REDIS CLUSTER 搭建,扩容缩容基本原理
Posted 从零开始的DBA生活
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了REDIS CLUSTER 搭建,扩容缩容基本原理相关的知识,希望对你有一定的参考价值。
摘要
在redis4.0.14版本,是通过ruby的工具redis-trib.rb工具进行扩容缩容以及集群搭建的工作,然后到redis5.0后取消了这个工具的功能并合并到redis-cli中,这里就让我们了解一下redis-trib.rb工具在搭建集群和扩容缩容中到底做了什么把
源码在github 上搜索redis,第一个就是了,这里就不贴代码了
1. Redis4.0 不使用redis-trib.rb工具搭建cluster
1.1 redis redis-trib.rb create方法分析
| 步骤 | 作用 |
| node = ClusterNode.new(n) | 初始化,n是node,对节点信息初始化 |
| node.connect(:abort => true) | 连接节点 |
| node.assert_cluster | 判断节点信息,看cluster_enabled是否开启 |
| node.load_info | 如果节点已经有slot,则对该节点执行addslot命令,设置节点的cluster info信息 |
| node.assert_empty |
验证该节点的cluster_known_nodes是否为1 和验证 该节点的db0是否为空 如果cluster_known_nodes不为1则认为已经加入其他集群,如果db0不为空则认为该节点不为空不能加入该集群 |
| add_node(node) | @nodes << node 把该node节点加入@nodes数组 |
| 把所有节点按以上流程走一遍,再开始执行下面 | |
| check_create_parameters |
masters = @nodes.length/(@replicas+1) 计算master 节点,@replicas代表每个主有多少个从 如果是一主二从的集群,master的结点数=用节点数/2+1 所以一主二从的集群起码要9个节点,才能搭建cluster |
| alloc_slots |
先维护一个字典,每个node的ip为键,所有的nodes的信息为值(一个字典),把nodes加入字典中 ips[n.info[:host]] = [] if !ips[n.info[:host]] ips[n.info[:host]] << n 选择命令的前3个作为master节点 计算每个每个节点分配多少槽(ClusterHashSlots.to_f / masters_count) 然后调用addslots方法,其实就是把要分配的slots 遍历加入节点的对象(一个字典)中的key[slots]中,每个master节点都执行一个分配槽的操作 |
| show_nodes | 输出槽的分配结果 |
1.2 搭建过程
## step 1
## 以第一点的配置启动6个节点
## redis-server /usr/conf/cluster/7000.conf
## redis-server /usr/conf/cluster/7001.conf
## .....................................................................
## redis-server /usr/conf/cluster/7005.conf
## step 2
## redis-cli -p 7001 -c (随便进入一个集群)
## 执行cluster meet / redis-trib.rb add nodes 把其他节点加入集群

## 查看集群的节点信息
## cluster nodes

## step 4
## 挑选前3个节点作为master
## 16384 / 3 = 5461.333
## 先给第一个master几点分配 5461个节点
## redis-cli -p 7001 -c cluster addslots {0..5460}

## 第二个节点分配的位置的初始位置为5461,结束为5461+5461 =10922
## redis-cli -p 7003 -c cluster addslots {5461..10922}

## 第三个节点分配的位置的初始位置为10923,last = 16384-1
## redis-cli -p 7000 -c cluster addslots {10923..16838}

## step 5
## 给master 节点设置slave节点
## 分别进入3个没有槽的节点 执行cluster replicate
## redis-cli -p 7002 -c cluster replicate 9222d226718a707c4517e634dfe38e81c026986c
## redis-cli -p 7005 -c cluster replicate 403b709820b1deeea8eab0744c76f928b53b7e86
## redis-cli -p 7004 -c cluster replicate 7bca1a86e03c7c176a8298c34ff363b7100d21d8

## step 6
## 查看每个节点的集群状态
## redis-cli -p 7000 -c cluster info
## redis-cli -p 7001 -c cluster info
## redis-cli -p 7002 -c cluster info

