一. Spark简介
1.1 前言
Apache Spark是一个基于内存的计算框架,它是Scala语言开发的,而且提供了一站式解决方案,提供了包括内存计算(Spark Core),流式计算(Spark Streaming),交互式查询(Spark SQL),图形计算(GraphX),机器学习(MLLib)。
1.2 安全性
默认情况下Spark安全性是关闭的。(正式环境要开启)
1.3 版本兼容性
| Spark版本 | Java版本 | Python版本 | Scala版本 | R版本 |
|---|---|---|---|---|
| 2.4.1~2.4.5 | 8 | 2.7+/3.4+ | 2.12.x | 3.1+ |
二. 部署
2.1 Spark集群介绍
2.1.1 集群架构
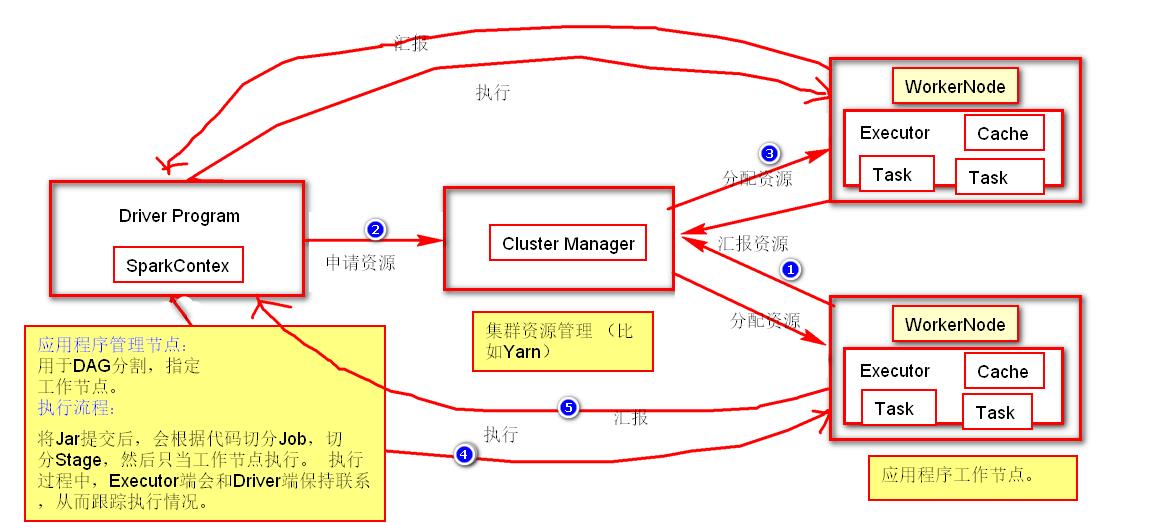
有关此结构的几点概要:
- 每个应用程序都有独立的进程,并且开启多个线程进行执行。这样应用程序的调度(每个Driver调度自己的Executer)和执行(在不同的JVM上执行)互不影响。因此只有把执行结果放在外部存储器里面才能被其它程序使用。
- Spark不受集群限制,只要Driver和应用程序能进行通信就能执行。
- Driver会监测每个执行的程序。
- Driver应靠近Executor,这样网络的不稳定性和带宽消耗。
PS:集群管理器类型包括:独立部署,Spark模式部署,Mesos模式部署,Kubernetes模式部署。
2.1.2 提交方式
使用spark-submit可以将应用程序提交到任何形势的集群。
2.1.3 监控UI
浏览端口4040查看任务。例如:http://node1:4040
浏览端口8080查看Master。例如:http://node1:8080
2.1.4 术语表
| 术语名 | 简介 |
|---|---|
| Application | 基于Spark的应用程序。 |
| Application jar | 一个包含Spark应用程序的jar。 |
| Driver program | 运行应用程序main(),并创建SparkContext的过程。 |
| Cluster manager | 用于获取外部集群资源的服务。(比如mesos,yarn) |
| Deploy mode | 部署方式:在“集群”模式下部署在集群内部,在“客户端”模式下,提交者在集群外部启动程序。 |
| Worker node | 工作节点(在集群中可以运行应用程序的节点。) |
| Job | 一个action触发对应一个job。 |
| Stage | 根据job中的shuffler操作划分多个stage。 |
| Task | 每个stage对应一个多多个task。 |
| Executor | executor可以执行多个task。 |
| DAG | 中文名,有向无环图。根据RDD之间的关系进行构建。 |
2.1.5 Spark程序执行流程图
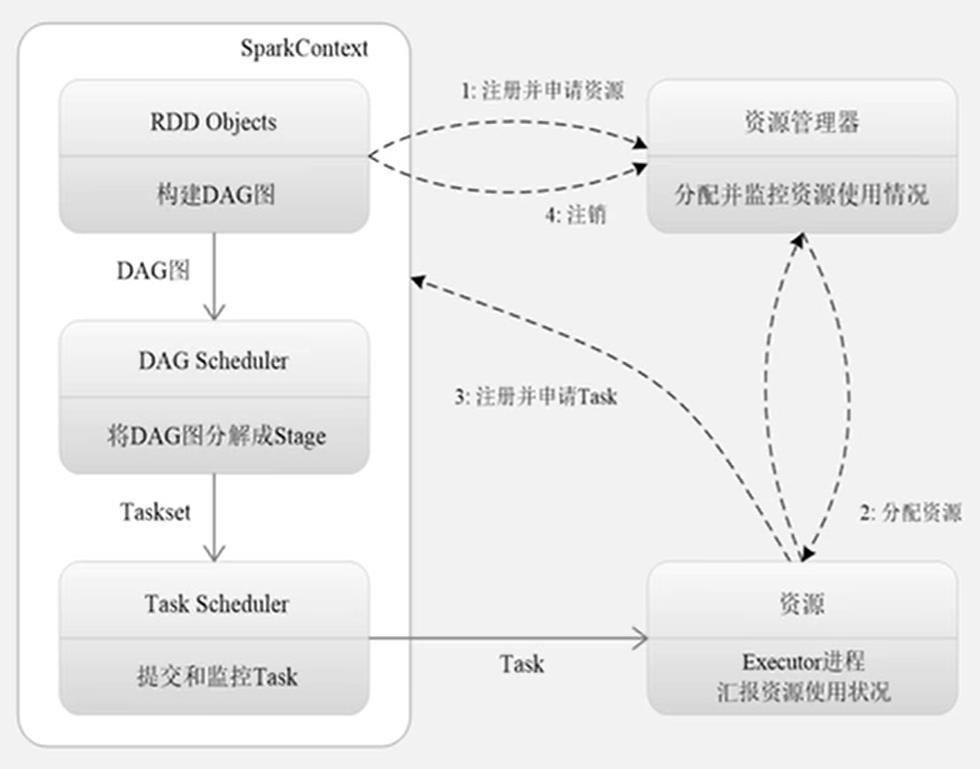
2.1.6 Spark技术栈
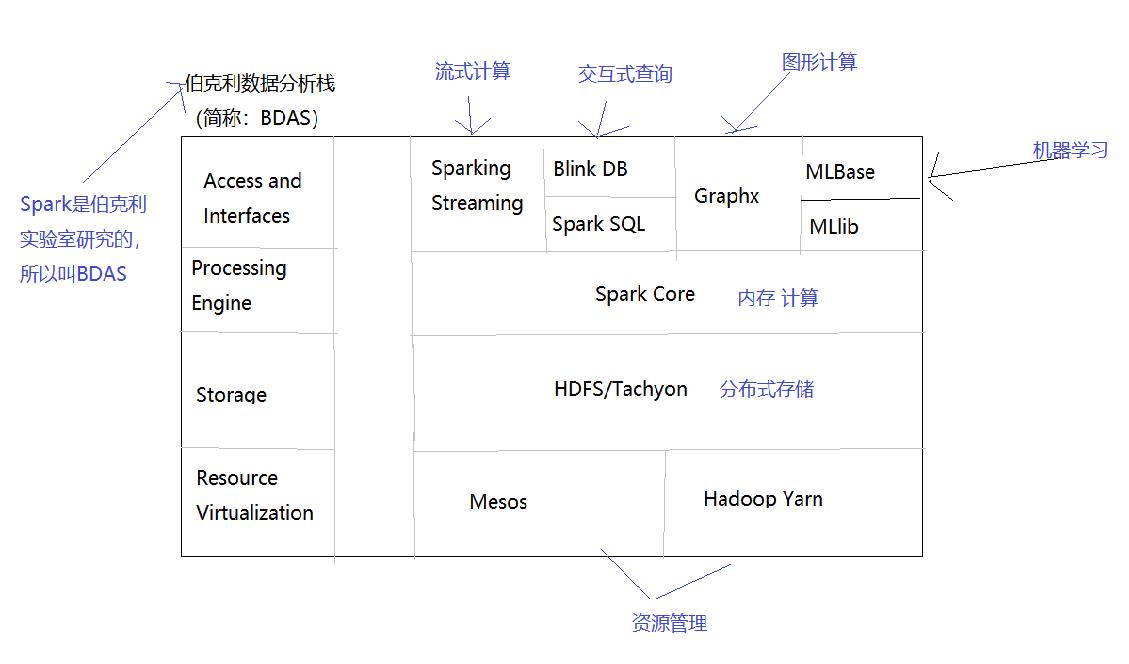
2.2 Standalone部署
2.2.1 安全性
默认情况下Spark是关闭安全的,所以如果您不配置则可能会被攻击。如何设置安全,请参阅 Spark安全性 。
2.2.2 Standalone部署到集群
从官网下载对应版本放在服务器解压即可。这里我下载的2.4.5
在tuge1创建了一个/opt/spark目录,并将下载的压缩包放上去,然后分发到tuge2,tuge3。
服务器部署如下:
| 服务器名: | tuge1 | tuge2 | tuge3 |
|---|---|---|---|
| Spark版本: | Spark2.4.5 | Spark2.4.5 | Spark2.4.5 |
2.2.3 手工启动
在master服务器(tuge1)执行如下脚本启动:
# ./sbin/start-master.sh
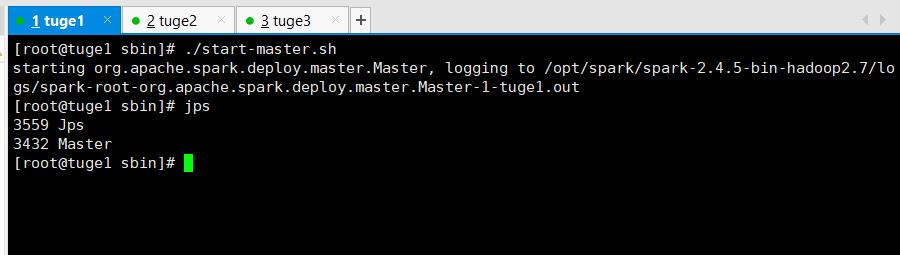
启动后就可以使用默认端口8080访问了。比如: http://tuge1:8080/
同样您可以启动一个或多个Worker,并通过以下方式连接到主节点:
./sbin/start-slave.sh <master-spark-URL>
比如在tuge2,tuge3服务器执行: ./sbin/start-slave.sh spark://tuge1:7077 。这样就将worker服务连接到了master。
