基于ELK搭建MySQL日志平台的要点和常见错误
Posted 东山絮柳仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于ELK搭建MySQL日志平台的要点和常见错误相关的知识,希望对你有一定的参考价值。
第一部分 概括
数据,让一切有迹可循,让一切有源可溯。ELK是集分布式数据存储、可视化查询和日志解析于一体的日志分析平台。ELK=elasticsearch+Logstash+kibana,三者各司其职,相互配合,共同完成日志的数据处理工作。ELK各组件的主要功能如下:
- elasticsearch,数据存储以及全文检索;
- logstash,日志加工、“搬运工”;
- kibana:数据可视化展示和运维管理。
我们在搭建平台时,还借助了filebeat插件。Filebeat是本地文件的日志数据采集器,可监控日志目录或特定日志文件(tail file),并可将数据转发给Elasticsearch或Logstatsh等。
本案例的实践,主要通过ELK收集、管理、检索mysql实例的慢查询日志和错误日志。
简单的数据流程图如下:

第二部分 elasticsearch
2.1 ES特点和优势
- 分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
- 实时分析的分布式搜索引擎。分布式:索引分拆成多个分片,每个分片可有零个或多个副本;负载再平衡和路由在大多数情况下自动完成。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上。
- 支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
2.2 ES主要概念
| ES数据库 | MySQL数据库 |
| Index | Database |
| Tpye[在7.0之后type为固定值_doc] | Table |
| Document | Row |
| Field | Column |
| Mapping | Schema |
| Everything is indexed | Index |
| Query DSL[Descriptor structure language] | SQL |
| GET http://... | Select * from table … |
| PUT http://... | Update table set … |
- 关系型数据库中的数据库(DataBase),等价于ES中的索引(Index);
- 一个关系型数据库有N张表(Table),等价于1个索引Index下面有N多类型(Type);
- 一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成;
- 在关系型数据库里,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等;
- 关系型数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET.
2.3 执行权限问题
报错提示
[usernimei@testes01 bin]$ Exception in thread "main" org.elasticsearch.bootstrap.BootstrapException: java.nio.file.AccessDeniedException: /data/elasticsearch/elasticsearch-7.4.2/config/elasticsearch.keystore Likely root cause: java.nio.file.AccessDeniedException: /data/elasticsearch/elasticsearch-7.4.2/config/elasticsearch.keystore at java.base/sun.nio.fs.UnixException.translateToIOException(UnixException.java:90) at java.base/sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:111) at java.base/sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:116) at java.base/sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:219) at java.base/java.nio.file.Files.newByteChannel(Files.java:374) at java.base/java.nio.file.Files.newByteChannel(Files.java:425) at org.apache.lucene.store.SimpleFSDirectory.openInput(SimpleFSDirectory.java:77) at org.elasticsearch.common.settings.KeyStoreWrapper.load(KeyStoreWrapper.java:219) at