## 确认每个节点的集群状态,因为加入A节点的槽部分不可用,A的cluster_state的状态会为fail,其他节点的clutser_state会显示ok
2.Redis4.0 不使用redis-trib.rb工具对集群进行扩容缩容
2.1 redis-trib.rb reshard 方法
|
ALL的分配方式顺序
|
作用
|
|---|---|
|
遍历所有节点,过滤掉slave的节点,和接收槽的节点 把剩余的节点加入sources数组中,作为槽的来源节点 |
|
|
多个槽来源的计算方式: 1.先对来源槽进行排序, 2 计算每个节点要移出多少个槽 (numslots.to_f/source_tot_slots*s.slots.length) 这样的处理方式会带来最终分配的slot与请求迁移的slot数量不一致 3. 计算出每个节点需要移出的槽数 4. 遍历每个节点的所需要移出的槽,加入move数组中 move = [] move << {:source=>s,slot=>slot} 要移动的槽全部放进数组中 |
numslots.to_f 总共要移动的槽数 source_tot_slots 所有来源节点的槽数 s.slots.length 单个来源节点拥有的槽数 没记错是入栈出栈的计算方式 先计算numslots.to_f/source_tot_slots 再算 *s.slots.length |
|
target.r.cluster("setslot",slot,"importing",source.info[:name]) source.r.cluster("setslot",slot,"migrating",target.info[:name]) migrate ...迁移键 n.r.cluster("setslot",slot,"node",target.info[:name]) |
每个槽使用importing导出,然后再移动到接收槽上 源节点和目标节点都执行cluster setslot ... node ... |
2.2 扩容介绍
## step 1
## redis-server 启动两个节点,一个主一个从
## redis-server /usr/conf/cluster/7006.conf
## redis-server /usr/conf/cluster/7007.conf
## netstat -lnp | grep redis

## 新启动了两个节点
## step 2
## 进入集群中的任意带槽的节点节点
## redis-cli -p 7003 -c
## 把新启动的节点加入集群
## cluster meet 127.0.0.1 7006
## cluster meet 127.0.0.1 7007
## cluster nodes

## 成功把两个节点加入集群
## step 3 扩容
## 扩容,给新的一个master 节点分配槽
## 多个来源节点的情况
## 遍历每个节点,计算每个节点应该移出多少个槽 (numslots.to_f/source_tot_slots*s.slots.length)
## numslots.to_f 总共要移动的槽数
## source_tot_slots 所有来源节点的槽数
## s.slots.length 单个来源节点拥有的槽数
## 循环每个slot:
## 接收节点执行 cluster setslot <slot> importing <node_id> (node_id为源节点id)
## 来源节点执行 cluster setslot <slot> migrating <node_id> (node_id为接收节点id)
## 源节点执行 cluster countkeysinslot <slot> 查看要移动的槽 有没有键
## 如果有 则 继续执行 cluster getkeysinslot <slot> <count> 查看slot节点的多少个key值, 如果上一步槽的键数量为空跳过此步骤
## 然后执行 MIGRATE 源节点ip 源节点port "" 0 5000 KEYS key1 key2 key3 把键先迁移,执行这条命令后该键不可读不可写
## 分别在源节点和接收节点执行 cluster setslot <slot> node <node_id>
## 现在看 主要在接收节点上执行 cluster setslot ...node ...命令,只有在接收节点上面执行后会跟新接收节点的epoch 版本号,然后发消息跟其他节点说该slot已经归我管了,如果epoch比接收信息的节点高,接收信息的节点会跟新该slot的状态
## 而源节点上面执行cluster setslot .... node ...命令只移除mirating flag 并不会更新版本号
## 那么问题来了,那importing 和migrating 步骤不就可以省略吗,那源节点也没必要执行cluster setslot ... node ...命令了(其实并不是这样,详见测试)
2.3 扩容实例