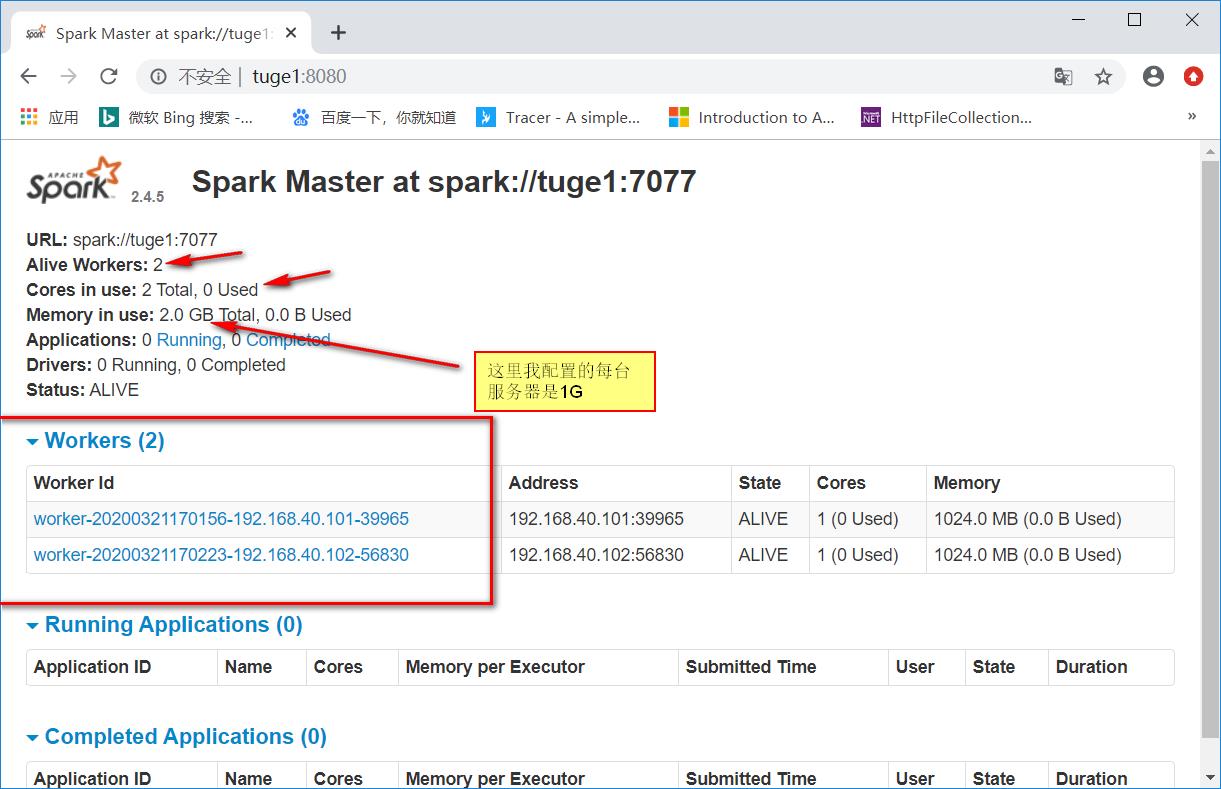
启动后再次浏览http://tuge1:8080/就可以看到新增了两个Worker。
2.2.4 使用脚本启动
要使用启动脚本启动Spark独立集群,您应该在Spark目录中创建一个名为conf / slaves的文件,该文件必须包含要启动Spark Worker的所有计算机的主机名,每行一个。如果conf / slaves不存在,则启动脚本默认为单台计算机(localhost),这对于测试非常有用。请注意,主计算机通过ssh访问每个工作计算机。默认情况下,ssh是并行运行的,并且需要设置无密码(使用私钥)访问权限。如果没有无密码设置,则可以设置环境变量SPARK_SSH_FOREGROUND并为每个工作线程依次提供一个密码。
您可以选择通过在中设置环境变量来进一步配置集群conf/spark-env.sh。通过模板conf/spark-env.sh.template创建文件,然后将其复制到所有工作计算机上以使设置生效。可以使用以下设置(必须配置的已经加粗):
| 环境变量 | 含义 |
|---|---|
| JAVA_HOME | 配置Java环境。(注:这个最好配置下,我就是因为没配置导致启动报了Unsupported major.minor version 52.0错误~!) |
| SPARK_MASTER_HOST | 将主机绑定到特定的主机名或IP地址,例如公共主机名或IP地址。 |
| SPARK_MASTER_PORT | 在另一个端口上启动主服务器(默认:7077)。 |
| SPARK_MASTER_WEBUI_PORT | 主Web UI的端口(默认值:8080)。 |
| SPARK_MASTER_OPT | 仅以“ -Dx = y”的形式应用于主服务器的配置属性(默认值:无)。请参阅下面的可能选项列表。 |
| SPARK_LOCAL_DIRS | 用于Spark中“临时”空间的目录,包括存储在磁盘上的地图输出文件和RDD。它应该在系统中的快速本地磁盘上。它也可以是不同磁盘上多个目录的逗号分隔列表。 |
| SPARK_WORKER_CORES | 允许Spark应用程序在计算机上使用的核心总数(默认值:所有可用的核心)。 |
| SPARK_WORKER_MEMORY | 允许Spark应用程序在计算机上使用的内存总量,例如1000m,2g(默认值:总内存减去1 GB);请注意,每个应用程序的单独内存都是使用其spark.executor.memory属性配置的。 |
| SPARK_WORKER_PORT | 在特定端口上启动Spark worker(默认:随机)。 |
| SPARK_WORKER_WEBUI_PORT | 辅助Web UI的端口(默认值:8081)。 |
| SPARK_WORKER_DIR | 要在其中运行应用程序的目录,其中将包括日志和暂存空间(默认值:SPARK_HOME / work)。 |
| SPARK_WORKER_OPTS | 仅以“ -Dx = y”的形式应用于工作程序的配置属性(默认值:无)。请参阅下面的可能选项列表。 |
| SPARK_DAEMON_MEMORY | 分配给Spark主守护程序和辅助守护程序本身的内存(默认值:1g)。 |
| SPARK_DAEMON_JAVA_OPTS | Spark主服务器和辅助服务器守护程序的JVM选项以“ -Dx = y”的形式出现(默认值:无)。 |
| SPARK_DAEMON_CLASSPATH | Spark主守护程序和辅助守护程序本身的类路径(默认值:无)。 |
| SPARK_PUBLIC_DNS | Spark主服务器和辅助服务器的公共DNS名称(默认值:无)。 |
您可以基于Hadoop的部署脚本,使用以下shell启动或停止集群, 该脚本在SPARK_HOME/sbin下面:
sbin/start-master.sh-在执行脚本的计算机上启动主实例。sbin/start-slaves.sh-在conf/slaves文件中指定的每台计算机上启动一个从属实例。sbin/start-slave.sh-在执行脚本的计算机上启动从属实例。sbin/start-all.sh-如上所述,同时启动一个主机和多个从机。sbin/stop-master.sh-停止通过sbin/start-master.sh脚本启动的主机。sbin/stop-slaves.sh-停止conf/slaves文件中指定的机器上的所有从属实例。sbin/stop-all.sh-如上所述,停止主机和从机。
这里我就使用sbin/start-all.sh命令将Application和Worker启动了~!