org.elasticsearch.bootstrap.Bootstrap.loadSecureSettings(Bootstrap.java:234) at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:305) at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:159) at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:150) at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86) at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:125) at org.elasticsearch.cli.Command.main(Command.java:90) at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:115) at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:92) Refer to the log for complete error details
问题分析
第一次误用了root账号启动,此时路径下的elasticsearch.keystore 权限属于了root
-rw-rw---- 1 root root 199 Mar 24 17:36 elasticsearch.keystore
解决方案--切换到root用户修改文件elasticsearch.keystore权限
调整到es用户下,即
chown -R es用户:es用户组 elasticsearch.keystore
问题2.4 maximum shards open 问题
根据官方解释,从Elasticsearch v7.0.0 开始,集群中的每个节点默认限制 1000 个shard,如果你的es集群有3个数据节点,那么最多 3000 shards。这里我们是只有一台es。所以只有1000。
[2019-05-11T11:05:24,650][WARN ][logstash.outputs.elasticsearch][main] Marking url as dead. Last error: [LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError] Elasticsearch Unreachable: [http://qqelastic:xxxxxx@155.155.155.155:55944/][Manticore::SocketTimeout] Read timed out {:url=>http://qqelastic:xxxxxx@155.155.155.155:55944/, :error_message=>"Elasticsearch Unreachable: [http://qqelastic:xxxxxx@155.155.155.155:55944/][Manticore::SocketTimeout] Read timed out", :error_class=>"LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError"} [2019-05-11T11:05:24,754][ERROR][logstash.outputs.elasticsearch][main] Attempted to send a bulk request to elasticsearch\' but Elasticsearch appears to be unreachable or down! {:error_message=>"Elasticsearch Unreachable: [http://qqelastic:xxxxxx@155.155.155.155:55944/][Manticore::SocketTimeout] Read timed out", :class=>"LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError", :will_retry_in_seconds=>2} [2019-05-11T11:05:25,158][WARN ][logstash.outputs.elasticsearch][main] Restored connection to ES instance {:url=>"http://qqelastic:xxxxxx@155.155.155.155:55944/"} [2019-05-11T11:05:26,763][WARN ][logstash.outputs.elasticsearch][main] Could not index event to