谈谈MySQL的索引
Posted lonelyxmas
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谈谈MySQL的索引相关的知识,希望对你有一定的参考价值。
原文:谈谈MySQL的索引
索引
前言
总所周知,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快。而支撑这一快速的背后就是索引;mysql索引问题也是大家经常遇到的面试题模块,想想自己也没有去系统地总结过索引,所以记录这篇文章来讲下索引。下面还是按照是什么->有什么用->怎么用->来写
是什么
往往大家第一时间提到索引,可能就会说到它是一种数据结构,来提高查询效率的数据结构,用在常用来查询的字段上。但是原理是什么呢?为什么它就可以加快查询?
首先,现如今,数据库系统大多的索引底层结构是B树或者B+树,在数据结构的学习中,大家可能都有了解过,我们先简单介绍下这两种结构。
B树
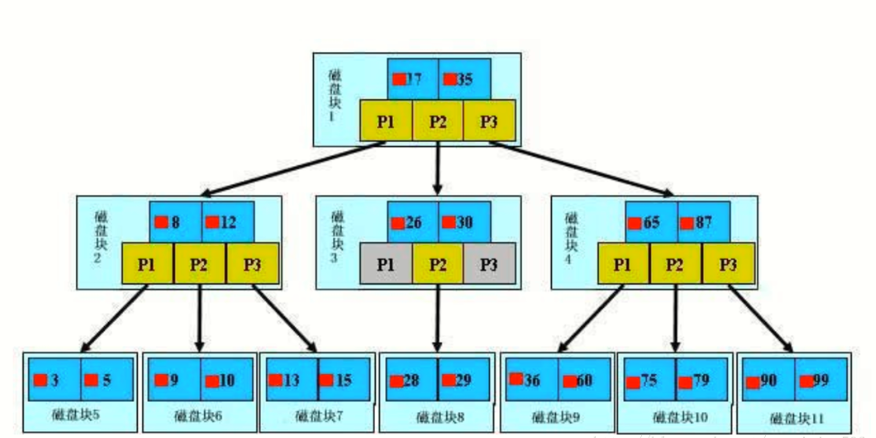
- 特点:每个结点都有数据,同时还有指向其下子树的指针域,单个结构和链表的基本单元相似。
- 每个结点一个数据,等于就命中,小于该数据走左边,大于走右边
B+树
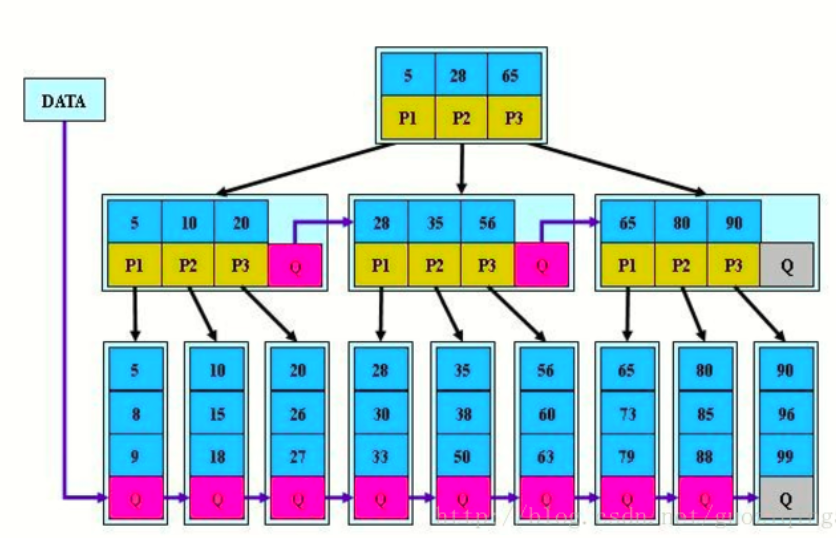
- 是B树的变形,多路搜索树,是一种稠密索引
- 特点:真实的数据存储在叶子结点的链表中,其他非叶子结点并没有数据,而是作为叶子结点的索引;链表中的关键字是有序的。所有叶子结点都在同一层
B树和B+树结构上异同
同:都是平衡树,每个结点到叶子结点的高度都是相同的,也保证每个查询都是稳定,查询的时间复杂度是log2(n),利用平衡树的优势是可以很大程度加快查询的稳定性的。
异:关键字数量不同,存储的位置也不同,查询不同;B树在找到具体的数值以后,则结束,B+树通过索引找到叶子结点的数据才结束,也就是B+树一定都得找到叶子结点。
有什么用
对于两种树结构的使用和应用总结,也就是重要作用。
B树的树内存储数据,因此查询单条数据的时候,B树的查询效率不固定,最好的情况是O(1)。我们可以认为在做单一数据查询的时候,使用B树平均性能更好。但是,由于B树中各节点之间没有指针相邻,因此B树不适合做一些数据遍历操作。
B+树的数据只出现在叶子节点上,因此在查询单条数据的时候,查询速度非常稳定。因此,在做单一数据的查询上,其平均性能并不如B树。但是,B+树的叶子节点上有指针进行相连,因此在做数据遍历的时候,只需要对叶子节点进行遍历即可,这个特性使得B+树非常适合做范围查询。
接下来重点讲的是MySQL的索引结构。