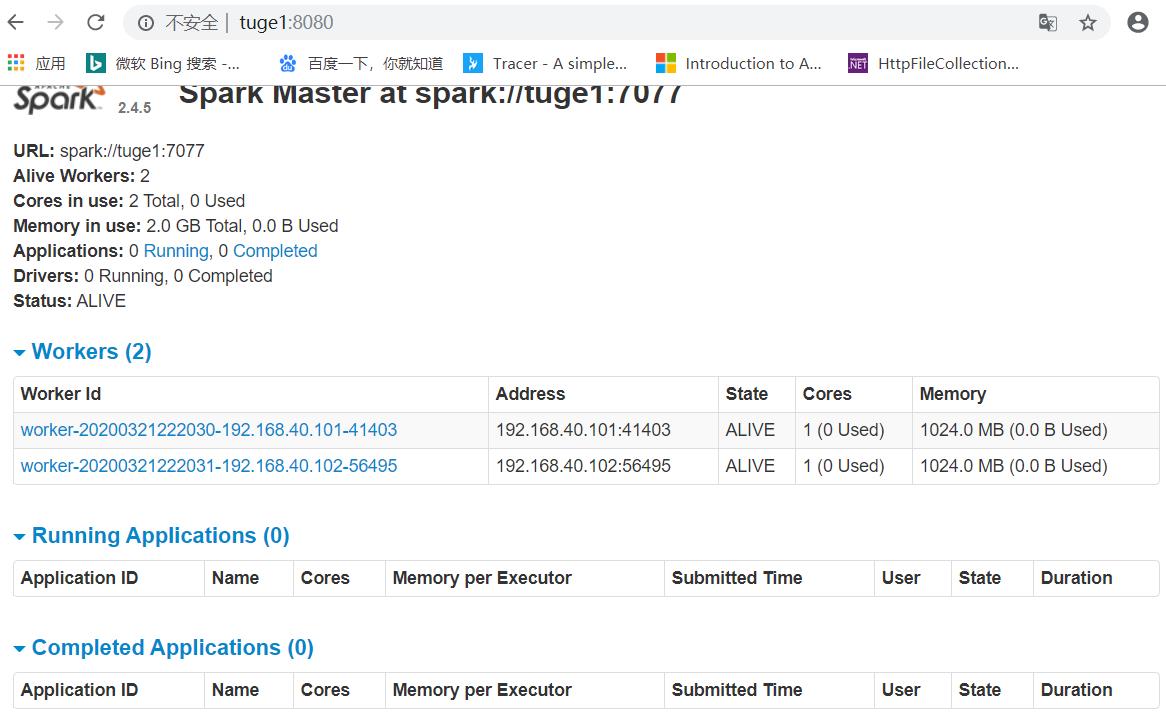
2.2.5 使用shell链接集群
执行如下命令进行链接(spark://IP:PORT)
# ./spark-shell --master spark://tuge1:7077
您还可以传递一个选项,比如--total-executor-cores 来控制spark-shell在集群上使用的核心数量。
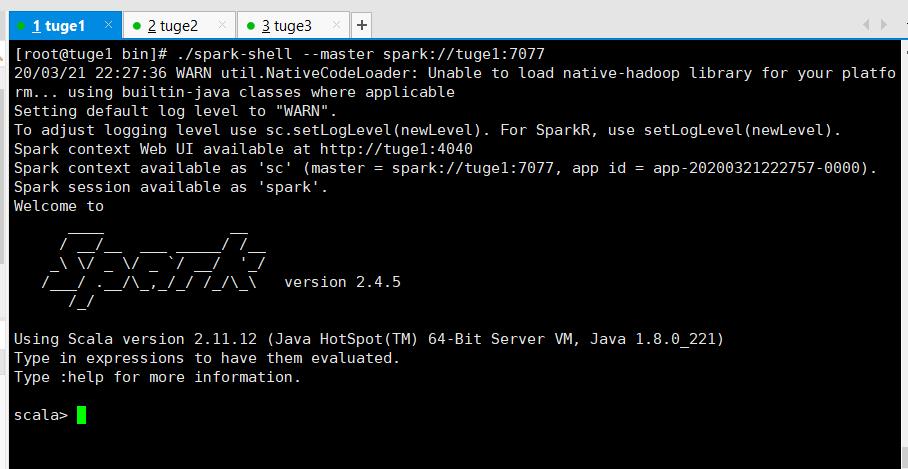
(控制台)
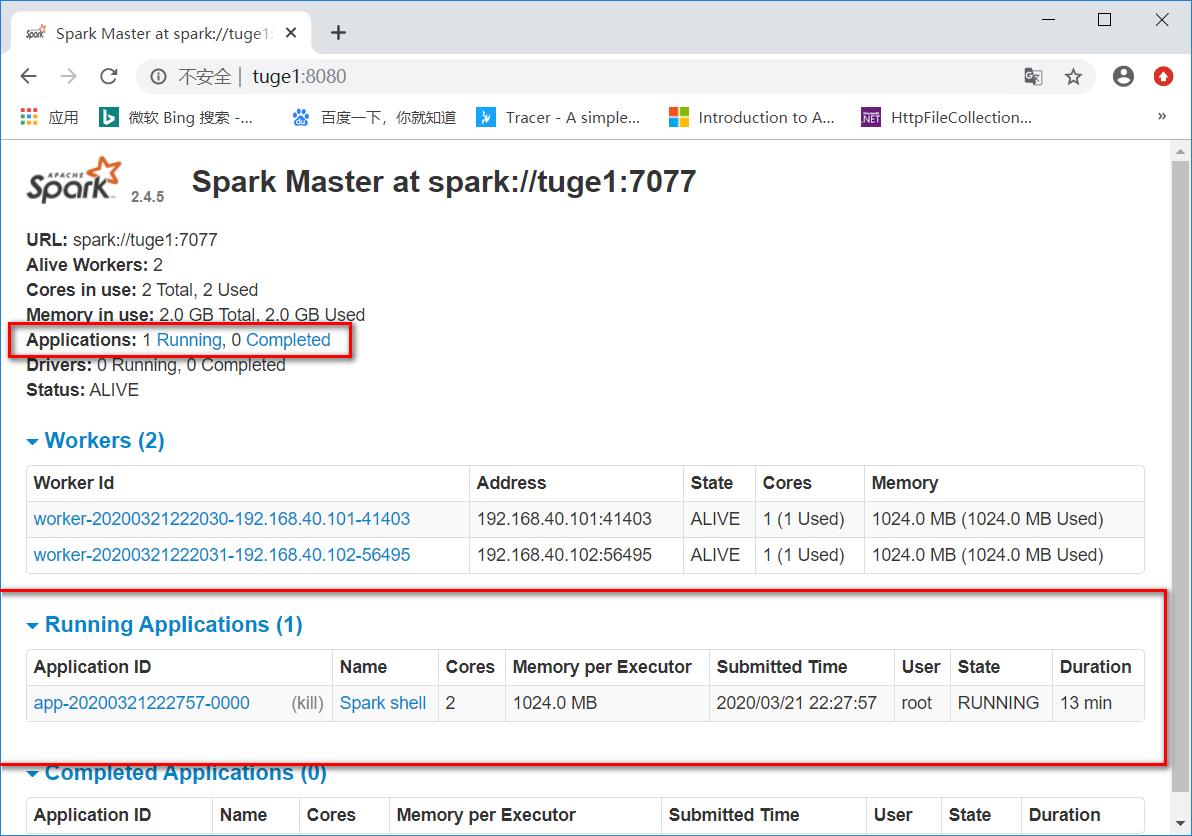
(WebUI)
2.2.6 将程序submit到集群
使用spark-submit脚本进行提交。
就拿官方自带程序进程演示吧,下载好Spark2.4.5到本地后进行解压,可以在
examples\\src\\main\\java\\org\\apache\\spark\\examples 看到java示例程序。
然后整个项目的压缩包可以在examples\\jars下找到:
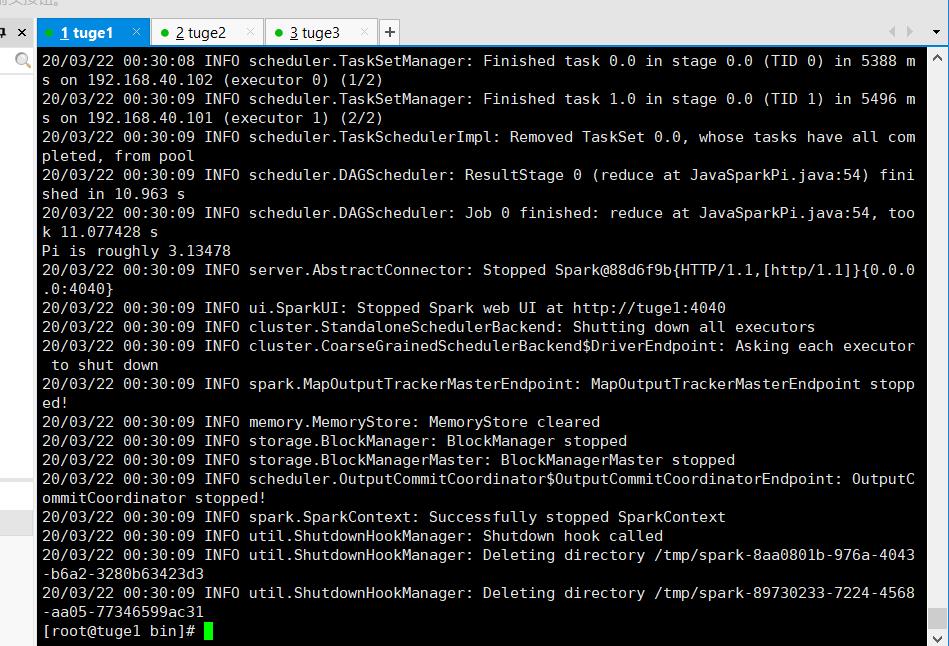
就拿JavaSparkPi举例:
# ./bin/spark-submit \\
> --class org.apache.spark.examples.JavaSparkPi \\
> --master spark://tuge1:7077 \\
> /opt/spark/spark-2.4.5-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.5.jar
执行结果:
2.2.7 通过代码设置资源
standalone遵循的是先进先出原则,默认情况下 ,它将获取所有内核,这仅在您一次只运行一个程序才有意义。要过要同时运行多个,必须要限制内核,如下:
val conf=new SparkConf()
conf.setMaster("....")
conf.setAppName("...")