Elasticsearch. {:status=>400, :action=>["index", {:_id=>nil, :_index=>"mysql-error-testqq-2019.05.11", :routing=>nil, :_type=>"_doc"}, #<LogStash::Event:0x65416fce>], :response=>{"index"=>{"_index"=>"mysql-error-qqweixin-2020.05.11", "_type"=>"_doc", "_id"=>nil, "status"=>400, "error"=>{"type"=>"validation_exception", "reason"=>"Validation Failed: 1: this action would add [2] total shards, but this cluster currently has [1000]/[1000] maximum shards open;"}}}}
可以用Kibana来设置
主要命令:
PUT /_cluster/settings { "transient": { "cluster": { "max_shards_per_node":10000 } } }
操作截图如下:
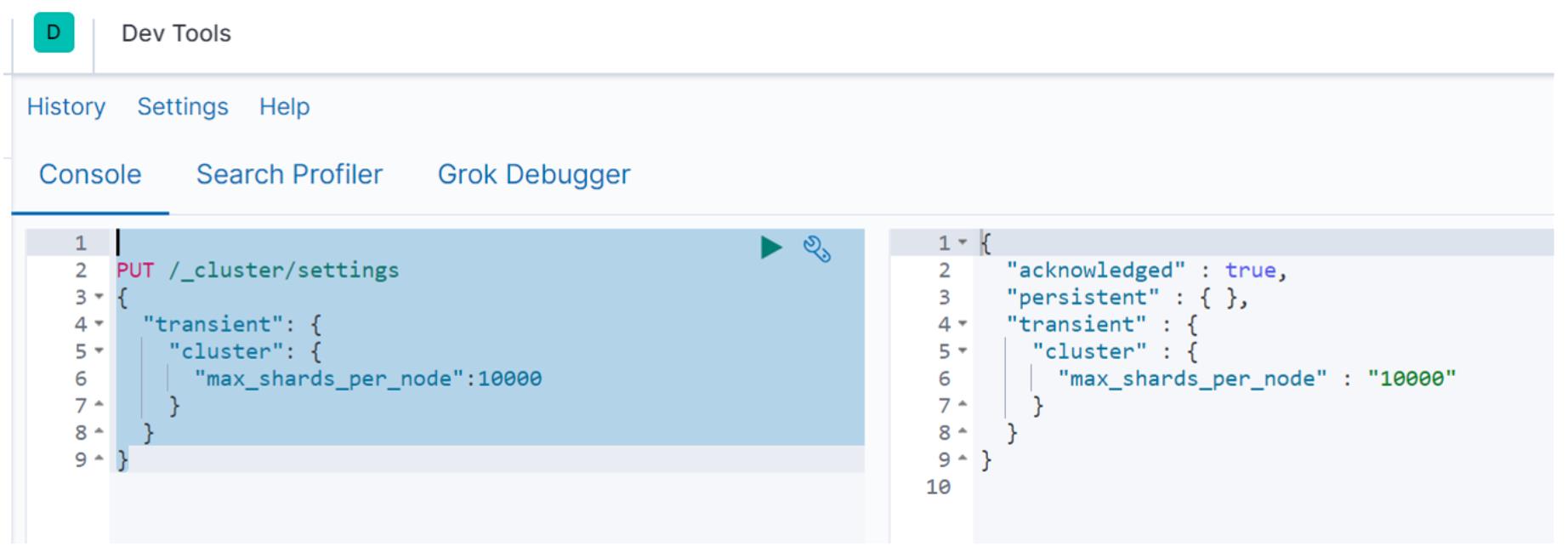
注意事项:
建议设置后重启下lostash服务
问题 2.5 Too Many Requests/circuit_breaking_exception
随着ES存储数据的增多,在打开kibana执行查询时报错,提示信息如下:
{
"statusCode":429,
"error":"Too Many Requests",
"message":"[circuit_breaking_exception] [parent] Data too large, data for [<http_request>] would be [987817048/942mb], which is larger than the limit of [986061209/940.3mb], real usage: [987817048/942mb], new bytes reserved: [0/0b], usages [request=0/0b, fielddata=966440/943.7kb, in_flight_requests=0/0b, accounting=47842100/45.6mb], with { bytes_wanted=987817048 & bytes_limit=986061209 & durability="PERMANENT" }"
}
寻找解决方案为在实例的config/jvm.options设置如下:
-Xms2g
-Xmx2g
#-XX:+UseConcMarkSweepGC
-XX:+UseG1GC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
注释:-Xmx2g 修改前为 -Xms1g;-XX:+UseG1GC 为新增参数选项。
但是此时启动报错:
Exception in thread "main" java.lang.RuntimeException: starting java failed with [1]
output:
Error occurred during initialization of VM
Multiple garbage collectors selected
error:
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
at org.elasticsearch.tools.launchers.JvmErgonomics.flagsFinal(JvmErgonomics.java:111)
at org.elasticsearch.tools.launchers.JvmErgonomics.finalJvmOptions(JvmErgonomics.java:79)
at org.elasticsearch.tools.launchers.JvmErgonomics.choose(JvmErgonomics.java:57)
at org.elasticsearch.tools.launchers.JvmOptionsParser.main(JvmOptionsParser.java:89)
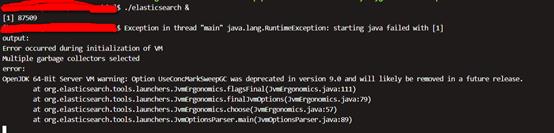
解决方案:
去除新增的-XX:+UseG1GC设置。
最终的设置为:
################################################################
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms2g
-Xmx2g
################################################################
## Expert settings
################################################################
