SparkSQL
Posted kris12
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkSQL相关的知识,希望对你有一定的参考价值。
1. Hive and SparkSQL
sparkSQL的前身是Shark。 Hive是早期唯一运行在Hadoop上的SQL-on-Hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了
提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生,其中表现较为突出的是:Drill、Impala、Shark。
Shark是伯克利实验室Spark生态环境的组件之一,是基于Hive所开发的工具,它修改了下图所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上。
Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),制约了Spark的发展,所以提出了SparkSQL项目。
SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖
性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
2014年6月1日Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目上,至此,Shark的发展画上了句话,但也因此发展出两
个支线:SparkSQL和Hive on Spark。
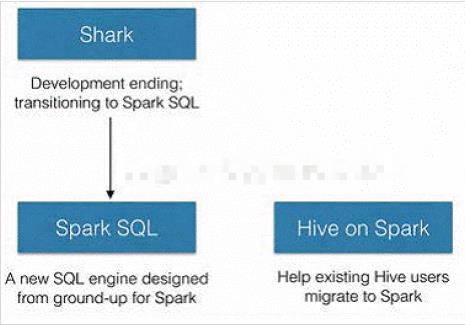
其中SparkSQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive;而Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,
Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎。
对于开发人员来讲,SparkSQL可以简化RDD的开发,提高开发效率,且执行效率非常快,实际工作中,基本上采用的就是SparkSQL。Spark SQL为了简化RDD的开发,提高开发效率,提供了2个编程抽象,DataFrame 、DataSet
2. Spark SQL
特点
易整合;无缝的整合了 SQL 查询和 Spark 编程

统一的数据访问; 使用相同的方式连接不同的数据源

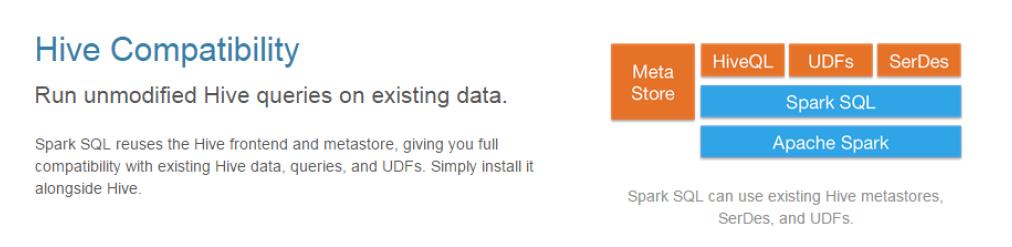
兼容 Hive; 在已有的仓库上直接运行 SQL 或者 HiveQL
SparkSession
在spark2.0中,引入SparkSession(作为DataSet和DataFrame API的切入点)作为Spark最新的SQL查询起始点,实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext); 为了向后兼容,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。
SparkSession内部封装了sparkContext、SparkConf、SQLContext,所以计算实际上是由sparkContext完成的。
---- 为用户提供一个统一的切入点使用Spark 各项功能
---- 允许用户通过它调用 DataFrame 和 Dataset 相关 API 来编写程序
--- 与 Spark 交互之时不需要显示的创建 SparkConf, SparkContext 以及 SQlContext,这些对象已经封闭在 SparkSession 中
DataFrame
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示
的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优
化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从 API 易用性的角度上看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API 要更加
友好,门槛更低。