conf.set("spark.cores.max","3")//限制最大内核数量是3
val sc=new SparkContext(conf)
此外还可以在集群上进行配置。因此将以下内容添加到conf/spark-env.sh
export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores=<value>"
2.2.8 通过命令设置资源
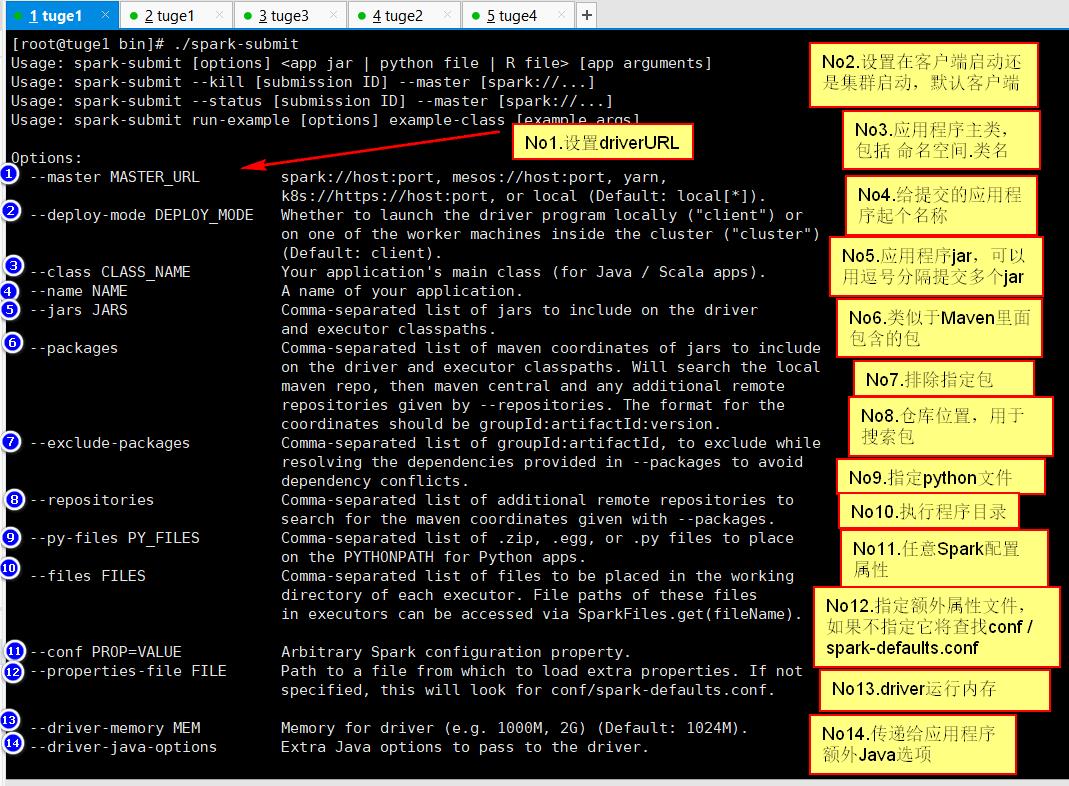
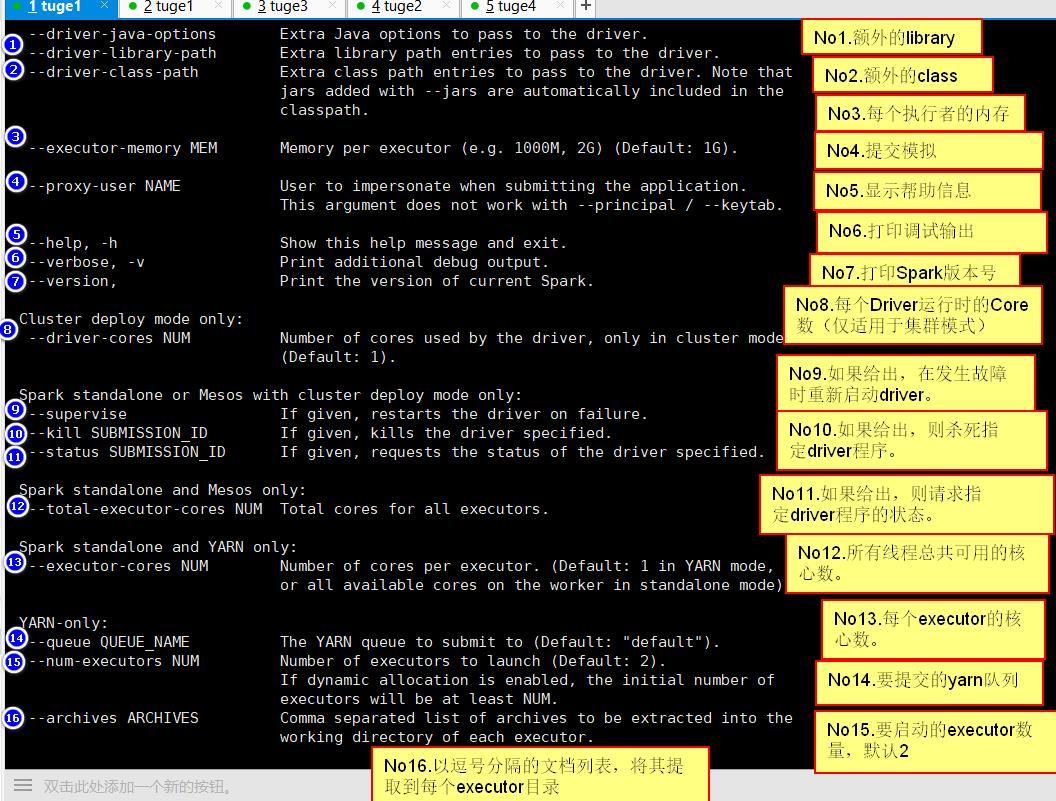
执行/bin/spark-submit 会显示可以使用的命令:
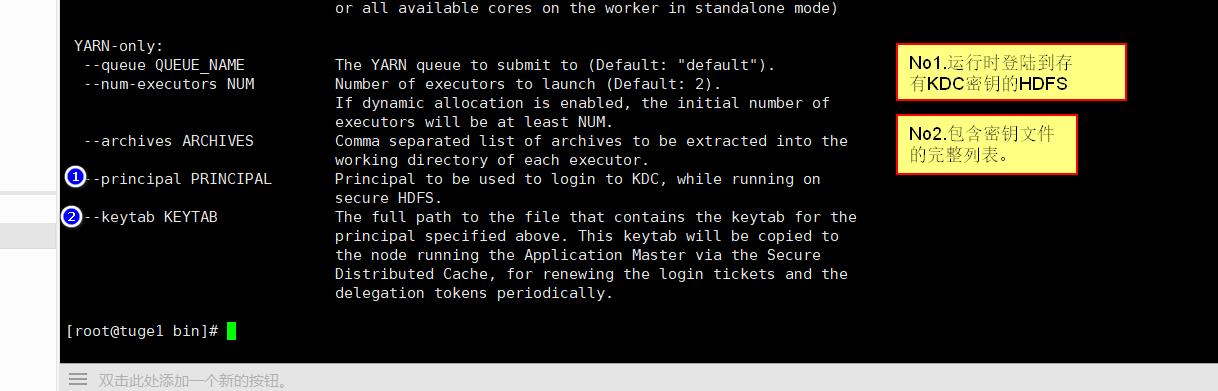
2.2.9 与Hadoop部署在一起
与Hadoop一起部署,这样就可以通过HDFS获取资源,而不仅仅是本地磁盘。这样做的好处,就是集群中所有节点都能够访问资源。
2.2.10 通过配置端口实现安全性
Spark默认部署在内网环境中。如果要进行安全设置参考 安全性页面
2.2.11 通过Zookeeper实现Master高可用
- 使用Zookeeper实现高可用
总览
利用Zookeeper实现高可用:会存在一个主服务器和多个备用服务器,当主服务器挂掉之后,Zookeeper会通过心跳进行感知,从而通过选举机制选举一台从服务器当新的主。
组态
为了启用此恢复模式,您可以通过配置spark.deploy.recoveryMode及相关的spark.deploy.zookeeper。在spark-env.sh中设置SPARK_DAEMON_JAVA_OPTS 。有关这些配置的更多信息,请参阅配置文档
| 物业名称 | 默认 | 含义 |
|---|---|---|
| spark.deploy.recoveryMode | none | 设置为ZOOKEEPER代表发生故障使用zookeeper。 |
| spark.deploy.zookeeper.url | none | zookeeper主机的名字。 |
| spark.deploy.zookeeper.dir | none | spark要在zookeeper上写数据时的保存目录 |
例如我的配置如下:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=tuge1:2181,tuge2:2181,tuge3:2181 -Dspark.deploy.zookeeper.dir=/opt/spark"
然后修改slaves文件(先修改一台,然后分发)
# vim slaves
tuge1
tuge2
tuge3
zookeeper默认和spark端口都是8080,有冲突,所以要么修改zookeeper端口,要么修改spark端口,这里我修改的zookeeper端口。
在conf/zoo.cfg里面添加自定义端口:admin.serverPort=9999
如果上面配置完后,开始启动:
先启动zookeeper, 在每台机器上执行该命令:
# zkServer.sh start
启动Spark
# sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/spark-2.4.5-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-tuge1.out
tuge2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.4.5-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-tuge2.out
tuge3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.4.5-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-tuge3.out
tuge1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.4.5-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-tuge1.out
# jps
6402 QuorumPeerMain
7797 Master
7868 Worker
7948 Jps
在第二台机器上单独启动master
# sbin/start-master.sh
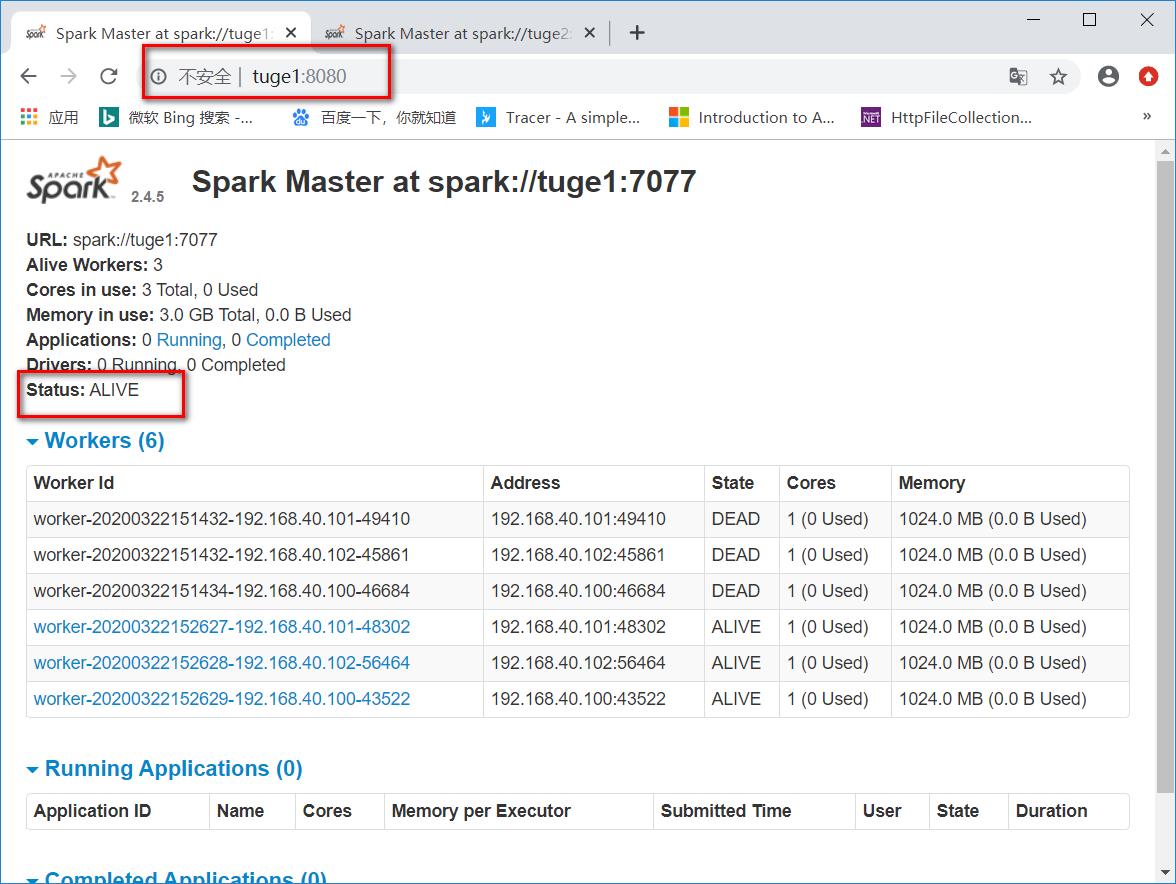
