作的呢,其实就是一些 perl 脚本,包括manager和node工具包,具体说明如下。
MHA manager端常用工具:
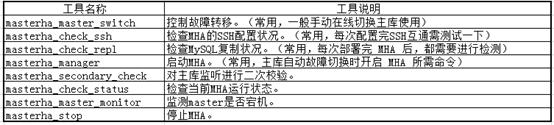
Manager端可能需要使用到的脚本:

在mha4mysql-manager 软件包中包括了这4个脚本的编写示例,编写语言为perl。例如:/usr/local/mha4mysql-manager-0.58/samples/scripts 目录下会有相关脚本,但是提供的这些脚本不完整,需要自己修改:
master_ip_failover //自动切换时vip管理的脚本,不是必须,如果我们使用keepalived的,我们可以自己编写脚本完成对vip的管理,比如监控mysql,如果mysql异常,我们停止keepalived就行,这样vip就会自动漂移
master_ip_online_change //在线切换时vip的管理,不是必须,同样可以可以自行编写简单的shell完成
power_manager //故障发生后关闭主机的脚本,不是必须
send_report //因故障切换后发送报警的脚本,不是必须。
也可以自行编写简单的shell完成以上工作。
MHA node 端常用工具(这些工具由manager触发,不需人工操作):

启动MHA
在manager节点上执行以下命令来启动 MHA:
# nohup masterha_manager -conf=/etc/masterha/app1/app1.cnf &> /etc/masterha/app1/manager.log & |
启动成功以后,我们来查看一下master节点的状态:
# masterha_check_status -conf=/etc/masterha/app1/app1.cnf |
如果,我们想要停止MHA,则需要使用stop命令:
# masterha_stop -conf=/etc/masterha/app1/app1.cnf |
MHA切换
为了防止脑裂发生,推荐生产环境采用脚本的方式来管理虚拟ip,而不是使用keepalived来完成。
手动绑定VIP。需要先在MASTER节点上绑定VIP。
[root@mysqldb01 ~]# /sbin/ifconfig eth0:1 192.168.56.100/24 [root@mysqldb01 ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 08:00:27:2a:08:20 brd ff:ff:ff:ff:ff:ff inet 192.168.56.131/24 brd 192.168.56.255 scope global eth0 valid_lft forever preferred_lft forever inet 192.168.56.100/24 brd 192.168.56.255 scope global secondary eth0:1 valid_lft forever preferred_lft forever inet6 fe80::a00:27ff:fe2a:820/64 scope link valid_lft forever preferred_lft forever 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 08:00:27:5e:2e:ac brd ff:ff:ff:ff:ff:ff inet 192.168.1.5/24 brd 192.168.1.255 scope global eth1 valid_lft forever preferred_lft forever inet6 fe80::a00:27ff:fe5e:2eac/64 scope link valid_lft forever preferred_lft forever [root@mysqldb01 ~]# |
模拟自动failover
(1)、手动关闭MASTER节点,触发自动FAILOVER。
[root@mysqldb01 ~]# service mysql stop |
[root@mysqldb02 ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 08:00:27:e2:17:dc brd ff:ff:ff:ff:ff:ff inet 192.168.56.132/24 brd 192.168.56.255 scope global eth0 valid_lft forever preferred_lft forever inet 192.168.56.100/24 brd 192.168.56.255 scope global secondary eth0:1 valid_lft forever preferred_lft forever inet6 fe80::a00:27ff:fee2:17dc/64 scope link valid_lft forever preferred_lft forever 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 08:00:27:0a:54:96 brd ff:ff:ff:ff:ff:ff inet 192.168.1.6/24 brd 192.168.1.255 scope global eth1 valid_lft forever preferred_lft forever inet6 fe80::a00:27ff:fe0a:5496/64 scope link valid_lft forever preferred_lft forever [root@mysqldb02 ~]# |
可以看出,VIP已经飘移到SLAVE节点。
(2)、VIP和MASTER会自动切换到SLAVE节点上。但整个MHA环境已经无法自动管理,当以前的MASTER节点恢复后,需要手动将以前的MASTER加入主从恢复,重新构建成一个一主多从的复制环境。
注意:故障转移完成后,manager将会自动停止,此时使用masterha_check_status命令检测将会遇到错误提示,如下所示:
[root@manager ~]# masterha_check_status -conf=/etc/mha_master/mha.cnf mha is stopped(2:NOT_RUNNING). |
需要手动修复整个一主多从环境,才能运行该脚本。
处理完毕后,MHA才可以继续工作。 以上是关于MySQL MHA架构的主要内容,如果未能解决你的问题,请参考以下文章