sql
Posted Leo_wlCnBlogs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql相关的知识,希望对你有一定的参考价值。
一.概述
书写sql是我们程序猿在开发中必不可少的技能,优秀的sql语句,执行起来吊炸天,性能杠杠的。差劲的sql,不仅使查询效率降低,维护起来也十分不便。一切都是为了性能,一切都是为了业务,你觉得你的sql技能如何?所有的伟大来自于点滴的积累,不积跬步无以至千里,让sql性能飞起来吧!
二.sql初探
1.常见sql写法注意点
(1)字符类型建议采用varchar/nvarchar数据类型
- char
char是定长的,也就是当你输入的字符小于你指定的数目时,char(8),你输入的字符小于8时,它会再后面补空值。当你输入的字符大于指定的数时,它会截取超出的字符。
nvarchar(n)
包含 n 个字符的可变长度 Unicode 字符数据。n 的值必须介于 1 与 4,000 之间。字节的存储大小是所输入字符个数的两倍。所输入的数据字符长度可以为零。
varchar[(n)]
长度为 n 个字节的可变长度且非 Unicode 的字符数据。n 必须是一个介于 1 和 8,000 之间的数值。存储大小为输入数据的字节的实际长度,而不是 n 个字节。所输入的数据字符长度可以为零。
[1]—CHAR。CHAR存储定长数据很方便,CHAR字段上的索引效率级高,比如定义char(10),那么不论你存储的数据是否达到了10个字节,都要占去10个字节的空间。
[2]—VARCHAR。存储变长数据,但存储效率没有CHAR高。如果一个字段可能的值是不固定长度的,我们只知道它不可能超过10个字符,把它定义为 VARCHAR(10)是最合算的。VARCHAR类型的实际长度是它的值的实际长度+1。为什么“+1”呢?这一个字节用于保存实际使用了多大的长度。 从空间上考虑,用varchar合适;从效率上考虑,用char合适,关键是根据实际情况找到权衡点。
[3]—TEXT。text存储可变长度的非Unicode数据,最大长度为2^31-1(2,147,483,647)个字符。
[4]—NCHAR、NVARCHAR、NTEXT。这三种从名字上看比前面三种多了个“N”。它表示存储的是Unicode数据类型的字符。我们知道字符中,英文字符只需要一个字节存储就足够了,但汉字众多,需要两个字节存储,英文与汉字同时存在时容易造成混乱,Unicode字符集就是为了解决字符集这种不兼容的问题而产生的,它所有的字符都用两个字节表示,即英文字符也是用两个字节表示。nchar、nvarchar的长度是在1到4000之间。和char、varchar比较起来,nchar、nvarchar则最多存储4000个字符,不论是英文还是汉字;而char、varchar最多能存储8000个英文,4000个汉字。可以看出使用nchar、nvarchar数据类型时不用担心输入的字符是英文还是汉字,较为方便,但在存储英文时数量上有些损失。
所以一般来说,如果含有中文字符,用nchar/nvarchar,如果纯英文和数字,用char/varchar。
举例说明:
两字段分别有字段值:我和coffee
那么varchar字段占2×2+6=10个字节的存储空间,而nvarchar字段占8×2=16个字节的存储空间。
如字段值只是英文可选择varchar,而字段值存在较多的双字节(中文、韩文等)字符时用nvarchar
(2)金额货币建议采用money数据类型 (一般常用,最大四位小数)
(3)科学计数建议采用numeric数据类型-- (建议巨额资金交易用numeric)
(4)自增长标识建议采用bigint数据类型 (数据量一大,用int类型就装不下,那以后改造就麻烦了)
(5)时间类型建议采用为datetime数据类型
(6)禁止使用text、ntext、image老的数据类型(已过时)
(7)禁止使用xml数据类型、varchar(max)、nvarchar(max)
(8)禁止在数据库做复杂运算 (业务处理逻辑最好在代码层实现,不要让所有的代码逻辑存在于sql中,不便于后期的问题定位)
(9)禁止使用SELECT * (按需所取,查找自己所需要的列)
(10)禁止在索引列上使用函数或计算
例如:
我们查询注册时间在2015-11-11的店铺账号,找出它们进行活动奖励,我们如果不加注意,很可能写成这样:
select * from T_Account where Convert(varchar(10,Regtime,121)=\'2015-11-11\'这样写的话,我们就无法命中索引字段Regtime,如果T_Account的数据量超大的时候,数据库查询分析器走表扫描,查询效率就降低了;要实现上面的查询结果,其实我们可以换一种写法:
select * from T_Account where Regtime>=\'2015-11-11 00:00:00\' and Regtime<\'2015-11-12 00:00:00\'(11)禁止使用游标
