楔子
上节我们讨论了如何进行数据库的结构设计,并具体介绍了实体关系图和规范化的技术。
在设计 ERD 时,首先需要定义实体以及实体的属性,也就是定义表的结构。定义表结构时,首先需要确认表中包含哪些字段以及字段的数据类型。今天我们就来了解一下如何为表中的字段选择合适的数据类型。
常见数据类型
字段的数据类型定义了该字段能够存储的数据值,以及允许执行的操作。
字符串类型:
字符串类型用于存储字符和字符串数据,主要包含三种具体的类型:定长字符串、变长字符串以及字符串大对象。各种数据库对于字符串类型的支持如下:
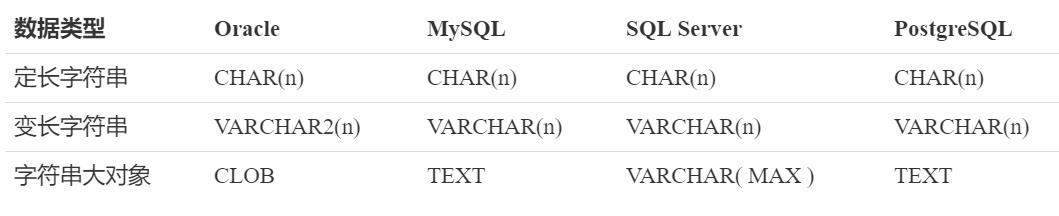
CHAR(n) 表示长度固定的字符串,其中 n 表示字符串的长度。常见的定义方式包括:
CHAR,长度为 1 的字符串,只能存储 1 个字符CHAR(5),长度为 5 的字符串
对于定长字符串,如果输入的字符串长度不够,将会使用空格进行填充。例如类型为 CHAR(5) 的字段,如果输入值为 "A",实际存储的内容为 "A####";# 代表空格,也就是一个字符 "A" 加上 4 个空格。
CHARACTER 和 CHAR 是同义词,可以通用。
通常来说,只有存储固定长度的数据时,才会考虑使用定长字符串类型。例如 18 位身份证,6 位邮政编码等。
VARCHAR(n) 表示长度不固定的字符串,其中 n 表示允许存储的最大长度。
对于变长字符串,如果输入的字符串长度不够,存储实际的内容。例如类型为 VARCHAR(5) 的字段,如果输入值为 "A",实际存储的内容为 "A"。
CHAR VARYING 和 CHARACTER VARYING 是 VARCHAR 的同义词,可以通用。 Oracle 中使用 VARCHAR2 表示变长字符串类型。
变长字符串类型一般用于存储长度不固定的内容,例如名字、电子邮箱、产品描述等。
CLOB 表示字符串大对象,通常用于存储普通字符串类型无法支持的更长的字符串数据。例如整篇文章、备注、评论等。
Oracle 使用 CLOB 类型存储大型字符串;MySQL 提供了 TINYTEXT、TEXT、MEDIUMTEXT 以及 LONGTEXT 分别用于存储不同长度的文本数据;SQL Server 使用 VARCHAR( MAX ) 存储大文本数据;PostgreSQL 提供了 TEXT 类型存储任意长度的字符串。
CHARACTER LARGE OBJECT 和 CHAR LARGE OBJECT 是 CLOB 的同义词,可以通用。
在 SQL 中,输入字符串类型的常量和数据时,需要使用单引号引用:
\'S001\'
\'张飞\'
\'13512345678\'
数字类型:
数字类型主要分为两类:精确数字和近似数字。
精确数字类型用于存储整数或者包含固定小数位的数字。
其中,SMALLINT、INTEGER 和 BIGINT 都可以表示整数。对于 mysql、SQL Server 以及 PostgreSQL,SMALLINT 支持 -32768 ~ 32767;INTEGER 支持 -2147483648 ~ 2147483647;BIGINT 支持 -263 ~ 263-1。Oracle 中的 SMALLINT 和 INTEGER 都是NUMBER(38,0) 的同义词;Oracle 不支持 BIGINT 关键字。
INT 是 INTEGER 的同义词,可以通用。 MySQL 中还提供了 TINYINT,支持 -128 ~ 127;MEDIUMINT 支持 -8388608 ~ 8388607。另外,MySQL 中的所有整型分为有符号类型(例如 INTEGER、INTEGER SIGNED)和无符号类型(例如 INTEGER UNSIGNED),无符号整型支持的正整数范围扩大了一倍。