查看web端口
第一个master为
Status: ALIVE
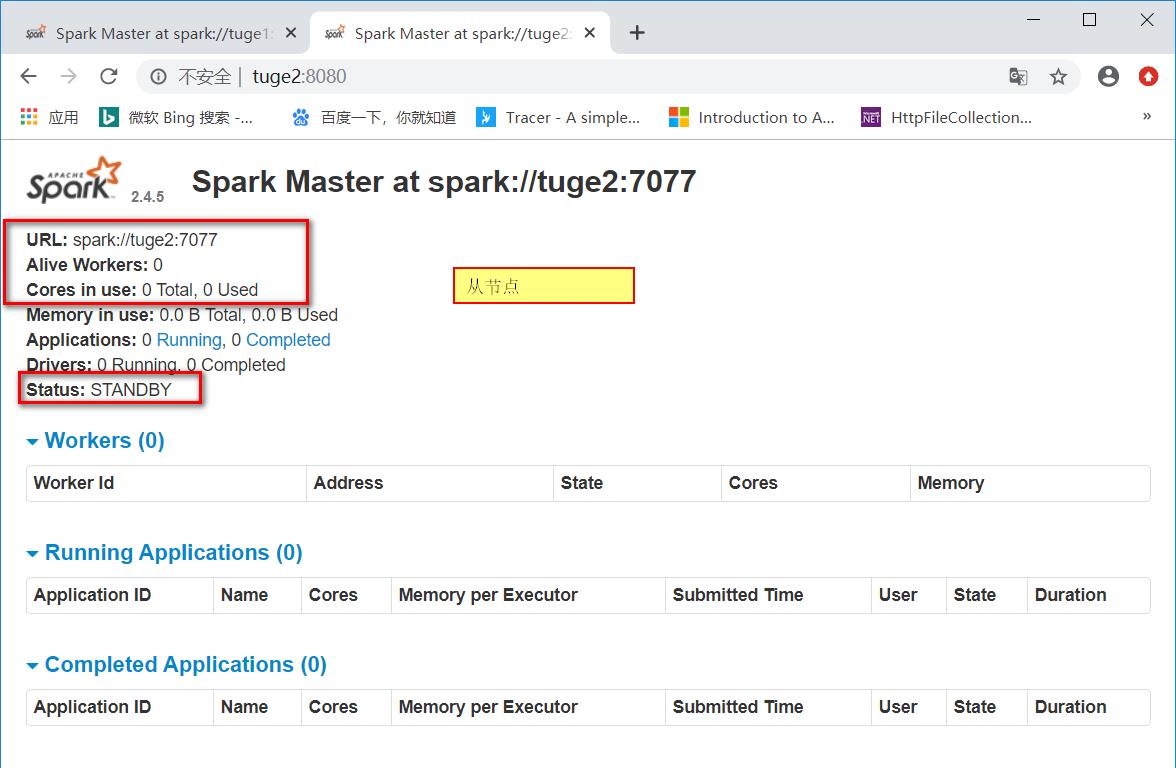
第二个master为
Status: STANDBY
这个时候如果把tuge1杀死,然后再看下tuge2是否转为ALIVE。
通过jps可知,tuge1的masterpid为8365。这里我就接简单粗暴了 :
# kill 8365
然后查看页面,可以看出tuge1已经无法访问,tuge2成为了新的leader。
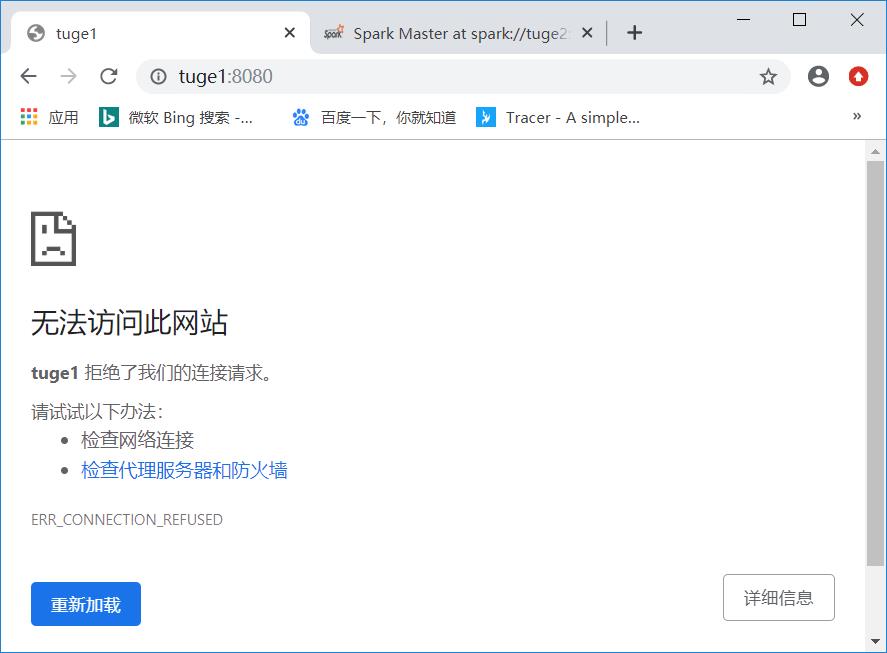
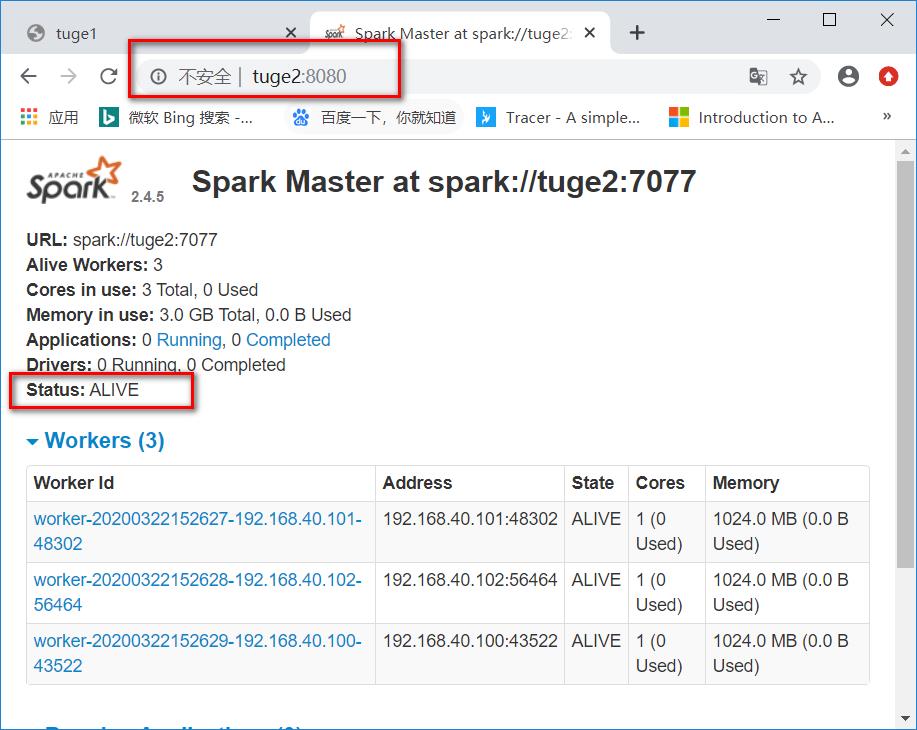
搭建成功~
- 使用本地文件恢复
总览
zookeeper是生产级高可用方法,但是如果您只想在主服务器出现故障时启动它,则 FILESYSTEM模式可以解决这一问题。当Application和Worker注册时,它们可以将状态写入到下面配置的目录里面,以便重新启动主进程时恢复它们。
您可以通过在spark-env设置开启本地文件恢复。
| 系统属性 | 含义 |
|---|---|
| spark.deploy.recoveryMode | 设置为FILESYSTEM以启用单节点恢复模式(默认值:NONE)。 |
| spark.deploy.recoveryDirectory | 从主服务器的角度来看,Spark将存储恢复状态的目录。 |
2.3 Yarn部署
2.3.1 安全性
默认情况下Spark是关闭安全的,所以如果您不配置则可能会被攻击。如何设置安全,请参阅 Spark安全性 。
2.3.2 Spark在Yarn上启动
确保HADOOP_CONF_DIR或YARN_CONF_DIR指向包含Hadoop集群的(客户端)配置文件的目录。 这些配置用于写入HDFS,并链接到Yarn。
# vim spark-env.sh
加入如下配置(将Hadoop里面的配置文件引入进来)(tuge1,tuge2,tuge3服务器都要修改)
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
从上面介绍可以得知,这个是基于HDFS和Yarn的,所以在运行Spark程序之前要先启动HDFS和Yarn。
# cd /opt/hadoop/hadoop-2.6.5/sbin/
# ./start-dfs.sh
# ./start-yarn.sh
以cluster模式启动Spark应用程序:
$ ./spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options] <app jar> [app options]
例如:
$ ./spark-submit --class org.apache.spark.examples.JavaSparkPi \\
--master yarn \\
--deploy-mode cluster \\
--driver-memory 4g \\
--executor-memory 2g \\
--executor-cores 1 \\
--queue thequeue \\
/opt/spark/spark-2.4.5-bin-hadoop2.7/examples/jars/spark-examples*.jar \\
10
以client模式启动Spark应用程序:
$ ./spark-shell --master yarn --deploy-mode client
添加其它JAR
在cluster模式下,驱动程序与客户端运行在不同的计算机上,因此SparkContext.addJar对于客户端本地的文件而言,开箱即用。要使客户机上的文件可用于SparkContext.addJar,请将它们包含--jars在启动命令中的选项中。
$ ./bin/spark-submit --class my.main.Class \\
--master yarn \\
--deploy-mode cluster \\
--jars my-other-jar.jar,my-other-other-jar.jar \\
my-main-jar.jar \\
app_arg1 app_arg2
2.3.3 设置网络授权(Kerberos)
2.3.4 配置外部Shuffle服务
2.3.5 Spark通过oozie工作流启动
我们可以使用Apache Oozie来启动Spark应用程序,如果Spark配置了安全启动,则使用Spark安全令牌,如果没配置,则通过Oozie设置安全性。
有关Oozie安全设置参考网站.
