sqlalchemy基础教程
Posted cola_cola
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sqlalchemy基础教程相关的知识,希望对你有一定的参考价值。
一、基本配置
- 连接数据库
外部连接数据库时,用于表名数据库身份的一般是一个URL。在sqlalchemy中将该URL包装到一个引擎中,利用这个引擎可以扩展出很多ORM中的对象。
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker engine = create_engine(\'mysql+mysqldb://gaogao:123456@localhost:3360/demodb\') Session = sessionmaker(bind=engine)

- 表的表示
SQLALchemy一次只让操作一个库,所以操作基本上操作对象就是表。sqlalchemy就是将表抽象成一个类.
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import String,Column,Integer
engine =create_engine(\'mysql+mysqldb://gaogao:123456@localhost:3360/demodb\')
Session = sessionmaker(bind=engine)
Base = declarative_base()
class Student(Base):
__tablename__ = \'Students\'
Sno = Column(String(10),primary_key=True)
Sname = Column(String(20),nullable=False,unique=True,index=True)#nullable就是决定是否not null,unique就是决定是否unique(唯一),设置index可以让系统自动根据这个字段为基础建立索引
def __repr__(self):
return "<Student>{}:{}".format(self.Sname,self.Sno)
其中 __repr__方法不是必须的,只是写在这里来使得调试时更加容易分清楚是谁
有了这个类就相当于建立出了一张表,可以编写多个类来建立起多张表,要注意它们都要继承Base类哦!
- 启动实质性的连接
Base.metadata.create_all(engine) #这就是为什么表类一定要继承Base,因为Base会通过一些方法来通过引擎初始化数据库结构。不继承Base自然就没有办法和数据库发生联系了。 session = Session() #实例化了一个会话(或叫事务),之后的所有操作都是基于这个对象的 #既然是事务对象,session必然有以下这些方法 session.commit() #提交会话(事务) session.rollback() #回滚会话 session.close() #关闭会话
-
关于数据库中数据的对象在session中的四种状态
ORM模型很方便地将数据库中的一条条记录转变成了python中的一个个对象,有时候我们会想当然地把两者完全等同起来,但是不要忘了,两者之间还必须有session这个中间的桥梁。因为有session在中间做控制,所以必须注目对象和记录之间一个状态上的差别。一般而言,一个数据的对象可以有四种不同的和session关联的状态。从代码的流程上看:
session = Session() #创建session对象 frank = Person(name=\'Frank\') #数据对象得到创建,此时为Transient状态 session.add(frank) #数据对象被关联到session上,此时为Pending状态 session.commit() #数据对象被推到数据库中,此时为Persistent状态 session.close() #关闭session对象 print frank.name #此时会报错DetachedInstanceError,因为此时是Detached状态。 new_session = Session() print new_session.query(Person).get(1).name #可以查询到数据 new_session.close()
-
通过SQLAlchemy操作数据库
首先要说的是下面的内容默认都是通过ORM来进行操作,如果直接执行SQL的话,那么可以调用session.execute("SQL").fetchone/all(),这个和MySQLdb是一个意思,返回的也都是元组(的列表)这样子的数据。
操作数据库无非是增删查改,而正如上面所说的,通过SQLAlchemy的ORM方式来操作数据库的话都是基于session这个会话对象的。下面就来简单说说如何进行增删查改
这里想额外提一下的是,基于SQLAlchemy和ORM的操作不能独立于表类定义的。从下面的实例中可以看到,比如session做一个查询操作,后面要跟query(类名)。一般来说,最好能保证类中属性和数据库中表结构的完全对应,这是坠吼的。如果实在不能保证,比如有个现成的表在数据库中然而我只能知道部分表的信息,所以我只能构造出一个“阉割版”的类,这样的话是什么情况呢?经试验,编码层面的校验是以类为准,比如某个类中没写某个属性,那么即便这个属性确实存在于表中也无法访问到它,会报错“AttributeError”,而访问那些类和表中都存在的属性是可行的。这是针对类比表少了东西的情况,如果类比表多了一些属性,那么直接报错,不会给ORM机会访问库里的数据。从要构造类来模拟表结构这个角度看,ORM似乎还不如MySQLdb。。不过不要忘了,ORM的优势就是在于把数据转化为语言中的对象。所以构造一个类来模拟表结构的工作也无可厚非。。