##
## All settings below this section are considered
## expert settings. Don\'t tamper with them unless
## you understand what you are doing
##
################################################################
## GC configuration
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
## G1GC Configuration
第三部分 Filebeat
问题3.1 不读取log文件中的数据
2019-03-23T19:24:41.772+0800 INFO [monitoring] log/log.go:145 Non-zero metrics in the last 30s
{"monitoring": {"metrics": {"beat":{"cpu":{"system":{"ticks":30,"time":{"ms":2}},"total":{"ticks":80,"time":{"ms":4},"value":80},"user":{"ticks":50,"time":{"ms":2}}},"handles":{"limit":{"hard":1000000,"soft":1000000},"open":6},"info":{"ephemeral_id":"a4c61321-ad02-2c64-9624-49fe4356a4e9","uptime":{"ms":210031}},"memstats":{"gc_next":7265376,"memory_alloc":4652416,"memory_total":12084992},"runtime":{"goroutines":16}},"filebeat":{"harvester":{"open_files":0,"running":0}},"libbeat":{"config":{"module":{"running":0}},"pipeline":{"clients":0,"events":{"active":0}}},"registrar":{"states":{"current":0}},"system":{"load":{"1":0,"15":0.05,"5":0.01,"norm":{"1":0,"15":0.0125,"5":0.0025}}}}}}
修改 filebeat.yml 的配置参数
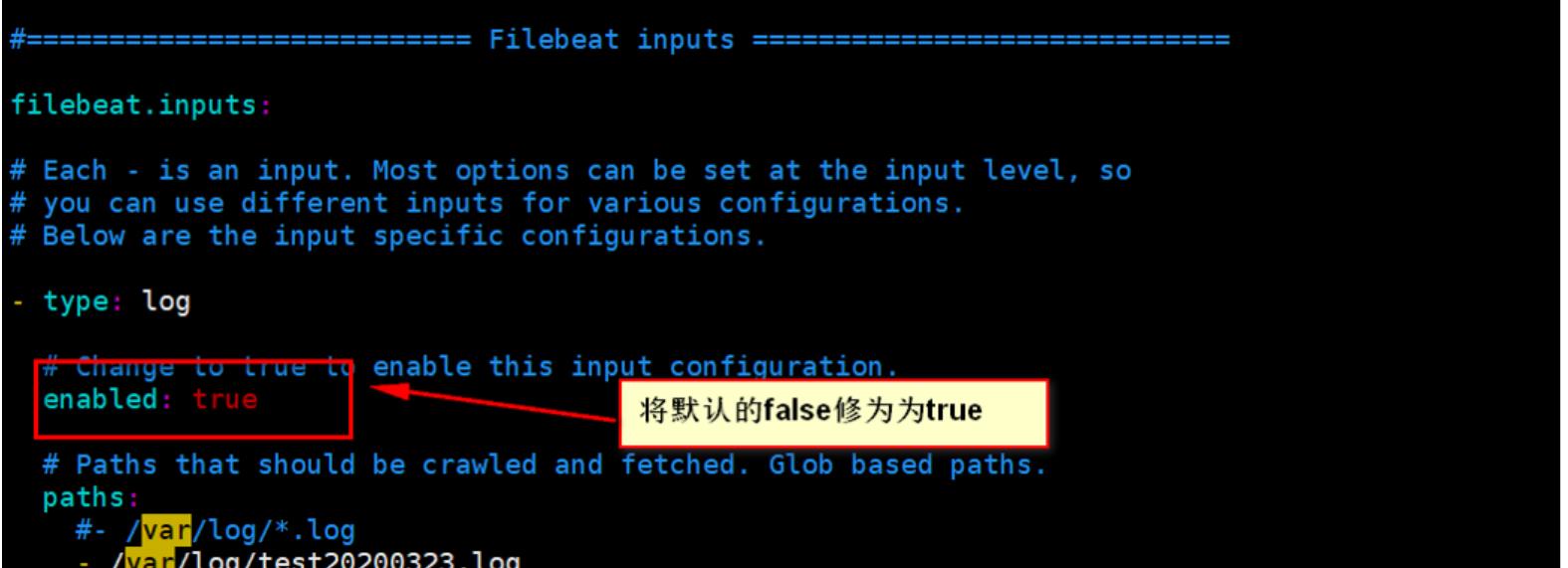
问题3.2 多个服务进程
2019-03-27T20:13:22.985+0800 ERROR logstash/async.go:256 Failed to publish events caused by: write tcp [::1]:48338->[::1]:5044: write: connection reset by peer 2019-03-27T20:13:23.985+0800 INFO [monitoring] log/log.go:145 Non-zero metrics in the last 30s {"monitoring": {"metrics": {"beat":{"cpu":{"system":{"ticks":130,"time":{"ms":11}},"total":{"ticks":280,"time":{"ms":20},"value":280},"user":{"ticks":150,"time":{"ms":9}}},"handles":{"limit":{"hard":65536,"soft":65536},"open":7},"info":{"ephemeral_id":"a02ed909-a7a0-49ee-aff9-5fdab26ecf70","uptime":{"ms":150065}},"memstats":{"gc_next":10532480,"memory_alloc":7439504,"memory_total":19313416,"rss":806912},"runtime":{"goroutines":27}},"filebeat":{"events":{"active":1,"added":1},"harvester":{"open_files":1,"running":1}},"libbeat":{"config":{"module":{"running":0}},"output":{"events":{"batches":1,"failed":1,"total":1},"write":{"errors":1}},"pipeline":{"clients":1,"events":{"active":1,"published":1,"total":1}}},"registrar":{"states":{"current":1}},"system":{"load":{"1":0.05,"15":0.11,"5":0.06,"norm":{"1":0.0063,"15":0.0138,"5":0.0075}}}}}} 2019-03-27T20:13:24.575+0800 ERROR pipeline/output.go:121 Failed to publish events: write tcp [::1]:48338->[::1]:5044: write: connection reset by peer