把7373 节点从 7004 移动到7009
## step 1
## redis-cli -p 7009 -c cluster setslot 7373 importing cd8cd114215e4c2869d6d31ae7fe5f5cff922ed3
## 从其他节点观察槽信息
## redis-cli -p 7009 -c cluster nodes | grep master | sort -t \' \' -k2

## 从7009 节点上看到设置了一个importing flag (-<-)
## redis-cli -p 7004 -c cluster nodes | grep master | sort -t \' \' -k2

## 在7004 上面没有变化
## redis-cli -p 7003 -c cluster nodes | grep master | sort -t \' \' -k2

## 在7003 上面没有变化
##往槽7373 插入数据
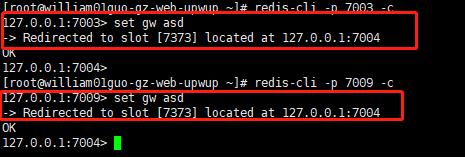
## 说明槽还在 7004 上面
## step 2
## redis-cli -p 7004 -c cluster setslot 7373 migrating 273289d0a17cd30fecc7a3db6fb2fd1cb06b3e55
## 从其他节点观察槽信息
## redis-cli -p 7009 -c cluster nodes | grep master | sort -t \' \' -k2

## 7009 上面仍然只看到自己身上只有一个importing flag,7373槽仍然在7004 上面
## redis-cli -p 7004 -c cluster nodes | grep master | sort -t \' \' -k2 
## 7004 上面看到自己多出一个mirating flag,7373槽仍然在7004 上面
## redis-cli -p 7003 -c cluster nodes | grep master | sort -t \' \' -k2

## 7003 仍然没变化
## redis-cli -p 7003 -c get gw

## 7373槽仍在在7004上面
## step 3
## redis-cli -p 7004 -c cluster countkeysinslot 7373
## 查看槽7373 有多少个key,必须在源节点上面执行

## 7373 上面有一个key
## step 4
## redis-cli -p 7004 -c cluster getkeysinslot 7373 1

## 7373槽上面只有一个key gw,必须在源节点上面执行
## step 5
## redis-cli -p 7004 -c MIGRATE 127.0.0.1 7009 "" 0 5000 KEYS gw
## 把槽7373的键从7004 移动到 7009
## redis-cli -p 7004 -c get gw
## redis-cli -p 7004 -c set gw qwes

## 执行完migrate 后键也不可访问
## 因为执行 setslot migrating 和setslot importing之后,旧的键可以在源节点上访问,但是新的键设置只能在新节点上面执行asking后执行设置新键命令才能成功
## 这样保证了 setslot migrating 和setslot importing之后不会在源节点上设置新键值对,避免setslot ,,,node,,, 后新键值丢失
## 由于mirate命令命令把旧键移动到接收节点上去,所以现在源节点上已经没有旧键了,这个时候,所有键的访问都必须在接收节点上执行asking后执行操作
## 例如:
## redis-cli -p 7009 -c
## asking
## set sand aksnd
## 才会成功
## step 6
## redis-cli -p 7004 -c cluster setslot 7373 node 273289d0a17cd30fecc7a3db6fb2fd1cb06b3e55
## redis-cli -p 7004 -c cluster nodes | grep master | sort -t \' \' -k2

## 从7004节点上面看,原本7004 上面的migrating flag 没有了,7373槽已经移动到 7009 上面去
## redis-cli -p 7009 -c cluster nodes | grep master | sort -t \' \' -k2

## 从 7009 上面看 importing flag 还没被消除, 7373slot 仍然在7004上面
## redis-cli -p 7003 -c cluster nodes | grep master | sort -t \' \' -k2

