hadoop三大核心组件介绍
Posted 风中雨雨中路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop三大核心组件介绍相关的知识,希望对你有一定的参考价值。
1.1 Hadoop是什么
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台
1.2 核心组件
-
分布式存储系统 HDFS(Hadoop Distributed File System),提供了高可靠性、高扩展性和高吞吐率的数据存储服务;
-
分布式计算框架 MapReduce,具有易于编程、高容错性和高扩展性等优点;
-
分布式资源管理框架 YARN(Yet Another Resource Management),负责集群资源的管理和调度。
Hadoop 的生态系统中包含多种技术:
Apache Hadoop: 是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。
Apache Hive: 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Apache HBase: 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
Apache Sqoop: 是一个用来将HDFS和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(mysql ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Apache Zookeeper: 是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。
Apache Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
Apache Avro: 是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
Apache Chukwa: 是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合 Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各种 MapReduce 操作。
Apache Hama: 是一个基于HDFS的BSP(Bulk Synchronous Parallel)并行计算框架, Hama可用于包括图、矩阵和网络算法在内的大规模、大数据计算。
Apache Flume: 是一个分布的、可靠的、高可用的海量日志聚合的系统,可用于日志数据收集,日志数据处理,日志数据传输。
Apache Oozie: 是一个工作流引擎服务器, 用于管理和协调运行在Hadoop平台上(HDFS、Pig和MapReduce)的任务。
Cloudera Hue: 是一个基于WEB的监控和管理系统,实现对HDFS,MapReduce/YARN, HBase, Hive, Pig的web化操作和管理。
还有其他分布式计算框架如:spark、flink,以及其他组件