对于Spark应用程序,必须为Oozie设置Oozie工作流,以请求该应用程序需要的所有令牌,包括:
- YARN资源管理器。
- 本地Hadoop文件系统。
- 任何用作I / O源或目标的远程Hadoop文件系统。
- Hive-如果使用的话。
- HBase-如果使用的话。
- YARN时间轴服务器(如果应用程序与此交互)。
为了避免Spark尝试(然后失败)获取Hive,HBase和远程HDFS令牌,必须将Spark配置设置为禁用服务的令牌收集。
Spark配置必须包括以下几行:
spark.security.credentials.hive.enabled false
spark.security.credentials.hbase.enabled false
spark.yarn.access.hadoopFileSystems必须取消配置选项。
2.3.5 用Spark History Server替换Spark Web UI
禁用应用程序UI时,可以将Spark History Server应用程序页面用作运行应用程序的跟踪URL。在安全群集上或减少Spark驱动程序的内存使用量可能是理想的。要通过Spark History Server设置跟踪,请执行以下操作:
- 在应用程序端,
spark.yarn.historyServer.allowTracking=true在Spark的配置中进行设置。如果禁用了应用程序的UI,这将告诉Spark使用历史服务器的URL作为跟踪URL。 - 在Spark History Server上,添加
org.apache.spark.deploy.yarn.YarnProxyRedirectFilter到spark.ui.filters配置中的过滤器列表。
请注意,历史记录服务器信息可能不是与应用程序状态有关的最新信息。
2.4 Kubernetes(k8s)上部署
参考文档
http://spark.apache.org/docs/latest/running-on-kubernetes.html
这个功能属于实验阶段,后面有可能会有修改。这里不演示了,有兴趣的自行查阅。
2.5Apache Mesos部署
参考文档
http://spark.apache.org/docs/latest/running-on-mesos.html
这个功能公司用的不多,学习的话直接参考官网文档就行了,我这里先不安装了。
三.编程
3.1 快速入门
3.1.1 安全性
默认情况下Spark是关闭安全的,所以如果您不配置则可能会被攻击。如何设置安全,请参阅 Spark安全性 。
3.1.2 使用Spark Shell交互
3.1.2.1 简单交互
这里主要以Scala语言进行介绍。
准备数据集(可以通过Hdfs和其它数据集来准备)
- 在本地创建一个数据文件
# mkdir -p /data/spark
# vim sparkData1.txt
#填写如下内容
hello world
What are you doing?
Nice to meet you~
hello YiMing
你好啊 一明
#按Esc ,然后输入:wq保存并退出
- 将数据提交到Hdfs的/user/root目录下
# hdfs dfs -put sparkData1.txt /user/root
启动:
# ./bin/spark-shell
scala> val textFile = spark.read.textFile("sparkData1.txt")
注意:使用spark.read.textFile()默认读取的是hdfs文件,也可以显示指定hdfs:// ,如果要读取本地文件加上file:// ,比如file:///data/spark/sparkData,或者使用 ./data/spark/sparkData
操作
scala> textFile.count()
res0: Long = 5 //计算出行数是5行
scala> textFile.first()
res2: String = hello world //查询出第一行的内容
我们可以通过过滤操作创建新的数据集
scala> val linesWithSpark = textFile.filter(line => line.contains("hello world"))
linesWithSpark: org.apache.spark.sql.Dataset[String] = [value: string]
scala> linesWithSpark.count()
res4: Long = 1 //可以看到存在一行
我们可以将过滤动作和计算count链接在一起
scala> textFile.filter(line => line.contains("hello world")).count()
res5: Long = 1
3.1.2.2 数据集交互
scala> textFile.map(line=>line.split(" ").size).reduce((a,b)=>if(a>b) a else b)
res8: Int = 4
通过导入类库,来实现计算
scala> import java.lang.Math
import java.lang.Math
scala> textFile.map(line=>line.split(" ").size).reduce((a,b)=>Math.max(a,b))
mapList: Int = 4
使用spark实现MapReduce流
scala> val wordCounts=textFile.flatMap(line=>line.split(" ")).groupByKey(identity).count()
wordCounts: org.apache.spark.sql.Dataset[(String, Long)] = [value: string, count(1): bigint]
scala> wordCounts.collect()//把结果打印出来
res4: Array[(String, Long)] = Array((doing?,1), (Nice,1), (你好啊,1), (you,1), (一明,1), (YiMing,1), (hello,2), (are,1), (meet,1), (What,1), (world,1), (to,1), (you~,1))
指定缓存数据
scala> textFile.cache()
res6: textFile.type = [value: string]
scala> textFile.count()
res7: Long = 5
scala> textFile.count()
res8: Long = 5
3.1.3 Spark计算Demo
建立一个sbt项目,起名SimpleApp,并在build.sbt里面配置如下内容
name := "SimpleApp"
version := "0.1"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.5"
右键scala文件夹->New->Scala Class 选择Object,起名Simple 确定
添加如下代码
def main(args: Array[String]): Unit = {
val rootPath= System.getProperty("user.dir")//获取项目根目录
var bookFilePath = System.getProperty("user.dir") + "\\\\data\\\\Book"; //拼接路径
val spark = SparkSession.builder.appName("SimpleApp").getOrCreate()//获取SparkSession
val bookData = spark.read.textFile(bookFilePath).cache() //获取文件内容并缓存
val hei = bookData.filter(line => line.contains("黑")).count() //计算文件中包含“黑”的行数
println(hei)
spark.stop()
}
在项目根目录下创建一个data文件夹,并在里面添加一个Book文件,注意没有后缀哦。在 Book里面添加如下内容:
这世界既残酷也温柔 22
唐骏转 44
增长黑客 11
蓝筹孩子 55
富爸爸穷爸爸 21
未来世界的幸存者 44
智慧农业 13
工业4.0 81
厚黑学 66
配置本地运行:
选择Run->Edit Configuratioins,在VM Options添加-Dspark.master=local参数。
然后运行就可以看到结果了,结果是2就没问题了。
3.2 RDD编程指南
3.2.1 前言
Spark提供了弹性分布式集(RDD)和共享变量。
RDD是一种分布式的跨节点的数据集,可以通过HDFS,文件系统转换得到。
共享变量就是将一个变量的副本分发给运行的任务。共享变量共有两种,一种是广播变量(broadCast),一种是累加器(accumulator)。
RDD中有个概念叫宽依赖,窄依赖。如果父RDD和子RDD是一对一或者多对一,则是窄依赖,窄依赖之间的RDD属于同一个Stage。如果父RDD对应多个子RDD,这个时候就发生了Shuffler操作,这样的两个RDD叫宽依赖,宽依赖会执行断开操作,及两个RDD属于不同Stage。
Stage分为ShuffleMapStage和ResultStage,当发生Shuffle时才会有ShuffleStage。
3.2.2 配置代码环境
PS:Spark 2.4.5所兼容的Scala是2.12.X。
使用maven依赖添加以下内容:
spark依赖
groupId=org.apache.spark
artifactId=spark-core_2.12
version=2.4.5
haddop hdfs依赖
groupId=org.apache.hadoop
artifactId=hadoop-client
version=2.6.5
程序中导入
Scala导入
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
Java导入:
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.SparkConf;
3.2.3 初始化Spark
在使用Spark的第一件事当然是创建SparkContext,但是在创建SparkContext之前,要先创建SparkConf对集群进行配置。
Scala初始化:
val conf=new SparkConf().setAppName("RDDDemo1").setMaster("local")
new SparkContext(conf)
Java初始化:
SparkConf conf = new SparkConf().setAppName("RDDDemo1").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
setAppName里面填写应用显示的名字,setMaster填写Standalone,Spark,Kubernetes的链接,但是一般都在使用submit命令的时候手动指定,而不是写死。在本地测试的话,填写\'local\'就行了。
3.2.3.1 Spark Shell介绍
在Spark Shell中,默认为您创建了一个特殊的可识别解释器的SparkContext sc。制作自己的SparkContext将不起作用。
另外上面2.2.8已经做了详细介绍,可以参考。
3.2.4 弹性分布式数据集(RDDs)
3.2.4.1 并行执行Array
通过sparkcontext的parallelize方法创建并行集合。
Scala实现:
val data=Array(1,2,3,4)
val distData=sc.parallelize(data,10)
Java实现:
List<Integer> data = Arrays.asList(1, 2, 3, 4);
JavaRDD<Integer> distData = sc.parallelize(data);
创建后分布式数据集(distData)就可以并行操作。 例如,我们可能会调用distData.reduce((a, b) => a + b)以添加数组的元素。Spark将为每一个分区运行一个任务,默认每个CPU是2-4个分区,通常Spark会根据您的集群手动设置分区数,当然了也可以手动指定,比如上面我指定的10。
3.2.4.2 使用外部数据集
Spark可以从Hadoop支持的任何存储(hdfs,cassandra,hbase,本地文件)创建分布式数据集。
比如:
scala实现:
scala> val distFile = sc.textFile("data.txt")
distFile: org.apache.spark.rdd.RDD[String] = data.txt MapPartitionsRDD[10] at textFile at <console>:26
Java实现:
JavaRDD<String> distFile = sc.textFile("data.txt");
有关使用Spark读取文件的一些注意事项。
- 如果使用本地文件路径,还必须在Worker上访问该文件。则必须将文件复制到所有Worker服务器,或者安装网络共享文件系统。
- 文件路径可以使用通配符:比如:/data/*.txt
- 该txtFile还可以使用第二个参数控制分区数。默认情况,Spark为每个块创建一个分区(HDFS块默认值为128M),但是您可以设置更大的值来请求更大数量的分区。
除了文本文件,Spark的API还支持其它几种数据格式:
-
SparkContext.wholeTextFiles使您可以读取包含多个文本文件的目录。
-
读取序列化文件使用sequenceFile
-
对于其它Hadoop InputFormat,还可以使用SparkContext.hadoopRDD方法
-
RDD操作
RDD支持两种类型的操作:transformation和action。例如map是一个转换,将每个数据集传递给一个函数。reduce是一个动作,需要将计算结果返回。
Spark所有的transformation都是惰性的,因为它不会立即计算结果。仅当应用程序需要将结果返回时,才进行转换。
-
基本
为了说明RDD基础,请考虑下面程序
Scala版:
val conf = new SparkConf().setAppName("test").setMaster("local") val sc = new SparkContext(conf) val data = sc.textFile("file:///F:\\\\Code\\\\Scala\\\\SparkTest\\\\data\\\\words") val lineLength = data.map(line => line.length).persist() val totalLength = lineLength.reduce((a, b) => a + b) println(totalLength)
上面的程序给words里面的所有字数做了一个汇总。persist是对数据进行缓存,这个时候还没真正执行,当时候reduce的时候需要返回结果了,这个时候才会去执行map。
-