NUMERIC(p, s) 和 DECIMAL(p, s) 可以看作相同的类型,用于存储包含小数的精确数字。
其中,精度 p 表示总的有效位数,刻度 s 表示小数点后允许的位数。例如,123.04 的精度为 5,刻度为 2。p 和 s 是可选的,s 为 0 表示整数。SQL 标准要求 p ≥ s ≥ 0 并且 p > 0。
DEC 是 DECIMAL 的同义词,可以通用。 Oracle中的 NUMERIC 和 DECIMAL 都是 NUMBER 的同义词。
整数类型通常用于存储数字 id、产品数量、课程得分等数字;NUMERIC 用于存储产品价格、销售金额等包含小数并且准确度要求高的数据。
近似数字也称为浮点型数字,一般使用较少,主要用于科学计算领域。
REAL 表示单精度浮点数,通常精确到小数点后 6 位;DOUBLE PRECISION 表示双精度浮点数,通常精确到小数点后 15 位。浮点数运算更快,但是可能丢失精度;浮点数的比较运算可能会导致非预期的结果。
Oracle 使用 BINARY_FLOAT 和 BINARY_DOUBLE 表示浮点数。 MySQL 使用 FLOAT 表示单精度浮点数,同时区分有符号和无符号的浮点数。
日期时间类型:
DATE 存储年、月、日;TIME 存储时、分、秒,以及秒的小数部分;TIMESTAMP 同时包含年、月、日、时、分、秒,以及秒的小数部分。
Oracle 中的 DATE 类型包含了额外的时、分、秒,不支持 TIME 类型。 SQL Server 使用 DATETIME2 和 DATETIMEOFFSET 表示时间戳。 MySQL 还支持 DATETIME 表示时间戳。
如果存储日期信息,例如生日,可以使用 DATE 类型;如果需要更高的时间精度,例如订单时间、发车时间等,可以使用 TIMESTAMP 类型;TIME 类型使用较少。
在 SQL 中,输入日期时间类型的常量和数据时,常见的方法如下:
\'2019-12-25\'
DATE \'2019-12-25\'
\'13:30:15\'
TIME \'13:30:15\'
\'2019-12-25 13:30:15\'
TIMESTAMP \'2019-12-25 13:30:15\'
二进制类型:
二进制类型用于存储二进制数据,例如文档、图片,视频等。二进制类型具体包含以下三种:
- BINARY(n),固定长度的二进制数据,n 表示二进制字符数量;
- VARBINARY(n),可变长度的二进制数据,n 表示支持的最大二进制字符数量;
- BLOB,二进制大对象;
Oracle 支持 BLOB 二进制类型;MySQL 支持 BINARY、VARBINARY 以及 TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOB 二进制类型;SQL Server 支持 BINARY、VARBINARY 以及 VARBINARY ( MAX ) 二进制类型;PostgreSQL 支持 BYTEA 二进制类型。
选择合适的数据类型:
最后我们来看看如何选择合适的数据类型。首先,应该满足存储业务数据的需求;其次,还需要考虑性能和使用方便。一般来说,先确定基本的类型:
- 文本数据,只能使用字符串类型;
- 数值数据,尤其是需要进行数学运算的数据,选择数字类型;
- 日期和时间信息,最好使用原生的日期时间类型;
- 文档、图片、音频和视频等,使用二进制类型;或者可以考虑存储在文件服务器上,然后在数据库中存储文件的路径;