由于游标在处理大数据量的时候,占有的内存较大,效率低。可能造成其他的数据库查询堵塞的现象,除非是当你使用while循环,子查询,临时表,表变量,自建函数或其他方式都无法处理某种操作的时候,再考虑使用游标。
举例说明一下在实际运用中的一个游标处理:
--定义店铺ID declare @accId int set @accId=218424 --1.创建临时表并插入数据 select gsid,gid into #gidlist from T_Goods_Sku where accid=@accId and gid in (select gid from T_GoodsInfo where accid=@accId and isService=0 and IsExtend=1) select gsId,gaVName into #gsidlist from T_Goods_Relation where gsid in (select gsid from T_Goods_Sku where accid=@accId and gid in (select gid from T_GoodsInfo where accid=@accId and isService=0 and IsExtend=1)) order by gsId select a.gid gid,a.gsId gsId,b.gaVName gaVName into #tempgid from #gidlist a left join #gsidlist b on a.gsId=b.gsId drop table #gidlist drop table #gsidlist --2.开始事务 BEGIN TRANSACTION --3.定义变量,累积事务执行过程中的错误 DECLARE @error INT SET @error = 0 --4.声明游标 DECLARE goodsCursor CURSOR SCROLL FOR SELECT gid ,gsId ,gaVName FROM #tempgid --5.打开游标 OPEN goodsCursor --6.声明游标提取数据所要存放的变量 DECLARE @gid INT ,@gsId INT ,@gaVName NVARCHAR(400) ,@gUnionKey NVARCHAR(400) --7.定位游标到哪一行 FETCH First FROM goodsCursor INTO @gid ,@gsId ,@gaVName --8.提取成功,对数据操作,进行下一条数据的提取操作 WHILE @@fetch_status = 0 BEGIN SET @gUnionKey = \'\' SELECT @gUnionKey = gUnionKey from T_GoodsInfo where accid=@accId and isService=0 and IsExtend=1 and gid=@gid SELECT @gUnionKey=@gUnionKey+\'|\'+@gaVName PRINT \'-----start-------\' PRINT @gid PRINT @gsId PRINT @gaVName PRINT @gUnionKey --更新gUnionKey update T_GoodsInfo set gUnionKey=@gUnionKey where accid=@accId and isService=0 and IsExtend=1 and gid=@gid PRINT \'-----end--------\' --移动游标 FETCH NEXT FROM goodsCursor INTO @gid ,@gsId ,@gaVName END --9.判读事务错误数,提交或回滚事务 IF @error <> 0 --有误 BEGIN PRINT \'回滚事务\' ROLLBACK TRANSACTION END ELSE BEGIN PRINT \'提交事务\' COMMIT TRANSACTION END --10.关闭并删除游标,删除临时表 CLOSE goodsCursor DEALLOCATE goodsCursor drop table #tempgid(12)禁止使用触发器
触发器在开发角度来讲,不知道具体什么时候执行,对于业务来讲不跟代码逻辑一样是显示的呈现,所以导致后期的维护比较困难,所以要处理触发器完成的服务,最好通过服务或者中间件去完成。
例如:
在微信收单的过程中,我们销售结账完成以后,需要通过短信向用户手机推送消费消息,这时候用触发器可能就是在结账以后,触发sql触发器,写入一条消息记录到短信表记录,走消息队列,将短信发送出去。
反之,我们采用中间件,就可以将结账以后的记录,发送给消息中间件EasyNetQ,中间件将记录异步写入记录,这样有问题的话,只用确认中间件消息接受和发送的问题。

(13)禁止在查询里指定索引
在sql里面指定索引索引是这样定义的:
SELECT 字段名表 FROM 表名表 WITH (INDEX(索引名)) WHERE 查询条件如果在搜索的时候,指定了索引搜索,就会导致新建的索引无法生效,假如删除了指定的索引,会导致程序崩溃,所以建议不采用指定索引进行搜索。