将函数传递给Spark
例如:
Scala实现:
val data = sc.textFile("file:///F:\\\\Code\\\\Scala\\\\SparkTest\\\\data\\\\words") val lineLengths = data.map(line => line.length).map(line=>addOne(line))//计算每行的长度,并且每行都加1 val totalLength=lineLengths.reduce((a,b)=>a+b)//统计总的长度def addOne(n: Integer): Integer = { n + 1 }Java实现:
JavaRDD<String> lines = sc.textFile("file:///F:\\\\Code\\\\Scala\\\\SparkTest\\\\data\\\\words"); JavaRDD<Integer> addOneLine = lines.map(line -> addOne(line));//计算每行的长度,并且每行都加1 int totalLength = addOneLine.reduce((a, b) -> a + b);//统计总的长度public static Integer addOne(String str) { return str.length() + 1; }-
闭包
Spark的难点之一就是跨集群执行时了解它的作用范围和生命周期。如下面例子:
-
例子
Scala代码:
var counter = 0 var rdd = sc.parallelize(data) // Wrong: Don\'t do this!! rdd.foreach(x => counter += x) println("Counter value: " + counter)Java代码:
int counter = 0; JavaRDD<Integer> rdd = sc.parallelize(data); // Wrong: Don\'t do this!! rdd.foreach(x -> counter += x); println("Counter value: " + counter);上面的例子运行得到的结果还是0,因为集群执行时,它分发的是副本,做的是副本累加。
要实现累加,我们可以使用累加器(accumulator),
val acc=sc.longAccumulator() rdd.foreach(x=>acc.add(x)) println(acc.value)上面就能正确打印结果了。当使用Accumulator的时候,注意使用一次action或者使用cache,persist切断之前的依赖。否则,累加器会持续累加。参考:( https://blog.csdn.net/zhaojianting/article/details/80228093 )
-
打印RDD
本地打印的时候,直接foreach循环就打印了,而在集群上打印,则需要把数据进行一次收集,要不计算的结果不会主动返回给Driver的。
-
-
3.2.4.2.1转换键值对并使用
以打印每行出现的次数为例:
Scala实现:
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
val lines = sc.textFile("file:///F:\\\\Code\\\\Scala\\\\SparkTest\\\\data\\\\words")
val mapLine = lines.map(line => (line, 1))//得到一个key,value数组
val reduceLine = mapLine.reduceByKey((a, b) => a + b)//得到一个key,value数组
reduceLine.foreach(println)
Java实现:
JavaPairRDD<String, Integer> mapPairLine = lines.mapToPair(s -> new Tuple2(s, 1));//得到一个key,value数组
JavaPairRDD<String, Integer> reducePairLine = mapPairLine.reduceByKey((Integer a, Integer b) -> a + b);//得到一个key,value数组
Map<String, Integer> countMap = reducePairLine.collectAsMap();
for (Map.Entry<String, Integer> entry : countMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
3.2.4.2.2Transformations(算子)
| TransFormation | 说明 |
|---|---|
| map(func) | 返回一个新的数据集,该数据集通过执行fun函数形成的。 |
| filter(func) | 返回一个新的数据集,该数据集返回执行fun函数为true的数据形成的。 |
| flatMap(func) | 与map相似,但是每行都可以映射到0或多个输出项。 |
| mapPartitions(func) | 与map相似,但是分别在RDD的每个分区上运行,因此fun在类型T的RDD上运行必须为Iterator |
| mapPartitionsWithIndex(func) | 与mapPartitions相似,但它还为func提供表示分区索引的整数值,因此当在类型T的RDD上运行时,func必须为(Int,Iterator |
| sample(withReplacement, fraction, seed) | 对数据进行随机采样。withReplacementde代表是否有放回抽样。fraction如果是0.几那么就代表抽中百分比,如果是1,2之类的整数,代表每个元素随机抽中的次数。 |
| union(otherDataset) | 并集 |
| intersect(otherDataset) | 交集 |
| distinct([numPartitions]) | 返回不同的元素 |
| groupByKey([numPartitions]) | 根据key进行分组。例如:val rdd = sc.parallelize(List((1, 3), (4, 7), (1, 86))) val groupData = rdd.groupByKey() 这样将3和86归为1,7归为4 |
| reduceByKey(func, [numPartitions]) | 根据key合并分组。例如:val rdd = sc.parallelize(List((1, 3), (4, 7), (1, 86))) val reduceData = rdd.reduceByKey((a, b) => a + b) 这样就会得到1,89 4,7 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]) | 设定一个初始值和两个函数,在初始值的基础上结合两个函数对原始数据进行操作。例如:val rdd = sc.parallelize(List(1, 2, 3, 4)) val result = rdd.aggregate(1)(add1, add2) //会先通过初始值1+值1,2,3,4计算出值为11,然后11带入add2初始值1+11=12 def add1(p1: Int, p2: Int) = { p1 + p2 } def add2(p1: Int, p2: Int) = { p1 + p2 } |
| sortByKey([ascending], [numPartitions]) | 根据key进行排序 |
| join(otherDataset, [numPartitions]) | 将两组相同key的值链接到一起组成新的键值对。 |
| cogroup(otherDataset, [numPartitions]) | 在(K,V)和(K,W)类型的数据集上调用时,返回(K,(Iterable |
| cartesian(otherDataset) | 在类型T和U的数据集上调用时,返回(T,U)对(所有元素对)的数据集。比如:(1,2)和(3) 会返回(1,3)(2,3)组合 |
| pipe(command, [envVars]) | 可以进行外部程序调用。比如调用python:val scriptpath="/tmp/test/test.py" println(rddData.pipe(scriptpath).collect().toList) |
| coalesce(numPartitions) | 将RDD分区减少到numPartitions。 |
| repartition(numPartitions) | 在RDD中随机重排以获得更多或更少的分区。 |
| repartitionAndSortWithinPartitions(partitioner) | 根据给定的分区程序对RDD进行重新分区,并在每个分区结果中,按其键进行排序。 |
3.2.4.2.3Actions(算子)
| Action | 说明 |
|---|---|
| reduce(func) | 使用func函数聚合数据集元素。 |
| collect() | 在driver中收集所有元素并返回。通常收集较小数据集时候用。 |
| count() | 返回数据集中的元素数。 |
| first() | 返回第一个元素,类似于(take(1)) |
| take(n) | 返回n个元素。 |
| takeSample(withReplacement, num, [seed]) | 返回带有num个元素的随机取样数据。withReplacement代表是否重复提取。 |
| takeOrdered(n, [ordering]) | 获取排序后的前几个数据 |
| saveAsTextFile(path) | 将数据以文本文件的形势写入到本地文件系统,HDFS或其它支持Hadoop的系统中。 |
| saveAsSequence(path) | 将数据以SequenceFile形势保存在本地文件系统,HDFS或其它支持Hadoop的系统中。 |
| saveAsObjectFile(path) | 将数据以Object的形势保存。 |
| countByKey() | 作用于k,v类型,返回k,int统计value的数量。 |
| foreach(func) | 在数据集每个函数上运行func。 |
3.2.4.2.4PV例子
val conf = new SparkConf().setAppName("PVCalc").setMaster("local")
val sc = new SparkContext(conf)
val data = sc.textFile("./data/ipData")
val pv = data.map(line => (line.split(" ")(0), 1)).countByKey()
pv.foreach(println)
3.2.4.2.5UV例子
val conf = new SparkConf().setMaster("local").setAppName("uv")
val sc = new SparkContext(conf)
val data = sc.textFile("./data/ipData")
val uv = data.map(line => (line.split(" ")(0) + "_" + line.split(" ")(1))).distinct().map(line => (line.split("_")
(0), 1)).reduceByKey(_ + _).sortBy(_._2, false) //按照倒序进行排列,如果参数仅仅使用一次,可以用"_"代替,如上面的写法按照常规的应该写为.sortBy(line=>line._2)
// ,如果有多个参数出现一次,可以使用"_*"代替,比如sum(1 to 5:_*)
uv.foreach(println)
参考资料:
idea如何设置自动换行: https://blog.csdn.net/zwj_jyzl/article/details/98473864
Scala中的_ 和 _*分别代表什么?: https://blog.csdn.net/wyz0516071128/article/details/81042667
3.2.4.2.6 Shuffle操作
-
背景
运行reduceBykey等操作需要在集群上拉取数据。
-
性能影响
由于大量的磁盘操作,于是考虑使用内存,但是内存容量达到一定级别就会持久化,这样还是很浪费性能的。
3.2.4.2.7 持久化RDD
- 存储级别
提供了几种持久化级别。
| Storage Level | 说明 |
|---|---|
| MEMORY_ONLY(默认) | 将RDD作为反序列化存在RDD中。如果RDD不能完全缓存,则缓存一部分。 |
| MEMORY_AND_DISK | 将RDD作为反序列化存在RDD中。如果RDD不能完全缓存,则都存在磁盘中。 |
| MEMORY_ONLY_SER (Java and Scala) | 将RDD序列化为JAVA对象。这样会更节省时间,但是读取时很耗费CPU。 |
| MEMORY_AND_DISK_SER (Java and Scala) | 与MEMORY_ONLY_SER类似,但是内存存不开会都存入磁盘。 |
| DISK_ONLY | 将RDD分区存在磁盘。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | 与DISK_ONLY类似,但是在两个集群节点上复制每个分区,及存两份。 |
| OFF_HEAP (experimental) | 与MEMORY_ONLY_SER类似,但是将数据存的是堆外存。 |
- 删除数据
可以等待LRU规则自动释放,也可以调用RDD.unpersist()手动释放。
3.2.5 共享变量
- 广播变量
对所有集群进行广播数据。
Sava实现:
val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar.value
Java实现:
Broadcast<int[]> broadcastVar = sc.broadcast(new int[] {1, 2, 3});
broadcastVar.value();
这样就能在任何节点上获取。
- 累加器
可以对集群中的数据进行累加。
Scala案例:
val accum=sc.longAccumulator
data.map{x=>accum.add(x);}
Java案例:
LongAccumulator accum = jsc.sc().longAccumulator();
data.map(x -> { accum.add(x); return f(x); });
3.2.6单元测试
Spark非常适合使用任何流行的单元测试框架进行单元测试。 只需在测试中创建一个SparkContext,并将主URL设置为local,运行您的操作,然后调用SparkContext.stop()将其拆解。 确保您在finally块或测试框架的tearDown方法中停止上下文,因为Spark不支持在同一程序中同时运行的两个上下文。