接下来需要进一步确定具体的数据类型。在满足数据存储和扩展的前提下,尽量使用更小的数据类型,可以节省一些存储,通常性能也会更好。例如,对于一个小型公司而言,员工编号通常不会超过几百,使用 SMALLINT 已经足够。对于 MySQL 而言,不需要支持负数的话可以考虑 UNSIGNED 类型。
如果需要存储精确的数字,不要使用浮点数类型。对于金额,可以使用 NUMERIC(p, s);或者将数据乘以 10 的 N 次方,例如将 10.35 元存储为整数 103500,然后在应用程序中进行处理和前端显示转换。
对于字符数据,一般使用 VARCHAR 类型;如果数据长度能够确保一致,可以使用 CHAR;指定最大长度时,满足存储需求的前提下尽量使用更小的值。只有在普通字符串类型长度无法满足时才考虑大字段类型。
不要使用字符串存储日期时间数据,它们无法支持数据的运算。例如获得两个日期之间的间隔,需要依赖应用程序进行转换和处理。最好也不要使用整数类型存储当前时间距离 1970 年 1 月 1 日的毫秒数来表示时间,这种方式在显示时需要进行转换,不是很方便。
另外,如果一个字段同时出现在多个表中,使用相同的数据类型。例如,员工表中的部门编号(dept_id)字段与部门表的编号(dept_id)字段保持类型一致。
使用 DDL 管理数据库中的对象
上节我们讨论了如何为字段选择合适的数据类型。选定了字段的数据类型之后,我们就可以开始创建和管理数据库中的表了。
数据库对象:
数据库(Database)由一组相关的对象组成,主要包括表、索引、视图、存储过程等。为了方便对象的管理和访问,数据库通常使用模式(Schema)来组织这些对象;模式是一个逻辑单元,或者一个存储对象的容器;它们之间的关系如下图所示:
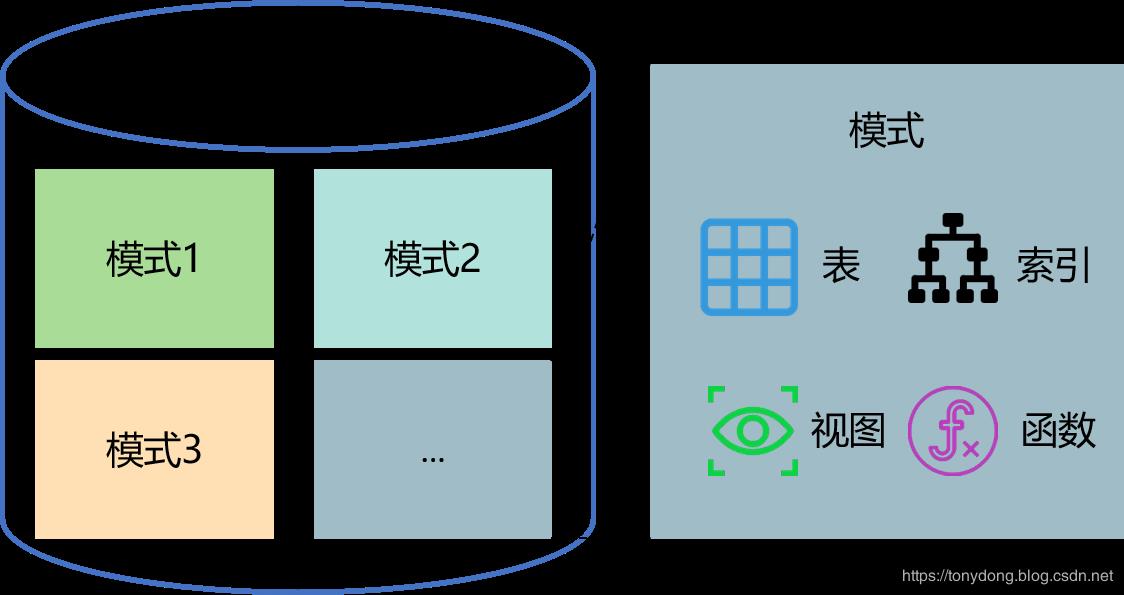
一个数据库由多个模式组成,一个模式由许多对象组成;在不同模式中可以创建同名的对象。
MySQL 中的模式和数据库是相同的概念,一个数据库对应一个同名的模式。
管理数据库:
当我们连接到数据库服务器时,需要指定一个目标数据库。如果需要创建一个新的数据库,可以使用 CREATE DATABASE 语句:
CREATE DATABASE mydb;
以上语句将会创建一个名为 mydb 的数据库。对于 Oracle 而言,通常只有一个数据库;因此很少手动创建数据库。
我们可以使用命令或语句查看已有的数据库
-- MySQL 实现
SHOW DATABASES;
SELECT schema_name AS database_name
FROM information_schema.schemata;
-- information_schema 系统数据库存储了 MySQL 服务器中所有数据库的信息,例如数据库名称、表的结构以及访问权限等。
-- SQL Server 实现
SELECT name AS database_name
FROM sys.databases;
-- sys.databases 是 SQL Server 中的一个系统表,存储了关于数据库的信息。
-- PostgreSQL 实现
SELECT datname AS database_name
FROM pg_database;
-- pg_database 是 PostgreSQL 中的一个系统表,存储了关于数据库的信息。
-- Oracle 实现
SELECT name AS database_name
FROM v$database;
-- v$database 是 Oracle 中的一个系统视图,提供了关于数据库的信息。
如果确认不再需要,可以使用 DROP DATABASE 语句删除数据库:
DROP DATABASE mydb;
DROP DATABASE 命令将会删除该数据库中的所有对象,而且操作无法恢复,使用时千万小心!