1.3 优点
-
扩容能力(Scalable):Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
-
成本低(Economical):Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
-
高效率(Efficient):通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
-
可靠性(Rellable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
2、HDFS
全称:分布式存储系统 HDFS(Hadoop Distributed File System),是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
2.1 存储模型
-
文件线性切割成块(Block):大文件切分为小文件
-
偏移量 offset(byte):每一个块的起始位置相对于原始文件的字节索引
-
Block 分散存储在集群节点中,单一文件 Block 大小一致,文件与文件之间 Block 大小可以不一致,Block 可以设置副本数,副本分散在不同节点中,副本数不要超过节点数量,文件上传可以设置 Block 大小和副本数,已上传的文件 Block 副本数可以调整,大小不变,块大小默认是128M,可以调整
-
只支持一次写入多次读取(修改是泛洪操作,集群开销很大,所有不允许在块中增删改操作),同一时刻只有一个写入者
-
可以 append 追加数据(加块,单点操作)
2.2 架构模型
这里介绍的是Hadoop2.x,介绍的是HA,采取主备NN模式的Hadoop集群
数据分为两部分:文件元数据、文件数据
-
元数据:理解为文件的属性,比如权限、修改日期,文件名等
-
NameNode 节点(主)保存文件元数据:单节点
-
-
数据本身:理解为文件中的内容
-
DataNode 节点(从)保存文件Block 数据:多节点
-
DataNode 与 NameNode 保持心跳,提交 Block 列表
-
HdfsClient 与 NameNode 交互元数据信息
-
HdfsClient 与 DataNode 交互文件 Block 数据
-
HA模式架构图如下
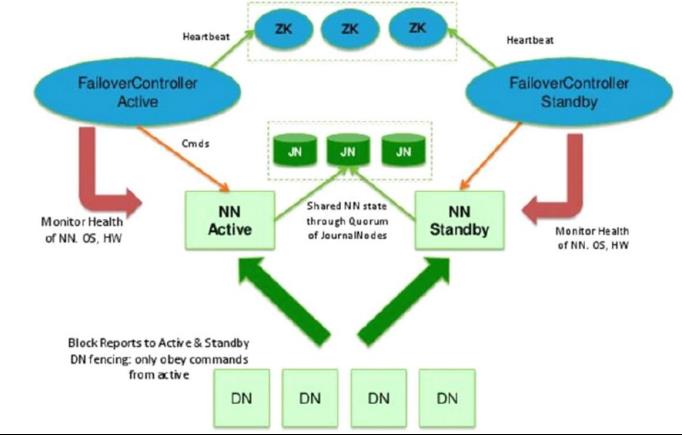
2.2.1 NameNode (NN)
基于内存存储,不会和磁盘发生交换,只存在内存中,但也有持久化的功能,只是单方向的存储,防止断电丢失,不会发生内存和磁盘的交换,NameNode 的 metadate 信息在启动后会加载到内存,metadata 存储到磁盘文件名为fsimage,Block 的位置信息不会保存到 fsimage,由 DataNode 汇报,edits记录对 metadata 的操作日志。
NameNode 主要功能:
接受客户端的读写服务,收集 DataNode 汇报的 Block 列表信息,NameNode 保存。metadata 信息包括:文件owership、permissions、文件大小、时间、Block 列表、Block 偏移量和位置信息(副本位置由 DataNode 汇报,实时改变,不会持久化)等。