讲回索引,在MySQnL中,索引属于存储引擎级别的概念,而我们常常提到MySQL的引擎,就会提到MyISAM和InnoDB。这里插一下,MyISAM是非聚集(也叫非聚簇)索引,而InnoDB是聚集索引(也叫聚簇)。其实更简单通俗得讲,正文内容按照一个特定维度排序存储,这个特定的维度就是聚集索引;
聚集索引是指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以,对应的聚集索引只能有一个。如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度。 --《百度百科》
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址,想要获得数据,还得通过地址去获得;同时非聚集索引索引项顺序存储,但索引项对应的内容却是随机存储的;
InnoDB表数据文件本身就是一个索引结构,树的叶节点data域保存了完整的数据记录,这种索引叫做聚集索引。这种索引特点是叶子结点完全包含了数据,同时InnoDB要求按主键聚集,所以也要求表要有主键,没有的话系统会自动选择一个唯一标识数据记录的列作为主键。因此,InnoDB的表也叫做索引表;
最后借用一个解释来帮助大家理解聚集索引和非聚集索引。同时这里有个很好的例子
汉语字典提供了两类检索汉字的方式,第一类是拼音检索(前提是知道该汉字读音),比如拼音为cheng的汉字排在拼音chang的汉字后面,根据拼音找到对应汉字的页码(因为按拼音排序,二分查找很快就能定位),这就是我们通常所说的字典序;第二类是部首笔画检索,根据笔画找到对应汉字,查到汉字对应的页码。拼音检索就是聚集索引,因为存储的记录(数据库中是行数据、字典中是汉字的详情记录)是按照该索引排序的;笔画索引,虽然笔画相同的字在笔画索引中相邻,但是实际存储页码却不相邻。
怎么用
首先讲下sql语句。
# 主要记住加索引和删索引操作
# 可以在一开始建表时候加,也可以后面加
# ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
ALTER TABLE table_name ADD INDEX index_name (column_list);
# CREATE INDEX可对表增加普通索引或UNIQUE索引。
CREATE INDEX index_name ON table_name (column_list)
# 删除
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
# 这个只在删除主键的时候使用 常常一张表只有一个主键
ALTER TABLE table_name DROP PRIMARY KEY
下面的是简单使用情况以及结果分析(有索引和没索引的分析),先看一开始表结构的索引情况