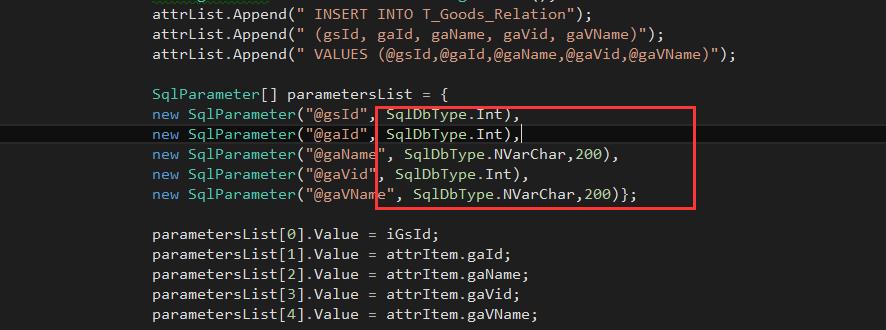
(14)变量/参数/关联字段类型必须与字段类型一致
所谓的变量、参数、关联字段类型一致指的是,数据库中是什么类型,那么我们在成程序中传入参数的过程中,建议保持一直,避免在查询的时候,进行类型转换,在大批量数据处理过程中,可能影响性能。
图1类型:(程序中类型)
图二类型:(数据中类型)
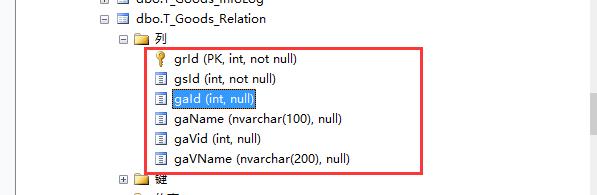
图1、图2中字段类型保持一致。
(15)参数化查询
所谓的“参数化SQL”就是在应用程序设置SqlCommand.CommandText的时候使用参数(如:param1),然后通过SqlCommand.Parameters.Add来设置这些参数的值。这种做法会把你准备好的命令通过sp_executesql系统存储过程来执行,使用参数化,最直接的好处就是防止SQL注入。也就是说使用这种方法,主要是为了保证数据库的安全。禁止拼接sql语句。
另外参数化查询有利于数据库查询计划的复用,比如我们查询注册日期大于2015-12-12和注册日期大于2016-12-12不同的店铺记录,我们可能这样写:
select * from T_Account where Regtime>\'2015-12-12\' select * from T_Account where Regtime>\'2016-12-12\'上面两条语句,可以完成我们上面的查询结果集,但是sql查询计划会进行两次分析,导致查询计划不能够复用,如果用参数化查询,则可以复用查询计划:
declare @Regtime datetime; set @Regtime=\'2015-12-12\'; select * from T_Account where Regtime>@Regtime set @Regtime=\'2016-12-12\'; select * from T_Account where Regtime>@Regtime只需要改变参数的值就可以了。
(16)限制JOIN个数
join表的次数不要过多,写代码的人,看到过多的join表记录都会懵逼,何况数据库了?会导致数据库执行错误的执行计划,影响性能。
(17)关闭影响的行计数信息返回
在sql语句中,可以设置Set NoAccount on,关闭查询受影响的行数,从而减少流量。
(18)除非必要SELECT语句都必须加上NOLOCK
这个是我们经常在开发中忽略的,加上nolock以后,在查询的时候,不锁表。不要只要自己爽,别人也要查询数据的,占这茅坑不拉shi是不好哦。这也是我们内部工程师的必修课提高的。
(19)使用UNION ALL替换UNION
使用union 的时候,必须满足两个表具体相同数目的列。
union all 包含全部的记录,union 包含去除重复后的结果集
Employees_China:
| E_ID| E_Name|
| :-------- | --------:|
| 01| Zhang, Hua|
| 02| Wang, Wei|
| 03| Carter, Thomas|
| 04| Yang, Ming|
Employees_USA:
E_ID E_Name 01 Adams, John 02 Bush, George 03 Carter, Thomas 04 Gates,Bill
使用 UNION 命令 列出所有在中国和美国的不同的雇员名: SELECT E_Name FROM Employees_China UNION SELECT E_Name FROM Employees_USA结果集:
> Zhang, Hua Wang, Wei Carter, Thomas Yang, Ming Adams, John Bush, George Gates, Bill
使用 UNION ALL 命令 列出在中国和美国的所有的雇员: SELECT E_Name FROM Employees_China UNION ALL SELECT E_Name FROM Employees_USA结果集:
> Zhang, Hua Wang, Wei Carter, Thomas Yang, Ming Adams, John Bush, George Carter, Thomas Gates, Bill
(20)查询大量数据使用分页或TOP
通过分页批量获取数据,避免全表扫描。
在.Net中,我们可以这样写来分页获取数据,通过分页获取图片数据,进行地址替换操作。