-
ANN:ActiveNameNode,对外提供服务,SNN 同步 ANN 元数据,以待切换。
-
SNN:StandbyNameNode,完成了 edits.log 文件的合并产生新的 fsimage,推送回 ANN。
-
两个NN 之间的切换:
-
手动切换:通过命令实现主备之间的切换,可以用 HDFS 升级等场合。
-
自动切换:基于 Zookeeper 实现。HDFS 2.x 提供了 ZookeeperFailoverController 角色,部署在每个NameNode 的节点上,作为一个 deamon 进程, 简称 zkfc。
-
2.2.2 ZKFC
全称:ZookeeperFailoverController,包括以下三个组件:
-
HealthMonitor:监控 NameNode 是否处于 unavailable 或 unhealthy 状态。当前通过RPC 调用 NN 相应的方法完成。
-
ActiveStandbyElector:管理和监控自己在 ZK 中的状态。
-
ZKFailoverController:它订阅 HealthMonitor 和 ActiveStandbyElector 的事件,并管理NameNode 的状态。
主要职责:
-
健康监测:周期性的向它监控的 NN 发送健康探测命令,从而来确定某个NameNode 是否处于健康状态,如果机器宕机,心跳失败,那么 zkfc 就会标记它处于一个不健康的状态
-
会话管理:如果 NN 是健康的,zkfc 就会在 zookeeper 中保持一个打开的会话,如果 NameNode 同时还是 Active 状态的,那么 zkfc 还会在 Zookeeper 中占有一个类型为短暂类型的 znode,当这个 NN 挂掉时,这个 znode 将会被删除,然后备用的NN,将会得到这把锁,升级为主 NN,同时标记状态为 Active,当宕机的NN 新启动时,它会再次注册 zookeper,发现已经有 znode 锁了,便会自动变为 Standby状态,如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置 2 个NN.
-
master 选举:如上所述,通过在 zookeeper 中维持一个短暂类型的 znode,来实现抢占式的锁机制,从而判断那个NameNode 为 Active 状态。
-
2.2.3 DataNode(DN)
使用本地磁盘目录以文件形式存储数据(Block),同时存储 Block 的元数据信息文件(校验和,用于检测数据块是否损坏),启动 DN 时会向 两个NN 汇报 block 信息的位置,通过向NN发送心跳保持与其联系(3 秒一次),如果NN 10 分钟没有收到 DN 的心跳,则认为其已经 lost,并 copy 其上的 block 到其它 DN。
副本放置策略
-
第一个副本:放置在上传文件的 DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU 不太忙的节点。
-
第二个副本:放置在于第一个副本不同的机架的节点上。第三个副本:与第二个副本相同机架的节点。