原因是同时有多个logstash进程在运行,关闭重启
问题3.3 将Filebeat 配置成服务进行管理
filebeat 服务所在路径:
/etc/systemd/system
编辑filebeat.service文件
[Unit] Description=filebeat.service [Service] User=root ExecStart=/data/filebeat/filebeat-7.4.2-linux-x86_64/filebeat -e -c /data/filebeat/filebeat-7.4.2-linux-x86_64/filebeat.yml [Install] WantedBy=multi-user.target
管理服务的相关命令
systemctl start filebeat #启动filebeat服务
systemctl enable filebeat #设置开机自启动
systemctl disable filebeat #停止开机自启动
systemctl status filebeat #查看服务当前状态
systemctl restart filebeat #重新启动服务
systemctl list-units --type=service #查看所有已启动的服务
问题3.4 Filebeat 服务启动报错
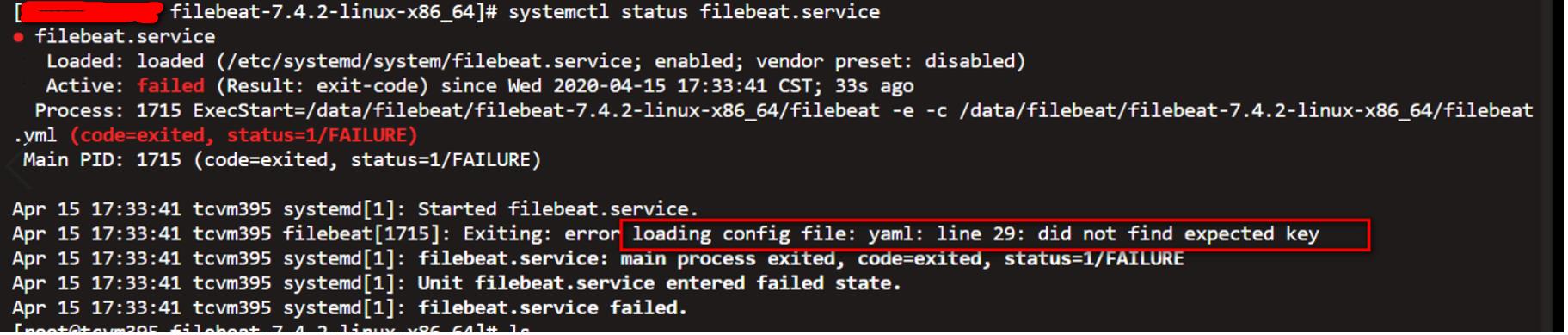
注意错误
Exiting: error loading config file: yaml: line 29: did not find expected key
主要问题是:filebeat.yml 文件中的格式有破坏,应特别注意修改和新增的地方,对照前后文,验证格式是否有变化。
问题 3.5 Linux 版本过低,无法以systemctl管理filebeat服务
此时我们可以以service来管理,在目录init.d下创建一个filebeat.service文件。主要脚本如下:
#!/bin/bash agent="/data/filebeat/filebeat-7.4.2-linux-x86_64/filebeat" args="-e -c /data/filebeat/filebeat-7.4.2-linux-x86_64/filebeat.yml" start() { pid=`ps -ef |grep /data/filebeat/filebeat-7.4.2-linux-x86_64/filebeat |grep -v grep |awk \'{print $2}\'` if [ ! "$pid" ];then echo "Starting filebeat: " nohup $agent $args >/dev/null 2>&1 & if [ $? == \'0\' ];then echo "start filebeat ok" else echo "start filebeat failed" fi else echo "filebeat is still running!" exit fi } stop() { echo -n $"Stopping filebeat: " pid=`ps -ef |grep /data/filebeat/filebeat-7.4.2-linux-x86_64/filebeat |grep -v grep |awk \'{print $2}\'` if [ ! "$pid" ];then echo "filebeat is not running" else kill $pid echo "stop filebeat ok" fi } restart() { stop start } status(){ pid=`ps -ef |grep /data/filebeat/filebeat-7.4.2-linux-x86_64/filebeat |grep -v grep |awk \'{print $2}\'` if [ ! "$pid" ];then echo "filebeat is not running" else echo "filebeat is running" fi } case "$1" in start) start ;; stop) stop ;; restart) restart ;; status) status ;; *) echo $"Usage: $0 {start|stop|restart|status}" exit 1 esac
注意事项
1.文件授予执行权限
chmod 755 filebeat.service
2.设置开机自启动
chkconfig --add filebeat.service
上面的服务添加自启动时,会报错

解决方案 在 service file的开头添加以下 两行

即修改完善后的代码如下:
#!/bin/bash # chkconfig: 2345 10 80 # description: filebeat is a tool for colletct log data agent="/data/filebeat/filebeat-7.4.2-linux-x86_64/filebeat" args="-e -c /data/filebeat/filebeat-7.4.2-linux-x86_64/filebeat.yml" start() { pid=`ps -ef |grep /data/filebeat/filebeat-7.4.2-linux-x86_64/filebeat |grep -v grep |awk \'{print $2}\'` if [ ! "$pid" ];then echo "Starting filebeat: " nohup $agent $args >/dev/null?2>&1 & if [ $? == \'0\' ];then echo "start filebeat ok" else echo "start filebeat failed" fi else echo "filebeat is still running!" exit fi } stop() { echo -n $"Stopping filebeat: " pid=`ps -ef |grep /data/filebeat/filebeat-7.4.2-linux-x86_64/filebeat |grep -v grep |awk \'{print $2}\'` if [ ! "$pid" ];then echo "filebeat is not running" else kill $pid echo "stop filebeat ok" fi } restart() { stop start } status(){ pid=`ps -ef |grep /data/filebeat/filebeat-7.4.2-linux-x86_64/filebeat |grep -v grep |awk \'{print $2}\'` if [ ! "$pid" ];then echo "filebeat is not running" else echo "filebeat is running" fi } case "$1" in start) start ;; stop) stop ;; restart) restart ;; status) status ;; *) echo $"Usage: $0 {start|stop|restart|status}" exit 1 esac
第四部分 Logstash
问题 4.1 服务化配置
logstash最常见的运行方式即命令行运行./bin/logstash -f logstash.conf启动,结束命令是ctrl+c。这种方式的优点在于运行方便,缺点是不便于管理,同时如果遇到服务器重启,则维护成本会更高一些,如果在生产环境运行logstash推荐使用服务的方式。以服务的方式启动logstash,同时借助systemctl的特性实现开机自启动。
(1)安装目录下的config中的startup.options需要修改
修改主要项:
1.服务默认启动用户和用户组为logstash;可以修改为root;
2. LS_HOME 参数设置为 logstash的安装目录;例如:/data/logstash/logstash-7.6.0
3. LS_SETTINGS_DIR参数配置为含有logstash.yml的目录;例如:/data/logstash/logstash-7.6.0/config
4. LS_OPTS 参数项,添加 logstash.conf 指定项(-f参数);例如:LS_OPTS="--path.settings ${LS_SETTINGS_DIR} -f /data/logstash/logstash-7.6.0/config/logstash.conf"
(2)以root身份执行logstash命令创建服务
创建服务的命令
安装目录/bin/system-install
执行创建命令后,在/etc/systemd/system/目录中生成了logstash.service 文件
(3)logstash 服务的管理
设置服务自启动:systemctl enable logstash
启动服务:systemctl start logstash
停止服务:systemctl stop logstash
重启服务:systemctl restart logstash
查看服务状态:systemctl status logstash
问题 4.2 安装logstash服务需先安装jdk
报错提示如下:

通过查看jave版本,验证是否已安装

上图说明没有安装。则将安装包下载(或上传)至本地,执行安装
执行安装命令如下:
yum localinstall jdk-8u211-linux-x64.rpm
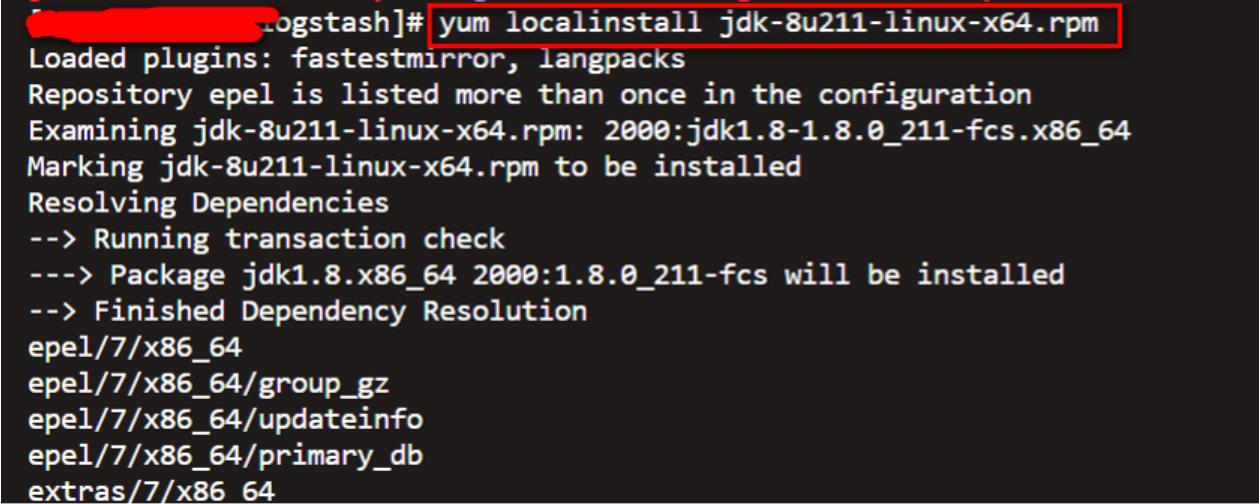
安装OK,执行验证

问题 4.3 Linux 版本过低,安装 logstash 服务失效
问题提示

查看Linux系统版本