/// <summary> /// 批量替换图片地址 /// </summary> /// <param name="index"></param> /// <param name="size"></param> public static void BatchReplaceImgAddress(int index, int size) { const string strSql = "select Id,AccId,ImgAddress from (select ROW_NUMBER() OVER ( ORDER BY id ) as rownumber,id as Id,accid as AccId,ge_Details as ImgAddress " + "from t_GoodsExtend (nolock) ) as T where rownumber BETWEEN (@index-1)*@size+1 AND @size*@index"; var imgAddressesItems = DapperHelper.Query<ImgAddressModel>(strSql, new { index = index, size = size }).ToList(); if (!imgAddressesItems.Any()) { return; } try { Console.WriteLine("正在处理{0}~{1}条数据:", (index - 1)*size + 1, ((index - 1)*size) + size); foreach (var item in imgAddressesItems) { var imgItem = item; if (string.IsNullOrWhiteSpace(imgItem.ImgAddress)) continue; var imgAddress = imgItem.ImgAddress; const string targetReplaceStr = "baidu.com/umupload"; const string targetNewStr = "baidu.com/mobileweb/detail2"; if (imgAddress.Contains(targetReplaceStr)) { var newImgAddress = imgAddress.Replace(targetReplaceStr, targetNewStr); const string updateImgStrSql = "update t_GoodsExtend set ge_Details = @ge_Details where id= @id"; var updateResult = DapperHelper.Execute(updateImgStrSql, new { id = imgItem.Id, ge_Details = newImgAddress, }); if (updateResult > 0) { var message = string.Format("当前的店铺Id为:{0},处理记录的Id为:{1}", imgItem.AccId,imgItem.Id); Console.WriteLine(message); SimpleLog.Instance.WriteLogForFile("批量替换图片地址日志", message); } } } } catch (Exception ex) { SimpleLog.Instance.WriteLogForFile("批量替换图片地址异常", ex); } BatchReplaceImgAddress(index + 1, size); }(21)NOT EXISTS替代NOT IN
1、in和exists in是把外表和内表作hash连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询,一直以来认为exists比in效率高的说法是不准确的。如果查询的两个表大小相当,那么用in和exists差别不大;如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in; 例如:表A(小表),表B(大表) select * from A where cc in(select cc from B) -->效率低,用到了A表上cc列的索引; select * from A where exists(select cc from B where cc=A.cc) -->效率高,用到了B表上cc列的索引。 相反的: select * from B where cc in(select cc from A) -->效率高,用到了B表上cc列的索引 select * from B where exists(select cc from A where cc=B.cc) -->效率低,用到了A表上cc列的索引。 2、not in 和not exists not in 逻辑上不完全等同于not exists,如果你误用了not in,小心你的程序存在致命的BUG,请看下面的例子: create table #t1(c1 int,c2 int); create table #t2(c1 int,c2 int); insert into #t1 values(1,2); insert into #t1 values(1,3); insert into #t2 values(1,2); insert into #t2 values(1,null); select * from #t1 where c2 not in(select c2 from #t2); -->执行结果:无 select * from #t1 where not exists(select c2 from #t2 where #t2.c2=#t1.c2) -->执行结果:1 3 正如所看到的,not in出现了不期望的结果集,存在逻辑错误。