-
更多副本:随机节点。
2.2.4 JournalNode(JNN)
ANN 和 SNN 通过 JNN 集群来共享信息。两个NameNode 为了数据同步,会通过一组称作 JournalNodes 的独立进程进行相互通信。当 ANN 的命名空间有任何修改时,会告知大部分的 JournalNodes 进程。SNN 有能力读取 JNs 中的变更信息,并且一直监控 edit log 的变化,把变化应用于自己的命名空间。SNN 可以确保在集群出错时,命名空间状态已经完全同步了,为了保持 SNN 实时的与 ANN 的元数据保持一致,他们之间交互通过一系列守护的轻量级进程 JournalNode。基本原理就是用 2N+1 台 JN 存储editlog,每次写数据操作有超过半数(>=N+1)返回成功时即认为该次写成功,数据不会丢失了。当然这个算法所能容忍的是最多有 N 台机器挂掉,如果多于 N 台挂掉,这个算法就失效了。任何修改操作在 ANN上执行时,JN 进程同时也会记录修改 log 到至少半数以上的 JN 中,这时 SNN 监测到 JN 里面的同步 log 发生变化了会读取 JN 里面的修改 log,然后同步到自己的的目录镜像树里面。当发生故障时,ANN 挂掉后,SNN 会在它成为ANN 前,读取所有的 JN 里面的修改日志,这样就能高可靠的保证与挂掉的 NN 的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的。
2.3 HDFS 写流程
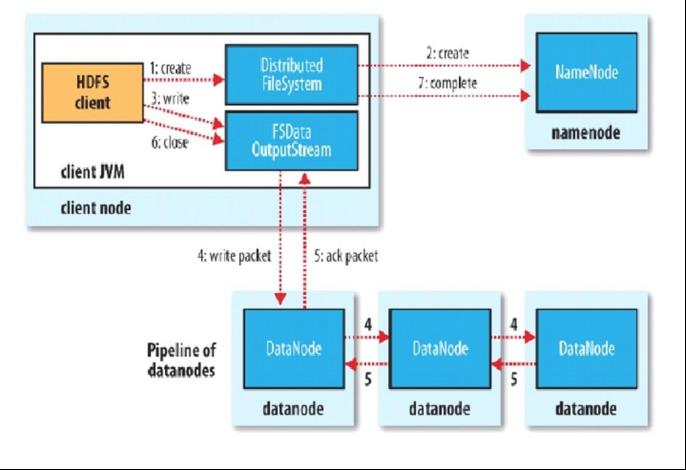
-
客户端创建 DistributedFileSystem 对象.
-
DistributedFileSystem 对象调用元数据节点,在文件系统的命名空间中创建一个新的文件,元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件,并标识为“上传中”状态,即可以看见,但不能使用。
-
DistributedFileSystem 返回 DFSOutputStream,客户端用于写数据。
-
客户端开始写入数据,DFSOutputStream 将数据分成块,写入 data queue(Data
-
queue 由 Data Streamer 读取),并通知元数据节点分配数据节点,用来存储数据块(每块默认复制 3 块)。分配的数据节点放在一个 pipeline 里。Data Streamer将数据块写入 pipeline 中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。注意:并不是第一个数据节点完全接收完 block 后再发送给后面的数据节点,而是接收到一部分就发送,所以三个节点几乎是同时接收到完整的 block 的。DFSOutputStream 为发出去的数据块保存了 ack queue,等待 pipeline 中的数据节点告知数据已经写入成功。如果 block 在某个节点的写入的过程中失败:关闭 pipeline,将 ack queue 放至 data queue 的开始。已经写入节点中的那些 block 部分会被元数据节点赋予新的标示,发生错误的节点重启后能够察觉其数据块是过时的,会被删除。失败的节点从 pipeline 中移除,block 的其他副本则写入 pipeline 中的另外两个数据节点。元数据节点则被通知此 block 的副本不足,将来会再创建第三份备份。