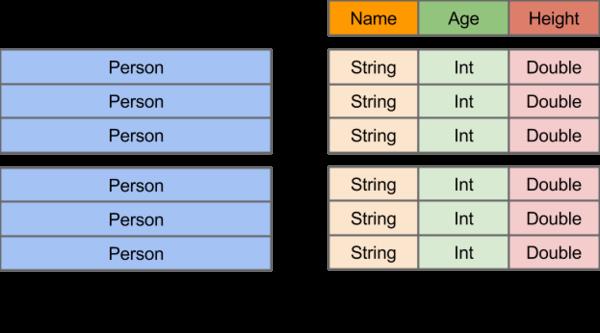
上图直观地体现了DataFrame和RDD的区别。
左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道该数
据集中包含哪些列,每列的名称和类型各是什么。
DataFrame是为数据提供了Schema的视图。可以把它当做数据库中的一张表来对待
DataFrame也是懒执行的,但性能上比RDD要高,主要原因:优化的执行计划,即查询计划通过Spark catalyst optimiser进行优化。比如下面一个例子:
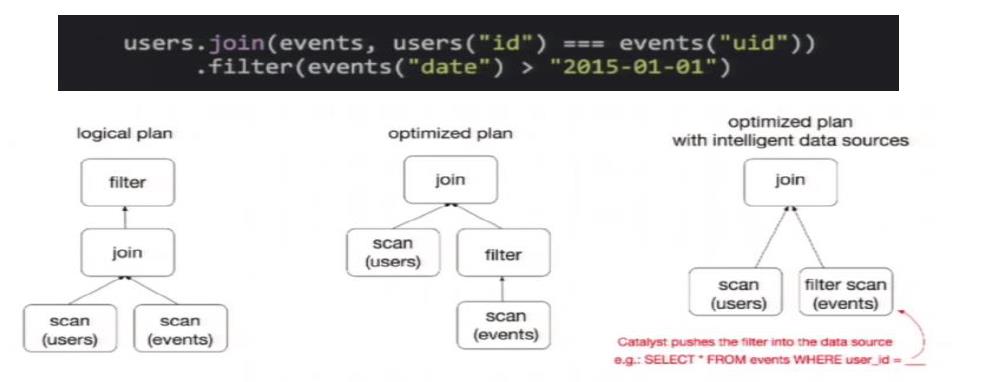
图中构造了两个DataFrame,将它们join之后又做了一次filter操作。如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为join是一个代价较大的操作,也可能会产生一
个较大的数据集。如果我们能将filter下推到 join下方,先对DataFrame进行过滤,再join过滤后的较小的结果集,便可以有效缩短执行时间。而Spark SQL的查询优化器正是这样做
的。简而言之,逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程。
DataSet
DataSet是分布式数据集合。DataSet是Spark 1.6中添加的一个新抽象,是DataFrame的一个扩展。它提供了RDD的优势(强类型,使用强大的lambda函数的能力)以及Spark SQL优
化执行引擎的优点。DataSet也可以使用功能性的转换(操作map,flatMap,filter等等)。
- DataSet是DataFrame API的一个扩展,是SparkSQL最新的数据抽象
- 用户友好的API风格,既具有类型安全检查也具有DataFrame的查询优化特性;
- 用样例类来对DataSet中定义数据的结构信息,样例类中每个属性的名称直接映射到DataSet中的字段名称;
- DataSet是强类型的。比如可以有DataSet[Car],DataSet[Person]。
- DataFrame是DataSet的特列,DataFrame=DataSet[Row] ,所以可以通过as方法将DataFrame转换为DataSet。Row是一个类型,跟Car、Person这些的类型一样,所有的表结构信息都用Row来表示。获取数据时需要指定顺序
3. Spark SQL核心编程
如何使用 Spark SQL所提供的 DataFrame和DataSet模型进行编程,以及了解它们之间的关系和转换。
Spark Core中,如果想要执行应用程序,需要首先构建上下文环境对象SparkContext,Spark SQL其实可以理解为对Spark Core的一种封装,不仅仅在模型上进行了封装,上下文环境
对象也进行了封装。
在老的版本中,SparkSQL提供两种SQL查询起始点:一个叫SQLContext,用于Spark自己提供的SQL查询;一个叫HiveContext,用于连接Hive的查询。
SparkSession是Spark最新的SQL查询起始点,实质上是SQLContext和HiveContext的组合,所以在SQLContex和HiveContext上可用的API在SparkSession上同样是可以使用的。
SparkSession内部封装了SparkContext,所以计算实际上是由sparkContext完成的。
当我们使用 spark-shell 的时候, spark框架会自动的创建一个名称叫做spark的SparkSession对象,就像我们以前可以自动获取到一个sc来表示SparkContext对象一样
DataFrame
Spark SQL的DataFrame API 允许我们使用 DataFrame 而不用必须去注册临时表或者生成 SQL 表达式。DataFrame API 既有 transformation操作也有action操作。
创建 DataFrame
在Spark SQL中SparkSession是创建DataFrame和执行SQL的入口,创建DataFrame有三种方式:
通过Spark的数据源进行创建;从一个存在的RDD进行转换;还可以从Hive Table进行查询返回。
1) 从Spark数据源进行创建
查看Spark支持创建文件的数据源格式
scala> spark.read.