● 新增
向一个表插入数据的话相当于是需要插入若干个这个表类的实例。所以可以初始化一些表类的实例后把它们作为数据源,通过session.add或者add_all方法来插入新数据。

###之前代码中出现的变量这里不再声明了### student = Student(Sno=\'10001\',Sname=\'Frnak\',Ssex=\'M\',Sage=22,Sdept=\'SFS\') session.add(student) session.commit() #不要忘了commit session.close() #可以通过一些手段实例化一批student出来放到一个列表students中,然后调用add_all session.add_all(students) session.commit() session.close()
● 查询
session.query(Student).filter(Student.Sname == \'Frank\').first()
这是一条比较经典的ORM查询语句,需要注意的地方很多。首先用了query方法来查询,方法参数指明了查询哪张表,这个参数应该是某个类,而跟类中的__tablename__的值是没多大关系的。然后调用了filter方法,filter方法的参数有些特别,是一个判断表达式(注意是两个等号!),它表示查询的条件。注意左边的字段名一定要加上类名.字段名,如果只写字段名SQLAlchemy将无法识别这个字段。最后是first()方法来表明返回第一个查询到的结果,也可以调用all()来返回所有结果的列表。如果没有这个first或者all的话那么返回的东西如果打印出来是一个SQL语句,对应着这个ORM查询。当查询结果不符合预期时可以打印出这个SQL来看一看问题在哪里。语句最终返回的一行数据的对象(或者它们组成的列表,first和all的区别),每个这种对象都可以通过object.attribute的方式来访问每个字段的值。
在filter这个位置,还可以添加多种多样的过滤器来实现灵活的查询,比如
filter(Student.Sname != \'Frank\')
filter(Student.id >= 10)
除了filter方法外还可以用filter_by方法,filter_by和filter的区别在于filter_by里面写得是kwargs形式的参数,且参数不用带表名。比如上面的filter(Student.Sname==\'Frank\')可以改写成filter_by(Sname="Frank")。个人感觉filter_by更加符合常规思维一点。不过它只能用于等值查询,要不等值,大于,小于查询的时候还是得用filter。
另外还有like方法进行模糊查询。用法是filter(Student.Sname.like("F%")),这个是查找所有F开头名字的学生的记录。
还有in_方法来进行“包括”过滤,用法filter(Student.Sname.in_([\'Frank\',\'Takanashi\']))。如果在filter方法所有参数最前面加上一个~,就是“非包括”过滤,比如刚才那个加上的话就是查询所有不叫Frank和Takanashi的学生了。
有is_方法,主要用来进行判空操作。filter(Student.Sdept.is_(None))就选择出了所有未填写院系信息的学生的记录,如果是filter(Student.Sdept.isnot(None))就是选择非空记录。其实is_和isnot可以通过filter中的==和!=来实现,两种方法效果是一样的。
~在filter参数中表示非逻辑,上面讲过了
还有and_和or_两个方法来表示并或逻辑,两者不是filter返回对象自带的方法,需要额外从sqlalchemy导入:
from sqlalchemy import and_,or_ print session.query(Student).filter(and_(Student.Sdept == \'SFS\' , Student.Sage < 22)).all() #上句选出了所有外院但是年龄小于22的学生记录,经测试也可以写3个及以上的条件参数 #or_方法也是类似的,不再多说
上面说的所有代替filter的方法顶多是代替了filter,后面还是要加上first或者all来获取具体结果。还有一个不需要额外加first和all的方法,就是在query的返回后面直接加get("主键的值")来获取特定主键的那一行数据的对象。
以上所有查询中query中只有一个参数(而且基本上都是表名),这其实相当于是SELECT 表名.* FROM 表名 [WHERE xxx]。其实在query方法参数中可以写子级字段,也可以写多个参数。比如:
session.query(Student.id,Student.name).filter(Student.name.like("F%")).all() #查询了所有名字F开头的学生的学号和姓名有意思的是,如果query参数写的只是一个表名,那么返回的列表是对象的列表。而如果我写出来若干个字段名的话,返回的列表其中每一项都是一个tuple,一个tuple里面就是一行内指定字段的值了。
● 删除
删除相对简单一些:
target = session.query(Student).get("10001") session.delete(target) session.commit()● 修改
修改的话直接在对象身上修改,修改可以反映到数据库中去
target = session.query(Student).filter(Student.Sname == "Kim").first() target.Sname = "Kimmy" session.commit() session.close() ##之后在到数据库后台,或者这里查询看到的就是Kimmy了 print session.query(Student).filter_by(Sname="Kimmy").first() #有结果
■ 表之间的关系
作为关系型数据库,关系可以说是最重要的一种逻辑结构了。上述所有涉及到表的设计中,都没有涉及到表之间的关系的确认。下面简单讲一下表之间的关系如何表现出来。
从编码层面上来讲,要进行两个表的关联主要做两件事,1.明确外键。2.用relationship函数关联两者。只声明了外键是什么没有relationship函数返回的属性做桥梁的话,关系在操作上的便利性体现不出来;如果只声明了关系而不明确外键的话,SQLAlchemy会不知道两者通过何种字段关联,从而报错。
下面来考虑这样一个场景:有一张User表,上面有id和name两个字段,一个id当然只有一个名字。另一张表Address记录了邮箱地址,有id,addr和user_id三个字段,因为一个user可能有多个邮箱地址,所以没有直接用user_id作为主键,而另起了一个主键。现在我想通过一个名字,查询到所有这个人的邮箱地址可以怎么做?一般而言,我可能会先查询User表中的id,然后去Address表的user_id字段中找相同的id。这样操作比较繁琐。如果可以为两张表添加一个关系,联系两张表在一起,这样从编码的角度来说就可以一句话就解决问题,比如:
from sqlalchemy import create_engine,Column,String,Integer,ForeignKey from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker,relationship engine = create_engine("mysql+mysqldb://weiyz:123@localhost:3306/test") Session = sessionmaker(bind=engine) Base = declarative_base() class User(Base): __tablename__ = \'users\' id = Column(Integer,primary_key=True) name = Column(String(20),nullable=False) addresses = relationship(\'Address\') class Address(Base): __tablename__ = \'address\' id = Column(Integer,primary_key=True) address = Column(String(20),nullable=False) user_id = Column(Integer,ForeignKey(\'users.id\')) #请注意,设置外键的时候用的是表名.字段名。其实在表和表类的抉择中,只要参数是字符串,往往是表名;如果是对象则是表类对象。 user = relationship(\'User\')经过上面的对表的定义,数据库中的users和address两张表就通过外键有了联系,为了利用好这种联系,我们就可以灵活运用User类中的addresses属性和Address类中的user属性了。这里说的运用,既可以指在类内直接调用,比如在Address中可以加入一个__repr__(self)方法,返回的信息中当然最好有地址所属人的名字,在没有联系时很难做到这一点,但是有了联系之后,现在只需要self.user.name就可以了。
再比如说,回到这节最前面说到的那个场景。想通过一个名字直接搜到他的所有邮箱地址,那么就可以直接调用属性:
session.query(User).filter_by(name="xxx").first().addresses
神奇的一点是,SQLAlchemy会根据关系的对应情况自动给关系相关属性的类型。比如这里的User下面的addresses自动是一个list类型,而Address下面的user由于设定了外键的缘故,一个地址最多只能应对一个用户,所以自动识别成一个非列表类型。
- 用backref做一点小改进
上面的例子中,我们分别为User和Address两个类分别添加了连到对方的关系。这么写好像略显繁琐一点,用from sqlalchemy.orm import backref的这个backref可以更加方便地一次性写清双向的关系。这就是直接把backref=\'user\'作为参数添加在addresses = relationship(\'Adress\',backref=\'user\')中,然后把user=relationship(xxx)直接删掉。或者反过来把backref添加在user中再把addresses删掉。