-
ack queue 返回成功。
-
客户端结束写入数据,则调用 stream 的 close 函数,最后通知元数据节点写入完毕
总结:
客户端切分文件 Block,按 Block 线性地和 NN 获取 DN 列表(副本数),验证 DN 列表后以更小的单位流式传输数据,各节点两两通信确定可用,Block 传输结束后,DN 向 NN汇报Block 信息,DN 向 Client 汇报完成,Client 向 NN 汇报完成,获取下一个 Block 存放的DN 列表,最终 Client 汇报完成,NN 会在写流程更新文件状态。
2.4 HDFS 读流程
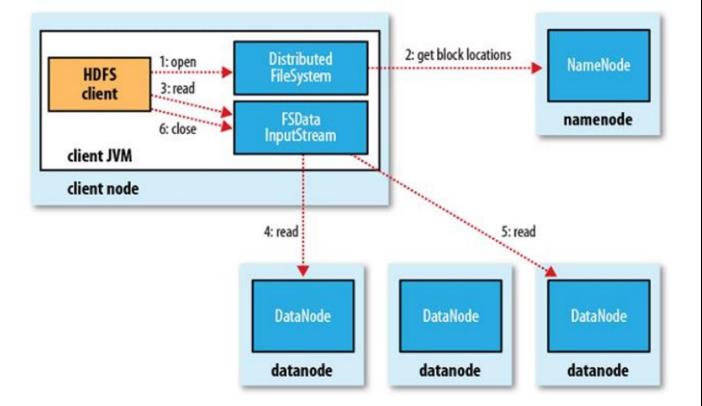
-
客户端(client)用 FileSystem 的 open()函数打开文件。
-
DistributedFileSystem 调用元数据节点,得到文件的数据块信息。对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
-
DistributedFileSystem 返回 FSDataInputStream 给客户端,用来读取数据。
-
客户端调用 stream 的 read()函数开始读取数据(也会读取 block 的元数据)。
DFSInputStream 连接保存此文件第一个数据块的最近的数据节点(优先读取同机架的 block)。
-
Data 从数据节点读到客户端。当此数据块读取完毕时,DFSInputStream 关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
-
当客户端读取完毕数据的时候,调用 FSDataInputStream 的 close 函数。
-
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。失败的数据节点将被记录,以后不再连接。
总结:
客户端和NN 获取一部分 Block(获取部分 block 信息,而不是整个文件全部的 block 信息,读完这部分 block 后,再获取另一个部分 block 的信息)副本位置列表,线性地和 DN获取Block,最终合并为一个文件,在 Block 副本列表中按距离择优选取。
2.5 HDFS 优点
-
高容错性:数据自动保存多个副本,副本丢失后,自动恢复
-
适合批处理:移动计算而非数据,数据位置暴露给计算框架(Block 偏移量)
-
适合大数据处理:GB 、TB 、甚至 PB 级数据,百万规模以上的文件数量,10K+节点数量
-
可构建在廉价机器上:通过多副本提高可靠性,提供了容错和恢复机制
2.6 HDFS 缺点
-
低延迟数据访问:HDFS 不太适合于那些要求低延时(数十毫秒)访问的应用程序,因为 HDFS 是设计用于大吞吐量数据的,这是以一定延时为代价的。HDFS 是单 Master 的,所有对文件的请求都要经过它,当请求多时,肯定会有延时。
-