如果看一下上述两个select 语句的执行计划,也会不同,后者使用了hash_aj,所以,请尽量不要使用not in(它会调用子查询),而尽量使用not exists(它会调用关联子查询)。如果子查询中返回的任意一条记录含有空值,则查询将不返回任何记录。如果子查询字段有非空限制,这时可以使用not in,并且可以通过提示让它用hasg_aj或merge_aj连接。 如果查询语句使用了not in,那么对内外表都进行全表扫描,没有用到索引;而not exists的子查询依然能用到表上的索引。所以无论哪个表大,用not exists都比not in 要快。 3、in 与 = 的区别 select name from student where name in(\'zhang\',\'wang\',\'zhao\'); 与 select name from student where name=\'zhang\' or name=\'wang\' or name=\'zhao\' 的结果是相同的。(22)尽量避免使用OR运算符
举例说明我们在查找当当前是行业版和高级版店铺的账号时,我们可能会这样写:
select id from T_Account where id in( select accountId from T_Bussiness where aotjob=3 or aotjob=5 )where后面使用了aotjob=3 or aotjob=5,这样会导致数据库查询无法命中索引,会走全表扫描。所以在这里我们使用in则会比较好:
select id from T_Account where id in( select accountId from T_Bussiness where aotjob in (3,5) )(23)like的查询的索引
1.[Col1] like "abc%" --index seek 这个就用到了索引查询 2.[Col1] like "%abc%" --index scan 而这个就并未用到索引查询 3.[Col1] like "%abc" --index scan 这个也并未用到索引查询我想从上而三个例子中,大家应该明白,最好不要在LIKE条件前面用模糊匹配,否则就用不到索引查询。
2.合理使用NULL属性
新加的表,所有字段禁止NULL
(新表为什么不允许NULL?
允许NULL值,会增加应用程序的复杂性。你必须得增加特定的逻辑代码,以防止出现各种意外的bug
三值逻辑,所有等号(“=”)的查询都必须增加isnull的判断。
Null=Null、Null!=Null、not(Null=Null)、not(Null!=Null) 都为unknown,不为true
举例来说明一下:
如果表里面的数据如图所示:
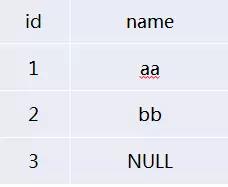
你想来找查找除了name等于aa的所有数据,然后你就不经意间用了
SELECT * FROM USERS WHERE NAME<>’aa’结果发现与预期不一样,事实上它只查出了name=bb而没有查找出name=NULL的数据记录
那我们如何查找除了name等于aa的所有数据,只能用ISNULL函数了
SELECT * FROM USERS WHERE ISNULL(NAME,1)<>’aa’但是大家可能不知道ISNULL会引起很严重的性能瓶颈 ,所以很多时候最好是在应用层面限制用户的输入,确保用户输入有效的数据再进行查询。
旧表新加字段,需要允许为NULL(避免全表数据更新 ,长期持锁导致阻塞)(这个主要是考虑之前表的改造问题)
3.理解执行计划
所谓的执行计划,就是数据库根据sql语句生成的一个执行顺序。先执行什么,再执行什么。类似于我们的工作计划,先做什么,后做什么,从而使我们的效率达到最高。所以合理的执行计划,会让数据库干正确的事,提高效率。
在我们使用sql查询的时候,通常是根据sql内部的查询计划来进行的,也就是说不同的sql语句生成的查询计划不同,所以要优化sql,我们写出的sql要让数据库能够生成正确执行计划,才能提高性能;反之写出的sql语句,不容易被数据库翻译成合理的执行计划,就容易导致性能瓶颈。
例如:
select id from T_Accountselect id From T_Account这两句查询语句我们可以看出只是from关键字大小的区别,但是查询分析器会认为是不同的语句,进行两次解析。所以针对同一个查询语句,在不同的地方我们应该保持一致,大小写一致,查找字段一致。在数据库中针对查询,数据库会缓存查询计划,如果查询的时候,存在已经解析的查询计划,就会按照存在的查询计划走,这样就节省了解析生成查询计划的时间,提高了查询性能。
三.总结
关于查询计划,准备细致的学习一下,明白不同查询计划具体的含义。从而可以进行对应的优化。上面讲到不对的地方,希望大家指出,一起学习,一起进步!