## 从7003 上面看 7373 仍然在 7004 上面
## get gw
## set gw asd

## 在 7003和7004 上面反复横跳
##注意,这里先在源节点上面执行setslot.... node....命令
## 形成原因

## 无论从哪个节点上面访问都会导致这种情况,这是由于每个节点信息不同步 或者说数据不一致导致的
## step 7
## redis-cli -p 7009 -c cluster setslot 7373 node 273289d0a17cd30fecc7a3db6fb2fd1cb06b3e55
## 从其他节点查看slot7373的信息
## redis-cli -p 7009 -c cluster nodes | grep master | sort -t \' \' -k2

## 从7009节点上面看,原本7009上面的importing flag 没有了,7373槽已经移动到 7009 上面去,迁移成功
## redis-cli -p 7004 -c cluster nodes | grep master | sort -t \' \' -k2

## 从7004 节点上面看,7373slot 已经迁移成功
## redis-cli -p 7003 -c cluster nodes | grep master | sort -t \' \' -k2

## 从7003上面看,7373slot已经迁移成功
## get gw
## set ge asds

## 数据已经可读可写
## 反复横跳现象已经消失,只要先在接收节点上面执行setslot ... node 就不会出现反复横跳现象
## step 8
## 观察日志 发现 只有接收slot 的节点 执行setslot ... node 命令 才会更新epoch 版本号,其他节点不会更新epoch,

## 节点之间通信的时候,会带着epoch版本号
## 加入 节点A接收了槽7373,更新了版本号到57,然后通信时A 给节点B发消息,说7373槽已经归我管了
## 现在有两种情况,一是节点B的epoch 比57 高,二是节点B的epoch版本号比57低
## 情况一:不理会节点A 的信息,这就导致数据不一致,节点B仍然认为槽7373 归源节点管
## 情况二: 更新信息,同步认为槽7373已经归节点A 管
3.cluster 操作命令
cluster info :打印集群的信息
cluster nodes :列出集群当前已知的所有节点( node),以及这些节点的相关信息。
节点
cluster meet <ip> <port> :将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
cluster forget <node_id> :从集群中移除 node_id 指定的节点。
cluster replicate <master_node_id> :将当前从节点设置为 node_id 指定的master节点的slave节点。只能针对slave节点操作。
cluster saveconfig :将节点的配置文件保存到硬盘里面。
槽(slot)
cluster addslots <slot> [slot ...] :将一个或多个槽( slot)指派( assign)给当前节点。
cluster delslots <slot> [slot ...] :移除一个或多个槽对当前节点的指派。
cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
cluster setslot <slot> node <node_id> :将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给
另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
cluster setslot <slot> migrating <node_id> :将本节点的槽 slot 迁移到 node_id 指定的节点中。
cluster setslot <slot> importing <node_id> :从 node_id 指定的节点中导入槽 slot 到本节点。
cluster setslot <slot> stable :取消对槽 slot 的导入( import)或者迁移( migrate)。
键
cluster keyslot <key> :计算键 key 应该被放置在哪个槽上。
cluster countkeysinslot <slot> :返回槽 slot 目前包含的键值对数量。
cluster getkeysinslot <slot> <count> :返回 count 个 slot 槽中的键
4. cluster setslot命令的作用
4.1 cluster setslot <slot> migrating <node_id>
测试1:
## step 1
## 测试:执行脚本对slot批量操作(把脚本中除了setslot migrating命令注释掉,只执行 cluster setslot <slot> migrating <node_id>):
## python /apps/dbdat/python3/test2/redis-expand.py 8871 127.0.0.1:7004 127.0.0.1:7009
## 把 7009 中 8000个slot 设置migrating flag 指向7004

## 尽管在7004 上面先执行asking 后 再set 也不行

## 因为7004 上面没有设置importing flag的原因,不允许新的键在7004上面执行
## 但是加上cluster setslot <slot> importing <node_id> 就没问题,详细在测试6中
## 所以只加上migrating flag 不加上importing flag 没办法设置新值
测试2:
## step 1
## set madasdsaasdsd lasmd
## set madasdscxzaasdsd lasmad