csv format jdbc json load option options orc parquet schematable text textFile
在spark的bin/data目录中创建user.json文件 {"username":"shero","age":18}
读取json文件创建DataFrame
scala> val df = spark.read.json("data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
scala> df.show
+---+--------+
|age|username|
+---+--------+
| 18| shero|
+---+--------+
注意:如果从内存中获取数据,spark可以知道数据类型具体是什么。如果是数字,默认作为Int处理;
但是从文件中读取的数字,不能确定是什么类型,所以用bigint接收,可以和Long类型转换,但是和Int不能进行转换
2) 从RDD进行转换
3) 从Hive Table进行查询返回
SQL 语法
SQL语法风格是指我们查询数据的时候使用SQL语句来查询,这种风格的查询必须要有临时视图或者全局视图来辅助。
scala> val df = spark.read.json("data/user.json")
##转化成sql去执行
scala> df.createOrReplaceTempView("user") //对DataFrame创建一个临时表; view是table的查询结果,只能查不能改
scala> spark.sql("select * from user").show //通过sql语句来查询全表。
+----+--------+
| age|username|
+----+--------+
| 18| shero|
| 20| kris|
|null| andy|
+----+--------+
scala> spark.sql("select * from user where age is not null").show
+---+--------+
|age|username|
+---+--------+
| 18| shero|
| 20| kris|
+---+--------+
注意:普通临时view是Session范围内的,如果想应用范围内有效,可以使用全局临时表。使用全局临时表时需要全路径访问,如:global_temp.people
scala> df.createGlobalTempView("emp") //提升为全局
scala> spark.sql("select * from user where age is not null").show
+---+--------+
|age|username|
+---+--------+
| 18| shero|
| 20| kris|
+---+--------+
scala> spark.sql("select * from emp where age is not null").show //sql默认从当前session中查找,所以查询时需要加上global_temp
scala> spark.sql("select * from global_temp.emp where age is not null").show
//等同于 spark.newSession().sql("select * from global_temp.emp").show
+---+--------+
|age|username|
+---+--------+
| 18| shero|
| 20| kris|
+---+--------+
DSL风格语法
DataFrame 提供一个特定领域语言(domain-specific language, DSL --模仿面向对象的方式)去管理结构化的数据。
可以在Scala、Java、Python和 R中使用DSL,使用DSL语法风格不必去创建临时视图了。
scala> df.printSchema //查看DataFrame 的Schema信息
root
|-- age: long (nullable = true)
|-- username: string (nullable = true)
scala> df.select("age").show //只查看"age"列数据
+----+
| age|
+----+
|null|
| 30|
| 19|
+----+
scala> df.select($"age"+1).show
+---------+
|(age + 1)|
+---------+
| null|
| 31|
| 20|
+---------+
df.select($"username", $"age" + 1).show
+--------+---------+
|username|(age + 1)|
+--------+---------+
| shero| 19|
| kris| 21|
| andy| null|
+--------+---------+
df.filter($"age" > 20).show
df.groupBy("age").count.show
+----+-----+
| age|count|
+----+-----+
|null| 1|
| 18| 1|
| 20| 1|
+----+-----+
RDD转成DF
注意:如果需要RDD与DF或者DS之间操作,那么都需要引入 import spark.implicits._ 【spark不是包名,而是创建sparkSession对象的变量名称】
spark-shell中无需再导入,自动完成此操作。
前置条件:导入隐式转换并创建一个RDD
实际开发中,一般通过样例类将RDD转换为DataFrame
case class User(age:Int, name:String)
sc.makeRDD(List( (20, "kris"),(18, "shelo"))).map(t => User(t._1, t._2)).toDF.show
sc.makeRDD(List(("a",1), ("b",4), ("c", 3))).toDF("name", "count").show
+----+-----+