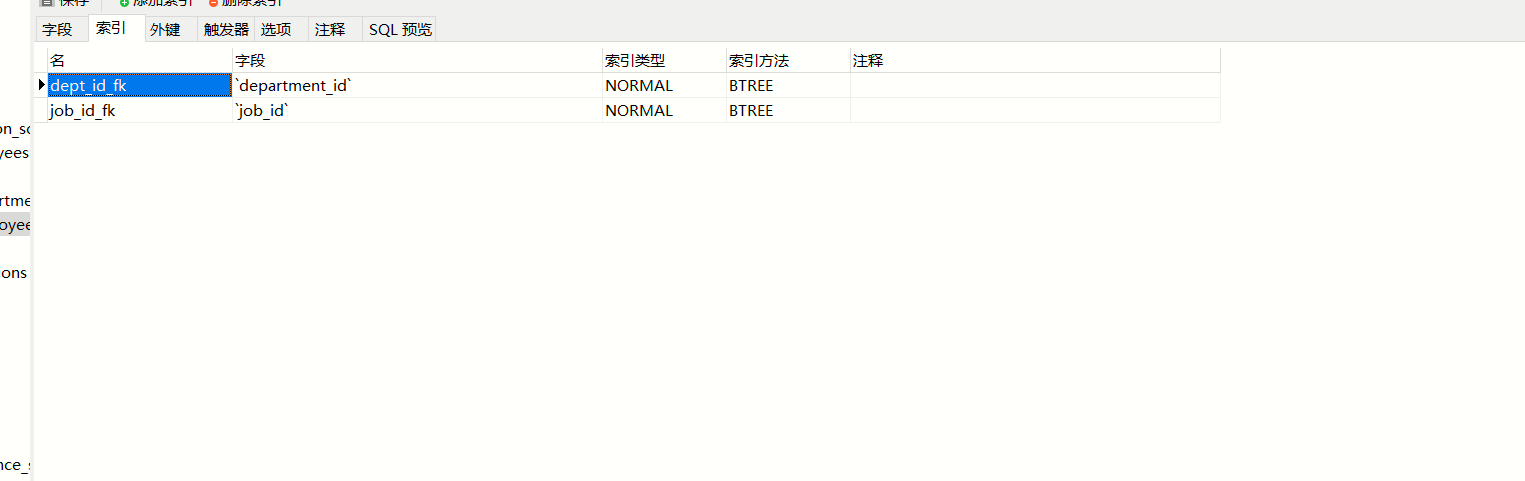
执行以下语句,建立一个first_name_last_name索引。
USE myemployees;
SHOW TABLES;
DESC employees;
# 建立了二级索引,是一个联合索引
ALTER TABLE employees ADD INDEX first_name_last_name
(first_name, last_name);
# 为了明确看到查询性能,我们启用profiling并关闭query cache:
SET profiling = 1;
SET query_cache_type = 0;
SET GLOBAL query_cache_size = 0;
# 用EXPLAIN来查看sql语句执行的情况
EXPLAIN SELECT * from employees WHERE first_name=‘Alyssa‘ AND last_name LIKE ‘%on‘;
DESC employees;
# 删除索引
DROP INDEX first_name_last_name ON employees;
# 查看无索引状态下的执行效率
SELECT * from employees WHERE first_name=‘Alyssa‘ AND last_name LIKE ‘%on‘;
查看此时的索引结构,以及有了索引

执行查询sql,看看有无索引的情况下的EXPLAIN语句情况
首先是无索引下的结果

再来是有索引的

这里解释下我标注出来的这三个参数,其实这里的数据量不是很大,看查询时间差距不大,所以查看rows的参数便可以参考下两个查询的区别,一个只需一行,另一个走了107行数据。所以说索引加快查询效率。之所以会有快速的效果,就是由于上面的B+树的数据结构在起作用。
就像十亿个数据,如果按照常规逻辑,可能最差的情况下,需要匹配十亿次才可以找到,加上这十亿个数据给内存带来了多少的负荷可想而知,所以要是转化为平衡树,可能只需要十层或者十几层之类的树结构,也就数据只需要花费很少的IO开销就可以找到了。这两个的差别就是天壤之别了。
type:表示MySQL在表中找到所需行的方式
? ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
? ref:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
ROWS: 表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
Extra:该列包含MySQL解决查询的详细信息
最后
以上是关于谈谈MySQL的索引的主要内容,如果未能解决你的问题,请参考以下文章