## step 2
## 测试:执行脚本对slot批量操作(把脚本中除了setslot migrating命令注释掉,只执行 cluster setslot <slot> migrating <node_id>):
## python /apps/dbdat/python3/test2/redis-expand.py 8871 127.0.0.1:7009 127.0.0.1:7004
## 把 7004 中 8000个slot 设置migrating flag
## step 3
## get madasdsaasdsd
## get madasdscxzaasdsd

## 结合实验一说明 处于migrating flag状态的slot 都不能存放新值 但可以获取和设置旧值
4.2 cluster setslot <slot> importing <node_id>
测试3:
## step 1
## 对接收节点直接执行 cluster setslot 7373 node 273289d0a17cd30fecc7a3db6fb2fd1cb06b3e55
## 执行直接迁移到源节点
## 观察日志发现没有生成新的epoch 版本号
## 所以其他节点也不会同步该变更信息
## 说明可能没有执行cluster setslot <slot> importing <node_id> 给迁移的槽设置importing flag的话不会生成新的epooch版本号
测试4:
## step 1
## 接收节点先执行: redis-cli -p 7009 -c cluster setslot 7373 importing cd8cd114215e4c2869d6d31ae7fe5f5cff922ed3 (给slot7373 设置importing flag)
## 接收节点执行: redis-cli -p 7009 -c cluster setslot 7373 node 273289d0a17cd30fecc7a3db6fb2fd1cb06b3e55

## 生成了新的epoch版本号,同时 变更也会被其他节点应用



## cluster setslot <slot> importing <node_id> 语句第一个作用是让cluster setslot... node 命令生成新的epoch版本号
测试5
## step 1
## 测试:执行脚本对slot批量操作(把脚本中除了setslot importing命令注释掉,只执行 cluster setslot <slot> importing <node_id>):
## python /apps/dbdat/python3/test2/redis-expand.py 8871 127.0.0.1:7009 127.0.0.1:7004
## 把 7004 中 8000个slot 设置importing flag
## 单独执行这个命令没有什么影响,读取和新设置的键都会继续使用原来的节点来存、
测试6
## step 1
## 测试:执行脚本对slot批量操作(把脚本中除了setslot importing 和 miragting 以外命令注释掉,只执行 cluster setslot <slot> importing <node_id> 和 cluster setslot <slot> migrating <node_id> ):
## python /apps/dbdat/python3/test2/redis-expand.py 8871 127.0.0.1:7004 127.0.0.1:7009 (移动的槽数量 target source)
## 7004 是目标节点, 7009 是源节点
## redlis-cli -p 7004 -c
## set asdk asmdzmc

## 可测试1 情况一样,仍然设置不了值,这个error 意思是请去7004 中执行操作?
## redis-cli -p 7004 -c
## asking
## set asdk qnwien

4.3 cluster setslot <slot> node <node_id>
## 那所有master节点或者所有节点都执行一次,不就可以了吗,理论上对所有节点所拥有的集群信息都修改一次,是否可以达成目标
测试7
## step 1
## 执行以下命令,对三个主节点执行cluster setslot ... node ...
## redis-cli -p 7009 -c cluster setslot 7373 node 273289d0a17cd30fecc7a3db6fb2fd1cb06b3e55
## redis-cli -p 7009 -c cluster setslot 7373 node 273289d0a17cd30fecc7a3db6fb2fd1cb06b3e55
## redis-cli -p 7009 -c cluster setslot 7373 node 273289d0a17cd30fecc7a3db6fb2fd1cb06b3e55
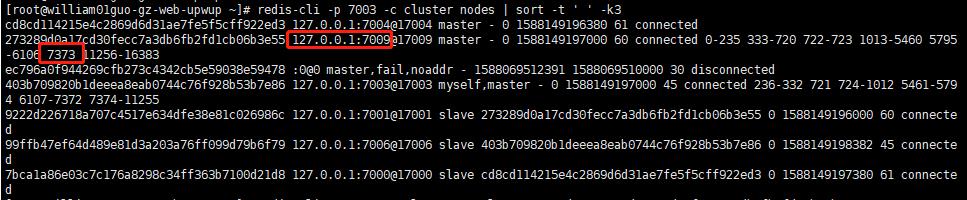
## 7001 上来没有了7373 这个slot ( 7001 为7009的从节点)
## get gw


