redis的自问自答
Posted poorloser
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis的自问自答相关的知识,希望对你有一定的参考价值。
redis号称单机QPS可达10万。为什单线程的redis竟然能达到这么高的qps?
网上有很多大佬已经给我们总结好了:
1、完全是内存操作
2、单线程处理
3、高效的数据结构,redis有自己的一套数据结构
4、使用多路复用i/o模型,非阻塞
5、其他方面的优化
我想多问几个问题:
第一点,redis完全是内存操作,我不否认内存操作很快,但是这一点能成为redis比memcache快的原因吗?显然不能,因为memcache也是内存操作。
第二点,redis单线程处理(主要指的是redis的核心部件文件事件处理器是单线程设计的)。这个地方有点意思了,memcache是多线程的,二者可以对比一下。而且在多核cpu的机器中,大部分情况下,多线程对cpu的利用率肯定是玩爆单线程的。那为什么多线程的memcache在大部分情况下qps没有单线程redis的数据好看呢?这个时候我觉得应该看看在缓存处理这种应用场景下,多线程和单线程分别的优缺点:
多线程的优点是可以利用多核cpu,提高效率,缺点是:需要考虑线程安全,加锁的复杂度和效率会有下降。单线程的优缺点恰恰与之相反。
现在根本的矛盾就是:
多线程模式下:多核cpu利用后提升的效率 VS 线程安全降低的效率。
单线程模式下:无法利用多核cpu损失的效率 VS 线程安全提升的效率。
相同的任务,执行的事件越短,说明你的效率越高。
简单的说:我们要把缓存中的字符串abcdefj修改为abcdef,完成这个操作的时间越短,说明效率越高。
模拟一下多线程处理方式:
- 第一步:线程去队列中获取任务,需要加锁,拿完后释放锁。
- 第二部:线程拿到任务后执行任务去修改字符串,需要加锁,修改完释放锁。
为了保证线程安全,多线程下获取任务和执行任务其实也相当于是单线程执行的,而且还有加锁和释放锁的过程。有人可能会说:我不用悲观锁,我用乐观锁。竞争激烈的时候乐观锁会导致cpu资源浪费,针对这种情况,java提供了锁升级,这些都是题外话。
综上所述,如果添加和修改比较多的话,单线程似乎更快,如果读(不用加锁,Java可以利用volatile,redis是c编写的,具体就不清楚了??)比较多的话,多线程更快,redis4.0以后确实也针对读优化了,读的时候使用的是多线程。 - 第三部分:高效的数据结构,redis优化设计了一套数据结构,可以提高存取效率。问题是这些数据结构是如何提高效率的?
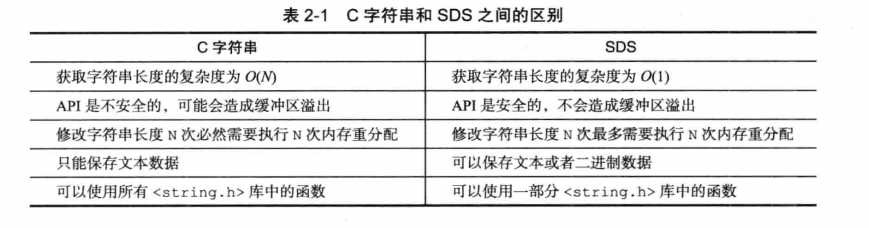
- 简单动态字符串,string的存储,redis没有使用c的默认字符串,而是使用的自己构建的名叫简单动态字符串(simple dynamic string,简称SDS)。
- 链表,c中没有这种数据结构,redis自己构建的
- 字典,c中没有这种数据结构,redis自己构建的
- 跳跃表,c中没有这种数据结构,redis自己构建的。大部分情况下,跳跃表的效率可以媲美平衡树,因为跳跃表的实现相对简单,所以不少程序使用跳跃表来代替平衡树(关于跳跃表和平衡树,应该单独拉出来一个问题)。
相比之下,链表和字典被广泛应用在redis的内部,跳跃表只用在了两个地方:有序集合键的实现、集群节点中用作内部数据结构 - 整数集合,当一个集合只包含整数元素,且集合的元素不多时,redis会使用整数集合来作为集合键的底层实现。其最大特点就是可以降低内存,在追求内存使用极致的时候,可以适当将存储的数据往这方面靠拢。
- 压缩列表,压缩列表同样也是为了节约内存而开发的。
redis并没有直接使用上面这些数据结构来实现键值对数据库,而是基于这些数据结构构建了一个对象系统,这个系统包含了字符串对象、列表对象、哈希对象、集合对象和有序集合对象这5中数据对象。每个数据对象都用到至少上面一种数据结构。
redis会根据不同的场景,为对象设置不同的数据结构实现,从而提高读写效率和内存的使用率。
写到这里,或许我们会明白,为什么redis这么块,难道仅仅因为单线程模型的无锁吗?高效的数据结构基础,才能让redis单线程下还能如此高效。试想,如果redis一个操作执行时间很长,这个时候又是单线程模型,那redis的qps如何能达到10w+?