|name|count|
+----+-----+
| a| 1|
| b| 4|
| c| 3|
+----+-----+
DF转换为RDD
DataFrame其实就是对RDD的封装,所以可以直接获取内部的rdd
scala> df.show
+----+--------+
| age|username|
+----+--------+
| 18| shero|
| 20| kris|
|null| andy|
+----+--------+
scala> df.rdd
res38: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[158] at rdd at <console>:26
scala> val rdd = df.rdd
rdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[158] at rdd at <console>:26
scala> rdd.collect
res40: Array[org.apache.spark.sql.Row] = Array([18,shero], [20,kris], [null,andy])
scala> val array = rdd.collect //此时得到的RDD存储类型为Row
array: Array[org.apache.spark.sql.Row] = Array([18,shero], [20,kris], [null,andy])
scala> array(0)
res41: org.apache.spark.sql.Row = [18,shero]
scala> array(0).getAs[String]("username")
res47: String = shero
scala> array(0)(0)
res42: Any = 18
DataSet
DataSet是具有强类型的数据集合,需要提供对应的类型信息。
创建DataSet
1) 使用样例类序列创建DataSet
scala> case class Person(name: String, age: Long)
defined class Person
scala> val caseClassDS = Seq(Person("kris", 20)).toDS()
caseClassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
scala> caseClassDS.show
+----+---+
|name|age|
+----+---+
|kris| 20|
+----+---+
2)使用基本类型的序列创建DataSet
scala> val ds = Seq(1,2,3).toDS
ds: org.apache.spark.sql.Dataset[Int] = [value: int]
scala> ds.show
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
+-----+
在实际使用的时候,很少用到把序列转换成DataSet,更多的是通过RDD来得到DataSet
RDD转换为DataSet
SparkSQL能够自动将包含有case类的RDD转换成DataSet,case类定义了table的结构,case类属性通过反射变成了表的列名。Case类可以包含诸如Seq或者Array等复杂的结构。 DataSet是具有强类型的数据集合,需要提供对应的类型信息。
scala> case class User(name:String, age:Int)
defined class User
scala> sc.makeRDD(List(("kris", 20), ("shero", 18))).map(t=>User(t._1, t._2)).toDS
res54: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
DataSet转换为RDD
DataSet其实也是对RDD的封装,所以可以直接获取内部的RDD, 调用rdd方法即可
scala> val ds = Seq(Person(25, "Andy")).toDS()
ds: org.apache.spark.sql.Dataset[Person] = [age: int, name: string]
scala> ds.rdd.collect
res59: Array[Person] = Array(Person(25,Andy))
DataFrame和DataSet转换
DataFrame其实是DataSet的特例,所以它们之间是可以互相转换的。
spark.read.json(“ path ”)即是DataFrame类型;
DataFrame-->DataSet
scala> case class User(name:String, age:Int)
defined class User
scala> val df = sc.makeRDD(List(("kris", 20), ("shero", 18))).toDF("name", "age")
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> val ds = df.as[User]
ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
scala> ds.show
+-----+---+
| name|age|
+-----+---+
| kris| 20|
|shero| 18|
+-----+---+
DataSet-->DataFrame
这种方法就是在给出每一列的类型后,使用as方法,转成Dataset,这在数据类型是DataFrame又需要针对各个字段处理时极为方便。在使用一些特殊的操作时,一定要加上 import spark.implicits._ 不然toDF、toDS无法使用。
scala> ds.toDF
res74: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
RDD 、 DataFrame 、 DataSet 三者的关系