- 关于relationship方法的一些参数
relationship方法除了传递一个类名和可以加上backref之外,还有一些其他的参数。比如还有uselist=True/False这样一个参数。让uselist成为False之后,所有原先因为有多条结果而成为list类型的关系属性,比如上面例子中的User类下的addresses这个属性,会变成一个单个的变量。同时对于确实是有多个结果的情况系统会给出一个警告。总之,让uselist=False之后可以让这个关系每次通过关系来调用数据的时候都是fetchone而不是fetchall。
relationship还有另外一个参数,就是lazy。这个参数更加复杂一些。一般而言,就像上面的例子一样,我们通过关系属性来通过一个表的查询对象查询另一个表中的数据,形式上来说是直接.addresses就得到结果了。这是lazy="select"(默认是select)的结果。有时候,直接这么获得的数据比较多比较大,比如一个人有成千上万个邮箱地址的话,或许我不想这么直白地列出所有数据,而是对这些数据做一个二次加工。这时候就要用到lazy="dynamic"模式。在这个模式下,.addresses得到的仍然是一个query对象,所以我们可以进一步调用filter之类的方法来缩小范围。为了提高lazy的使用正确性,SQLAlchemy还规定了,不能再多对一,一对一以及uselist=False的这些模式的关系中使用。
-
关于多对多关系
上面这个例子一个用户对应多个地址,而一个地址只对应一个用户,所以说是一个一对多关系。在现实问题中还有很多多对多关系,比如老师和班级,一个老师可能在很多班级任教,而一个班级显然也有很多不同科目的老师。这种就是多对多关系。
在利用ORM进行多对多关系的抽象时通常需要一个第三表来承载这种关系,且在老师和班级表中都不能设置外键,一旦设置外键就表明这个每一行这个字段的值只能对应一个值了,又变回一对多关系。总之多对多关系可以像下例中一样构造:
class Class(Base):
__tablename__ = \'class\'
class_id = Column(Integer,primary_key=True)
name = Column(String(20),nullable=False)
#这里不加teacher = Column(Integer,ForeignKey(\'teacher.teacher_id\'))之类的字段,因为这样又会变回一对多关系
#为了篇幅其他字段就不加了,意思意思
class_teacher = relationship(\'ClassTeacher\',backref=\'class\')
class Teacher(Base):
__tablename__ = \'teacher\'
teacher_id = Column(Integer,primary_key=True)
name = Column(String(20),nullable=False)
#同样,这里也不用加class = xxx
teacher_class = relationship(\'ClassTeacher\',backref=\'teacher\')
class ClassTeacher(Base):
__tablename__ = \'class_teacher\' #这就是所谓的一张视图表?没有实际存在数据,但是凭借关系型数据库的特点可以体现出一些数据关系
teacher_id = Column(Interger,ForeignKey(\'teacher.teacher_id\'),primary_key=True)
class_id = Column(Interger,ForeignKey(\'class.class_id\'),primary_key=True)
#这张第三表中有两个主键,表示不能有class_id和teacher_id都相同的两项
###可以看到,通过第三表做桥梁,把多对多关系架构了起来。实际运用可以参考下面###
class = session.query(Class).filter(Class.name == \'三年二班\').first()
for class_teacher_rel in class.class_teacher:
print class_teacher_rel.teacher.name
"""这里比较绕了,首先class是查询得到的Class表中的一条记录的对象,调用class_teacher属性,通过在Class中设置的关系链接到ClassTeacher表中,得到一个列表
,每项都是这个class相关的teacher的关系(不是teacher对象本身而是ClassTeacher对象,可以理解成是一种关系的对象)。
然后根据在Teacher中定义的backref,通过ClassTeacher反向调用teacher就可以获得Teacher对象了。接下来再调用name属性就没什么可说的了。"""
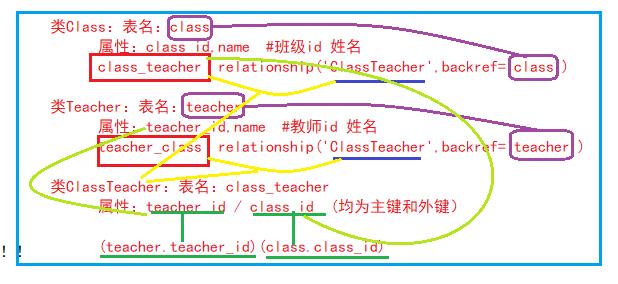
看图更清楚。。
例子通俗的解释:

以上是关于sqlalchemy基础教程的主要内容,如果未能解决你的问题,请参考以下文章