3.2.7SparkConfig(配置)
-
Spark属性配置
-
通过编程配置(主要设置SparkConf),举例:
val conf = new SparkConf() .setMaster("local[2]") .setAppName("CountingSheep") -
提交的时候进行指定,举例:
./bin/spark-submit --name "My App" --master local[4] -
在conf/spark-defaults.conf 中进行配置,每行包含一个键和一个由空格分隔的值,举例:
spark.master spark://5.6.7.8:7077 spark.executor.memory 4g spark.eventLog.enabled true spark.serializer org.apache.spark.serializer.KryoSerializer
-
-
Spark环境变量配置
在./conf/spark-env.sh中进行配置,举例:
export JAVA_HOME=/opt/java/jdk1.8.0_221 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=tuge1:2181,tuge2:2181,tuge3:2181 -Dspark.deploy.zookeeper.dir=/opt/spark" export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"} -
Spark日志配置
在log4j.properties中配置。
我们可以直接复制 ./conf/log4j.properties.template进行配置。举例:
mc log4j.properties.template log4j.properties
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR
3.3 Spark SQL,Datasets和DataFrames编程指南
PS:Spark SQL是在Shark Hive上面改进,底层完全自己实现,依赖于Hive的部分有MetaStore和SQL转换为Spark的一些内容。
3.3.1入门
3.3.1.1 SparkSession
SparkSession是所有功能的入口点,要创建SparkSession,只需要使用SparkSession.builder();即可
Scala举例:
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
Java举例:
import org.apache.spark.sql.SparkSession;
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate();
在examples / src / main / scala / org / apache / spark / examples / sql / SparkSQLExample.scala” 可以找到示例源码。
3.3.1.2 创建DataFrames
使用SparkSession可以从现有的RDD,Hive或Spark数据流中读取数据。
例如从JSON文件中读取数据。
Scala举例:
val spark = SparkSession.builder.appName("sparkSession Study").master("local").getOrCreate()
val txtData= spark.read.textFile("./data/words")
txtData.show()//打印结果
Java举例:
SparkSession spark = SparkSession.builder().appName("SparkSession案例").master("local").getOrCreate();
Dataset<String> txtData = spark.read().textFile("./data/words");
txtData.show();//打印结果
显示结果:
+-------------+
| value|
+-------------+
| hello YiMing|
|hello XiaoBei|
| hi LiSi|
| hello|
| hello|
+-------------+
可以在 "examples/src/main/java/org/apache/spark/examples/sql/JavaSparkSQLExample.java" 找到案例。
3.3.1.3 DataSet操作
people文件内容:
{"name":"Michael"}{"name":"Andy", "age":30}{"name":"Justin", "age":19}
Scala演示:
val spark = SparkSession.builder.appName("sparkSession Study").master("local").getOrCreate()
import spark.implicits._ //使用$符号需要此导入
val df = spark.read.json("./data/people")
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
Java演示:
SparkSession spark = SparkSession.builder().appName("SparkSession案例").master("local").getOrCreate();
Dataset<String> df = spark.read().textFile("./data/people");
df.printSchema();
df.groupBy("age").count().show();
df.select("name").show();
df.filter(col("age").gt(21)).show();
df.select(col("name"),col("age").plus(2)).show();
更多代码可在 examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala 找到。
3.3.1.4 以编程方式SQL查询
Scala演示:
val spark = SparkSession.builder().appName("spark SQL Demo").master("local").getOrCreate()
val data = spark.read.json("./data/people")
data.createOrReplaceTempView("person")
val dfSql = spark.sql("select age from person")
dfSql.show()
// +----+
// | age|
// +----+
// |null|
// | 30|
// | 19|
// +----+
Java演示:
SparkSession ss = SparkSession.builder().appName("spark demo ").master("local").getOrCreate();
Dataset<Row> ds = ss.read().text("./data/people");
ds.createOrReplaceTempView("people");
Dataset<Row> dsSql = ss.sql("select *from people");
dsSql.show();
3.3.1.5 全局临时视图
SparkSQL是临时视图作用域的,如果创建它的会话终止,它将消失。如果要在所有会话中共享一个临时视图,直到Spark程序终止,则可以创建全局临时视图。全局临时视图数据库与global_temp关联。例如,选择select *from global_temp view1。
Scala演示:
val spark = SparkSession.builder().appName("spark SQL Demo").master("local").getOrCreate()
val data = spark.read.json("./data/people")
data.createGlobalTempView("people")
spark.sql("select *from global_temp.people").show() //打印结果
spark.newSession().sql("select *from global_temp.people").show()//打印结果
Java演示:
SparkSession ss = SparkSession.builder().appName("spark demo ").master("local").getOrCreate();
Dataset<Row> ds = ss.read().text("./data/people");
ds.createGlobalTempView("people");
ss.sql("select *from global_temp.people").show();
ss.newSession().sql("select *from global_temp.people").show();
在examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala查看示例。
3.3.1.6 创建Datasets
Dataset和RDD相似,但是不是使用Java和Kryo序列化,而是有专门的Encoder对象进行序列化。虽然Encoder和通常的序列化一样将对象转换为字节,但是Encoder是动态生成的代码,并使用一种格式,该格式允许过滤,排序,哈希处理等,并且处理过程中无需反序列化。
Scala举例:
val spark = SparkSession.builder().appName("spark SQL Demo").master("local").getOrCreate()
import spark.implicits._
//示例1:将集合转换为DataSet
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect().foreach(println)
// 2
// 3
// 4
//示例2:将文件内容转换为对象
val peopleData = spark.read.json("./data/people")
val peopleDS = peopleData.as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
3.3.1.7 与RDD互操作
Spark SQL支持两种将现有的RDD转换为Dataset的方法。一种是通过反射,这种代码简洁,适用于运行前就了解架构。另一种是通过编程接口指定,这种代码比较长,这种适用于运行时才了解架构的数据集。
-
使用反射推断架构
words文件内容:
张三 23
小贝 24
王五 55
小明 16
小强 11Scala实现:
val spark = SparkSession.builder().appName("spark SQL Demo").master("local").getOrCreate() import spark.implicits._ val peopleDF = spark.sparkContext .textFile("./data/words") .map(_.split(" ")) .map(attributes => Person(attributes(0), attributes(1).toInt)) .toDF() peopleDF.createOrReplaceTempView("people") val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19") teenagersDF.map(teenager => "Name: " + teenager(0)).show() teenagersDF.map(teenager => "Name:" + teenager.getAs("name")).show() // +---------+ // | value| // +---------+ // |Name:小明| // +---------+ println("映射完后打印") implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]] //指定编码 teenagersDF.map(teenager => teenager.getValuesMap[Any](List("name", "age"))).collect().foreach(println) //Map(name -> 小明, age -> 16) -
以编程接口方式指定架构
val spark = SparkSession.builder().appName("spark demo").master("local").getOrCreate() //首先创建一个RDD //根据第一步创建的RDD创建struct //将struct应用于RDD val wordRDD = spark.sparkContext.textFile("./data/words") val structString = "name age" val structRDD = structString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true)) val schema = StructType(structRDD) val rowRDD = wordRDD.map(line => line.split(" ")).map(line => Row(line(0), line(1))) val wordsDF = spark.createDataFrame(rowRDD, schema) wordsDF.createOrReplaceTempView("people") val select = spark.sql("select name,age from people") implicit val encoder=org.apache.spark.sql.Encoders.STRING//添加字符串类型编码器 select.map(attributes => "Name: " + attributes(0)).show()结果:
+----------+ | value| +----------+ |Name: 张三| |Name: 小贝| |Name: 王五| |Name: 小明| |Name: 小强| +----------+
3.3.1.8 自定义聚合函数
-
定义未类型化的聚合函数
Java演示:
MyAverage.class
import java.util.ArrayList; import java.util.List; import or以上是关于入门大数据---Spark学习的主要内容,如果未能解决你的问题,请参考以下文章