如果有用户正在连接,无法删除数据库;可以等待用户断开连接,或者强制断开连接后删除。
管理模式:
CREATE SCHEMA 命令用于创建一个新的模式:
-- SQL Server 以及 PostgreSQL 实现
create schema xxx [AUTHORIZATION some_user]
以上语句创建一个名为 xxx 的模式,可选的 AUTHORIZATION 表示为该模式指定一个拥有者 some_user,拥有者是一个已经存在的数据库用户。
SQL Server 创建数据库时会自动创建一个名为 dbo 的模式,PostgreSQL 创建数据库时会自动创建一个名为 public 的模式。
MySQL 中的模式等价于数据库,因此 CREATE SCHEMA 等价于 CREATE DATABASE。
Oracle 中的模式等价于用户,因此使用 CREATE USER 命令创建用户时就相当于创建一个同名的模式:
CREATE USER some_user
IDENTIFIED BY xxx;
Oracle 也提供了 CREATE SCHEMA 命令,但不是用于创建模式,而是用于在模式中创建表、视图以及执行授权操作。
不需要的模式可以使用 DROP SCHEMA 命令删除:
-- SQL Server 以及 PostgreSQL 实现
DROP SCHEMA xxx;
MySQL 中的模式等价于数据库,因此 DROP SCHEMA 等价于 DROP DATABASE。
Oracle 中的模式等价于用户,因此使用 DROP USER 命令创建用户时就相当于创建一个同名的模式:
-- Oracle 实现
DROP USER hr;
如果模式中存在对象,则无法删除该模式;可以先删除其中的对象,再删除模式。某些数据库支持级联删除:
-- PostgreSQL 实现
DROP SCHEMA xxx CASCADE;
-- Oracle 实现
DROP USER some_user CASCADE;
复制表:
像创建表、添加记录、修改记录等等比较简单,我们这里就不提了,可以去菜鸟教程上面搜索,非常简单。
除了手动创建表之外,也可以基于其他表或者查询的结果创建一个表:
CREATE TABLE table_name
AS
SELECT ...;
修改表:
对于已经存在的表,可能会由于业务变更或者代码重构需要修改它的结构。因此,SQL 定义了修改表的语句:
其中的 action 表示执行的操作,常见的操作包括增加列,修改列,删除列;增加约束,修改约束,删除约束等。以下语句用于增加一个新的字段:
ALTER TABLE table_name
ADD 列名 类型 [约束];
-- 添加字段的内容和创建表时类似,包括字段名、数据类型以及可选的列约束
如果某个字段不再需要,可以使用 DROP COLUMN 操作删除:
ALTER TABLE table_name drop 列名
删除表:
-- DROP TABLE 语句用于删除一个表。
DROP TABLE table_name
截断表:
SQL 还提供了一种特殊的操作:截断表(TRUNCATE),可以用于快速删除表中的所有数据。
TRUNCATE TABLE table_name
TRUNCATE 用于快速删除数据,回收表占用的空间,但会保留表的结构。MySQL 和 PostgreSQL 可以省略 TABLE 关键字。
小结
今天我们介绍了 SQL 中的基本数据类型以及它们在各种数据库中的实现,同时分析了选择数据类型时的一些通用的原则。需要注意的是,同一数据类型在不同数据库中支持的范围大小和精确度可能不同;因此,使用任何数据类型之前都应该查看相关的数据库文档。
数据定义语言(Data Definition Language)用于定义数据库中各种对象的结构,例如表、视图、索引等。常见的 DDL 语句包括创建(CREATE)、修改(ALTER)和删除(DROP)。虽然各种对象的具体语法细节不同,但都遵循相同的模式;例如,创建索引可以使用 CREATE INDEX 语句;