在SparkSQL中Spark为我们提供了两个新的抽象,分别是DataFrame和DataSet。他们和RDD有什么区别呢?首先从版本的产生上来看:
- ➢ Spark1.0 => RDD
- ➢ Spark1.3 => DataFrame
- ➢ Spark1.6 => Dataset
如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不同是的他们的执行效率和执行方式。
在后期的Spark版本中,DataSet有可能会逐步取代RDD和DataFrame成为唯一的API接口。
三者的共性
- RDD、DataFrame、DataSet全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利;
- 三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算;
- 三者有许多共同的函数,如filter,排序等;
- 在对DataFrame和Dataset进行操作许多操作都需要这个包:import spark.implicits._(在创建好SparkSession对象后尽量直接导入)
- 三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
- 三者都有partition的概念
- DataFrame和DataSet均可使用模式匹配获取各个字段的值和类型
三者的区别
联系:RDD、DataFrame、DataSet三者的联系是都是spark当中的一种数据类型,RDD是SparkCore当中的,DataFrame和DataSet都是SparkSql中的,它俩底层都基于RDD实现的;
区别:RDD 优点: ①编译时类型安全 ;②面向对象的编程风格 ; ③直接通过类名点的方式来操作数据; 缺点是通信or IO操作都需要序列化和反序列化的性能开销 ,比较耗费性能; GC的性能开销 ,频繁的创建和销毁对象, 势必会增加GC;
DataFrame引入了schema和off-heap堆外内存不会频繁GC,减少了内存的开销; 缺点是类型不安全;
DataSet结合了它俩的优点并且把缺点给屏蔽掉了;
1. RDD: ① RDD一般和spark mlib同时使用; ② RDD不支持sparksql操作
2. DataFrame:
1)与RDD和Dataset不同,DataFrame每一行的类型固定为Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值,
testDF.foreach{
line =>
val col1=line.getAs[String]("col1")
val col2=line.getAs[String]("col2")
}
2)DataFrame与Dataset一般不与spark mlib同时使用
3)DataFrame与Dataset均支持sparksql的操作,比如select,groupby之类,还能注册临时表/视窗,进行sql语句操作,
如:dataDF.createOrReplaceTempView("tmp")
spark.sql("select ROW,DATE from tmp where DATE is not null order by DATE").show(100,false)
4)DataFrame与Dataset支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然
val saveoptions = Map("header" -> "true", "delimiter" -> "\\t", "path" -> "hdfs://hadoop102:9000/test") //保存
datawDF.write.format("com.atguigu.spark.csv").mode(SaveMode.Overwrite).options(saveoptions).save() //读取
val options = Map("header" -> "true", "delimiter" -> "\\t", "path" -> "hdfs://hadoop102:9000/test")
val datarDF= spark.read.options(options).format("com.atguigu.spark.csv").load()
利用这样的保存方式,可以方便的获得字段名和列的对应,而且分隔符(delimiter)可以自由指定。
3. Dataset:
1)Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同。 DataFrame其实就是DataSet的一个特例 type DataFrame = Dataset[Row]
2)DataFrame也可以叫Dataset[Row],每一行的类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的getAS方法或者模式匹配拿出特定字段。而Dataset中,每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获得每一行的信息
case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型
/**
rdd
("a", 1)
("b", 1)
("a", 1)
**/
val test: Dataset[Coltest]=rdd.map{line=>
Coltest(line._1,line._2)
}.toDS
test.map{
line=>
println(line.col1)
println(line.col2)
}
可以看出,Dataset在需要访问列中的某个字段时是非常方便的,然而,如果要写一些适配性很强的函数时,如果使用Dataset,行的类型又不确定,可能是各种case class,无法实现适配,这时候用DataFrame即Dataset[Row]就能比较好的解决问题
互相转化
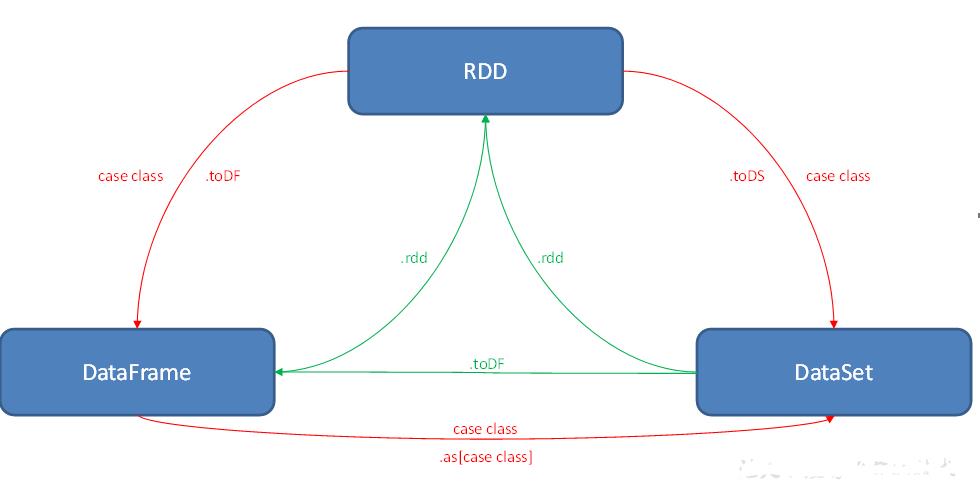
RDD关心数据,DataFrame关心结构,DataSet关心类型;