小文件存取时占用NameNode 大量内存,寻道时间超过读取时间
-
一个文件只能有一个写者,且仅支持 append
3、MapReduce
3.1、概念
MapReduce是分布式计算框架,由于计算过程需要反复操作磁盘,适用于离线计算,批计算,大规模的数据量计算。
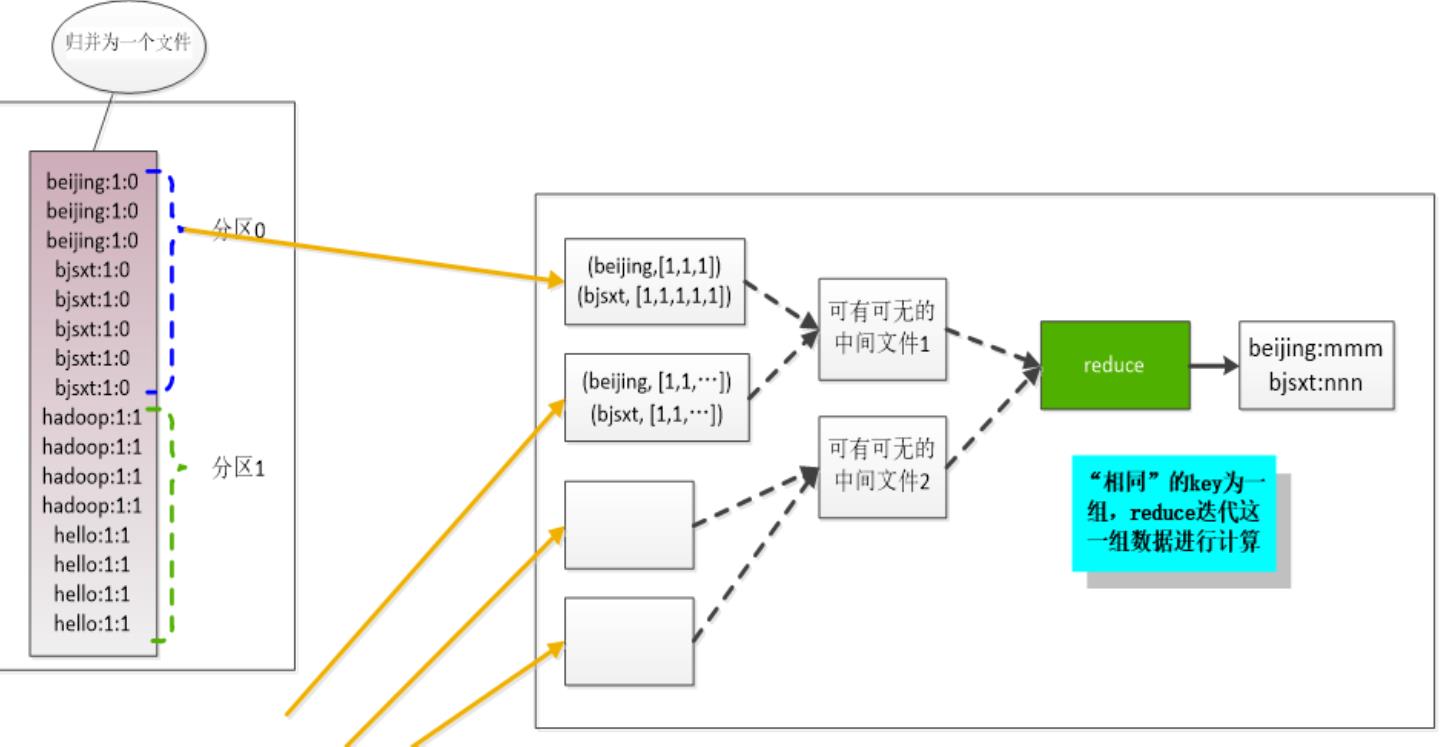
原语:“相同”的key为一组,调用一次reduce方法,方法内迭代这一组数据进行计算。这也是MapReduce的核心思想。
3.2、 逻辑
MapReduce只有两个逻辑,map和reduce
-
map
-
读取数据
-
将数据映射成kv格式
-
并行分布式
-
计算向数据移动
-
-
reduce
-
数据全量/分量加工
-
reduce中可以包括不同的key
-
相同的key汇聚到一个reduce中
-
相同的key调用一次reduce方法
-
排序实现key的汇聚
-
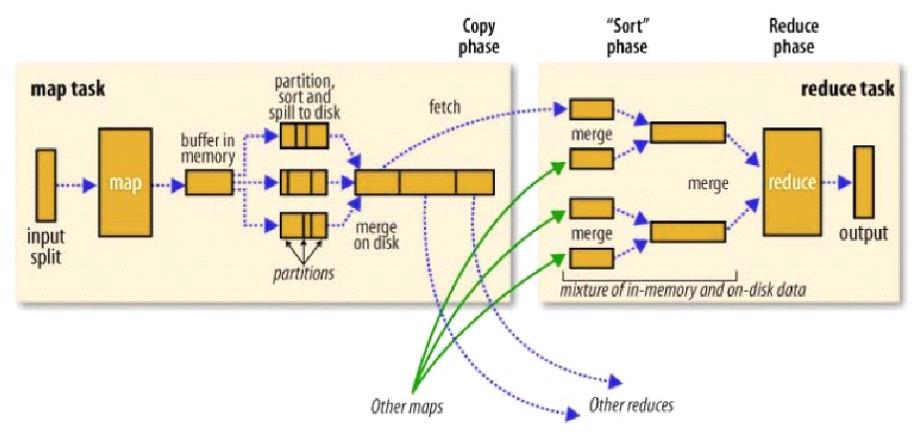
3.3、MR执行流程
-
先根据hdfs中的数据的block来进行切片操作,默认切片大小等于block块大小---决定了maptask的个数
-
执行map的处理逻辑,最终的数据结果是kv格式
-
kv格式的数据首先会写入一个100M的buffer缓冲区,当达到80%开始进行溢写成文件,溢写的时候会进行sort,相同key的数据汇聚到一起
-
最终map执行完成之后会有N多个溢写的小文件
-
将小文件进行一个merge操作,将N个小文件中相同的key的数据汇聚到一起
-
reduce端处理数据之前会从不同的map节点中拉取数据
-
拉取完数据之后,会对这些文件进行合并操作,将相同key的数据汇聚
-
reduce读取到的是相同key的iterator
-
对iterator中的数据进行合并操作
图解:
Shuffler<洗牌>:框架内部实现机制
分布式计算节点数据流转:连接MapTask与ReduceTask
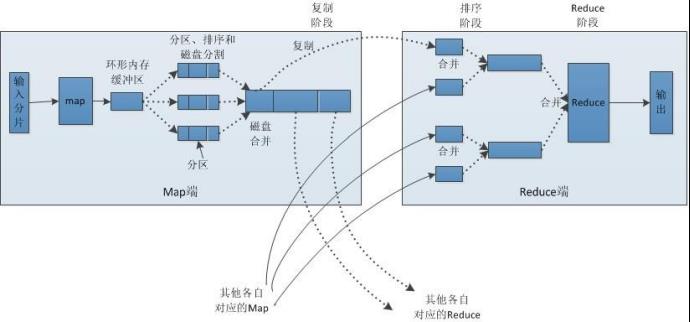
4、Yarn
yarn是Hadoop2.x 出现的概念,资源调度框架,它负责整个集群计算时的资源管理分配。
架构图:
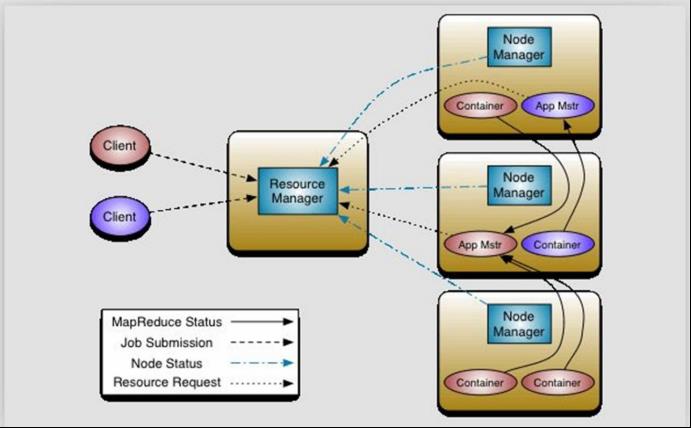
YARN:解耦资源与计算
ResourceManager:主,核心,集群节点资源管理
NodeManager:与 RM 汇报资源,管理 Container 生命周期,计算框架中的角色都以
Container 表示其中信息包括节点 NM,CPU,MEM,I/O 大小,启动命令等,默认
NodeManager 启动线程监控 Container 大小,超出申请资源额度,则 kill,支持 Linux 内核的 Cgroup
MR :MR-ApplicationMaster-Container,作业为单位,避免单点故障,负载到不同的节点,创建 Task 需要和RM 申请资源(Container),
Task:也是运行在 Container 中
Client:RM-client:请求资源创建AM AM-Client 与AM交互
以上是关于hadoop三大核心组件介绍的主要内容,如果未能解决你的问题,请参考以下文章