## 也确实是迁移成功了
## 问题是 从节点是否有epoch信息?
## 现在kill 掉 7009, 让它的从节点做故障迁移

## 故障迁移成功后,集群状态就fail 了
## 在 7001 节点上面查看slot信息

## 在7004 上面查看slot信息,也没有了7373 的踪影

## 主要是由于 故障迁移后 新的slave 会产生最新的epoch版本号,然后按新slave 的集群信息来更新,所以直接执行cluster setslot ... node ...是不行的。
## 这种情况应该是slave的信息中没有7373slot的信息,所以导致这种情况
4.4 MIGRATE 命令测试
测试8:
## step 1
## 脚本 设置一个 200M的值】
limit = 273741824
n = 100000
s = generate_random_str(n)
while sys.getsizeof(s) < limit:
n += 100000
s += generate_random_str(n)
print(sys.getsizeof(s))
# print(\'success\')
r = RedisCluster(host=\'127.0.0.1\', port=7001)
r.set(\'lxl\', s)
## step 2
## 已经 lxl 这个键存在720 的槽上
## 720 在 7008 上,我把键移动到 7006 上
## redis-cli -p 7008 -c cluster nodes | sort -k3 | grep master

## step 3
## 源节节点执行 redis-cli -p 7006 -c cluster setslot 720 importing f96767c817d322943ba0f7b3124d5cccf79931a5
## 接收节点执行 redis-cli -p 7008 -c cluster setslot 720 migrating 99ffb47ef64d489e81d3a203a76ff099d79b6f79
## 执行完以上命令就可以在7006设置importing flag 和在7008上面设置migrating flag
## step 4
## 键gw 存在在 7008 上面

## 键hjw 存在 7006上面

## 开三个窗口
## 窗口1 执行:
## redis-cli -p 7008 -c MIGRATE 127.0.0.1 7006 lxl 0 100000000000 replace
## 窗口2 执行:
## redis-cli -p 7008 -c get gw

## 可以看出源节点从一开始一直阻塞
## 窗口3 执行:
## redis-cli -p 7006 -c get hjw

## 目标节点阻塞一段时间
## 因为键大小大概200M,可能只需要一次就能发送完,所以目标节点只在接收数据,和restore过程会阻塞,但是如果键值很大,需要发多次 (接收缓冲区满了->接收数据-> restore数据 -> 缓冲区满了或者源节点发完了-> 接收数据->restore数据,因为是redis 单线程的,所以会阻塞
4.5 Migrate 流程
- 执行的时候会阻塞进行迁移的两个实例,直到以下任意结果发生:迁移成功,迁移失败,等到超时
- 当前实例对给定 key 执行 DUMP 命令 ,将它序列化,然后传送到目标实例,目标实例再使用 RESTORE对数据进行反序列化,并将反序列化所得的数据添加到数据库中;当前实例就像目标实例的客户端那样,只要看到 RESTORE 命令返回 OK ,它就会调用 DEL 删除自己数据库上的 key
- timeout 参数以毫秒为格式,指定当前实例和目标实例进行沟通的最大间隔时间。这说明操作并不一定要在 timeout 毫秒内完成,只是说数据传送的时间不能超过这个 timeout 数
- 超时会返回IOERR,当返回IOERR时,会出现两种情况, 1.key存在两个实例中,2.key 只存在当前实例
- 如果有其他错误发生,那么 MIGRATE 保证 key 只会出现在当前实例中
以上是关于REDIS CLUSTER 搭建,扩容缩容基本原理的主要内容,如果未能解决你的问题,请参考以下文章