可能又有问题说:难道redis在任何情况下执行效率都这么高吗?这个问题我在网上搜索了一下,网上有人说redis操作大于100k内容的数据时,效率不如memcache,可以考虑使用memcache。这也说明了当 数据变大时,redis的数据处理不那么高效时,单线程的弊端就表现出来了。
- 简单动态字符串,string的存储,redis没有使用c的默认字符串,而是使用的自己构建的名叫简单动态字符串(simple dynamic string,简称SDS)。
redis的线程模型
redis使用的是事件驱动模型,每来一个连接回话,服务端都当成一个事件处理。这里简单介绍一下事件驱动,事件驱动有三要素:1、事件源;2、事件监听器;3、事件处理器;
redis文件事件处理器分为四部分:
套接字、i/o多路复用、事件分发器、事件处理器

redis连接使用的是非阻塞io多路复用,将每个连接事件放入队列中,然后由一个单线程去消费这个队列并将事件根据状态分发给不同的事件处理器,这个单线程也叫事件分发器。被事件处理器处理后的事件状态会被改变,这个时候此事件会被事件分发器再次根据事件状态分发给对应的事件处理器。结合上面的事件驱动模型,redis客户端是事件源,事件分发处理器是事件监听器,事件处理器对应redis的事件处理器。
redis对数据结构做了很好的优化,在存储100k一下的数据时候,效率很高,memcahe不是对手。
单线程不能充分利用多核cpu的优势,上面这些内容最多可以解释redis为什么这么快,并不能解释为什么redis的线程模型要设计成单线程的,个人觉得既然设计者当初设计成单线程的,应该有一个很合适的理由。
官网的解答:
在多线程redis出现之前,redis官方的FAQ针对 单线程模型的redis如何利用多核cpu的解答,大概意思是:单线程的redis已经很快了,没必要使用多线程,如果先要使用多核cpu,可以在同一台机器上创建多个redis实例。
上面是早期的redis版本,现在都0202年了,截止到今天2020-05-23,redis官网公布的最新稳定版是redis6.0.3,redis的读支持了多线程,但是默认不开启,需要配置io-threads-do-reads yes
单线程处理任务的好处:
1、避免了锁的竞争(因为redis读写操作可能是同一个数据,单线程巧妙的避开了锁)
2、避免了线程上下文的切换
参考:
https://blog.csdn.net/xlgen157387/article/details/79470556
https://www.cnblogs.com/gz666666/p/12901507.html
《redis设计与实现》
https://www.javazhiyin.com/22943.html
https://www.javazhiyin.com/28400.html
https://juejin.im/post/5eb23787f265da7bb87727f7
https://www.cnblogs.com/jaycekon/p/6227442.html
以上是关于redis的自问自答的主要内容,如果未能解决你的问题,请参考以下文章