① 将RDD转换为DataFrame,需要增加结构信息,所以调用toDF方法,需要增加结构;
② 将RDD转换为DataSet,需要增加结构和类型信息,所以需要转换为指定类型后,调用toDS方法;
③ 将DataFrame转换为DataSet时,因为已经包含结构信息,只有增加类型信息就可以,所以调用as[类型]
④因为DF中本身包含数据,所以转换为RDD时,直接调用rdd即可;
⑤因为DS中本身包含数据,所以转换为RDD时,直接调用rdd即可;
⑥因为DS本身包含数据结构信息,所以转换为DF时,直接调用toDF即可
4. IDEA开发SparkSQL
RDD、DF、DS
添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12 </artifactId>
<version>3.0.0</version>
</dependency>
方式一:通过 case class 创建 DataFrames(反射)


import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame, SparkSession} object TestSparkSql { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("SparkSql").setMaster("local[*]") val sc: SparkSession = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate() // 将本地的数据读入 RDD, 并将 RDD 与 case class 关联 val peopleRdd = sc.sparkContext.textFile("file:\\\\F:\\\\Input\\\\people.txt") .map(line => People(line.split(",")(0),line.split(",")(1).trim.toInt)) import sc.implicits._ // 将RDD 转换成 DataFrames val df: DataFrame = peopleRdd.toDF //将DataFrames创建成一个临时的视图 df.createOrReplaceTempView("people") sc.sql("select * from people").show() //使用SQL语句进行查询 sc.stop() } } //定义case class,相当于表结构 case class People(var name: String, var age: Int)
说明:
① textFile默认是从hdfs读取文件; 本地文件读取 sc.textFile("路径"),在路径前面加上file:// 表示从本地文件系统读
② textFile可直接读取多个文件夹(嵌套)下的多个数据文件,如上边路径可写成 "file:\\\\F:\\\\Input" 读取这个目录下多个文件
方式二:通过 structType 创建 DataFrames(编程接口),测试代码如下
import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{DataFrame, SparkSession} object TestSparkSql { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("SparkSql").setMaster("local[*]") val sc: SparkSession = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate() // 将本地的数据读入 RDD val peopleRdd = sc.sparkContext.textFile("file:\\\\F:\\\\Input") // 将 RDD 数据映射成 Row,需要 import org.apache.spark.sql.Row import org.apache.spark.sql.Row val rowRDD: RDD[Row] = peopleRdd.map(line => { val fields = line.split(",") Row(fields(0), fields(1).trim.toInt) }) val structType: StructType = StructType( //字段名,字段类型,是否可以为空 StructField("name", StringType, true) :: StructField("age", IntegerType, true) :: Nil ) //将DataFrames创建成一个临时的视图 val df: DataFrame = sc.createDataFrame(rowRDD,structType) df.createTempView("people") sc.sql("select * from people").show() //使用SQL语句进行查询 sc.stop() } }
方式三:读取json文件
people.json 必须是在一行:
{"username":"swenna","age":18}
{"username": "kk","age":20}
//读取json数据 import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame, SparkSession} object TestSparkSql { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("SparkSql").setMaster("local[*]") val sc: SparkSession = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate() // 将本地的数据读入 RDD val df: DataFrame = sc.read.json("file:\\\\F:\\\\Input\\\\people.json") //将DataFrames创以上是关于SparkSQL的主要内容,如果未能解决你的问题,请参考以下文章