mysql_group by与聚合函数order by联合使用
Posted jingsx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql_group by与聚合函数order by联合使用相关的知识,希望对你有一定的参考价值。
最近测试项目数据统计模块,发现自己对group by函数以及联合使用聚合函数的使用其实根本没理解透彻。
前半部分算自己对项目遇到情况的总结,大家可忽略,直接看后半部分关于group by的使用即可!!!
前半部分:
业务逻辑背景:一个任务中,可以导入多个客户信息(包含caseId,号码、姓名等其他信息),客户信息以caseId作为唯一标识,即同一个任务中caseId不能相同,但客户手机号码可以相同。任务可配置自动重播功能(无人接听时,允许重播,重播次数可配置)
在进行呼叫次数统计时,其中一个规则是:同一个任务中,同一caseId的号码多次呼叫,呼叫次数仅计算一次
数据库:customer_profile存储客户信息;callout_session存储外呼记录相关信息,callout_task:存储任务相关信息
字段信息:
每次电话呼叫唯一标识:session_id
任务唯一标识:task_id
场景模板id:dialog_template_id
系统呼叫号码时间:callout_dial_time
求:某段时间内,某个场景模板中外呼电话总次数
错误sql语句:
select count(case_id) from
(select distinct(cp.case_id),ct.task_id,cs.session_id from callout_session cs
join callout_task ct on cs.task_id=ct.task_id
join customer_profile cp on cs.user_id = cp.user_id
where ct.dialog_template_id=\'1-1016-108\'
and callout_dial_time between \'2019-03-16 00:00:00\' and \'2019-04-02 23:59:59\'
group by case_id)A;
该sql语句为双重嵌套查询,这里仅分析内层查询,错误原因,在于group by case_id,将所有外呼记录中case_id相同的记录都合并成了一行,不符合规则“同一个任务中,同一caseId的号码多次呼叫,呼叫次数仅计算一次”
而正确语句中group by case_id,task_id即为将同时满足case_id值相同和task_id值相同的数据合并成一行,符合规则“同一个任务中,同一caseId的号码多次呼叫,呼叫次数仅计算一次”
正确sql语句:
select count(session_id) from
(select ct.task_id,cs.session_id,cp.case_id from callout_session cs
join callout_task ct on cs.task_id=ct.task_id
join customer_profile cp on cs.user_id = cp.user_id
where ct.dialog_template_id=\'1-1016-108\'
and callout_dial_time between \'2019-03-16 00:00:00\' and \'2019-04-02 23:59:59\'
group by task_id,case_id)A
后半部分:
1、group by:后接字段名,根据字段对数据进行分组
SQL语句:select task_id,session_id,customer_case_id,callout_connect_status from callout_session where callout_dial_time between \'2019-04-01 00:00:000\' and \'2019-04-03 23:59:59\' group by task_id,session_id
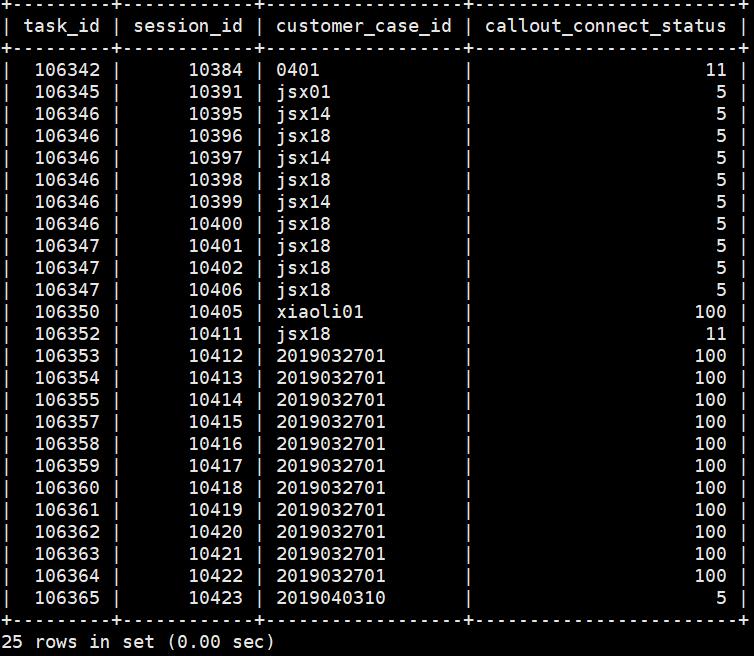
表1
1.1、单独使用group by 列名,不与聚合函数联合使用
group by后面跟一个列名task_id,起到了去重的作用,将task_id值相同的行合并成一行显示
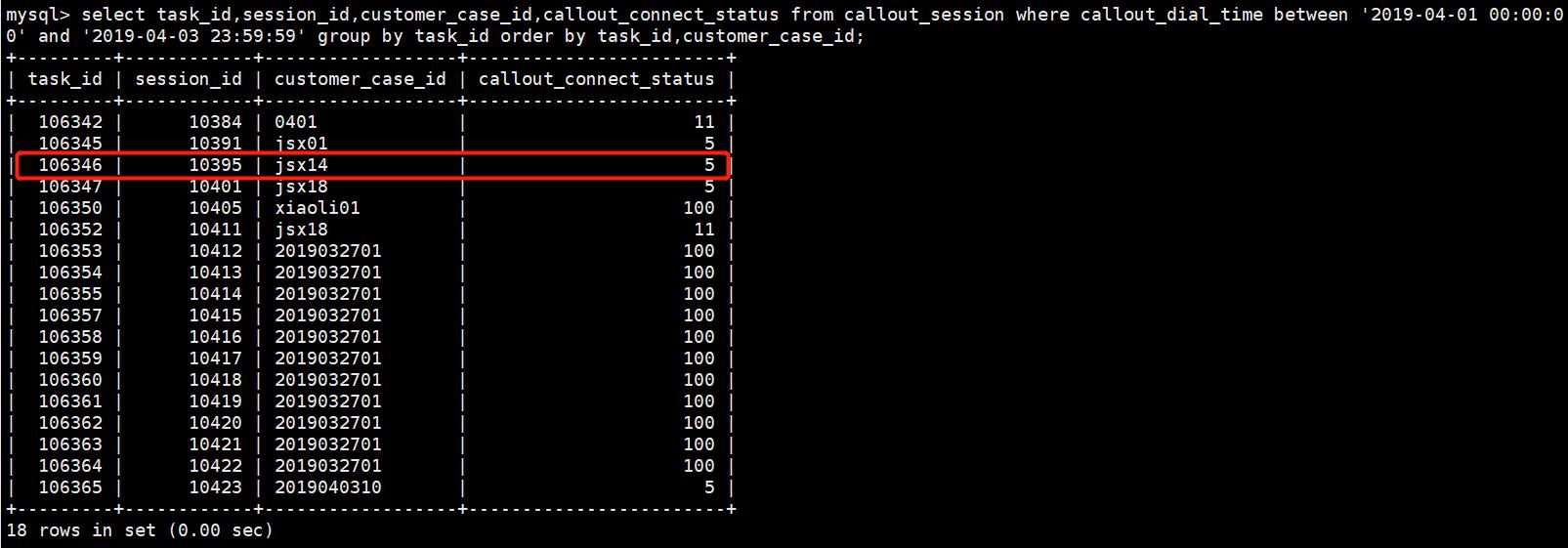
表1.1-1
group by后面跟两个列名task_id、customer_id:同样是去重作用,将同时满足task_id值相同、customer_id值相同的行合并成一行
注:这里不是合并task_id值与customer_id值相同的行,博主本人以前在这里就理解错了
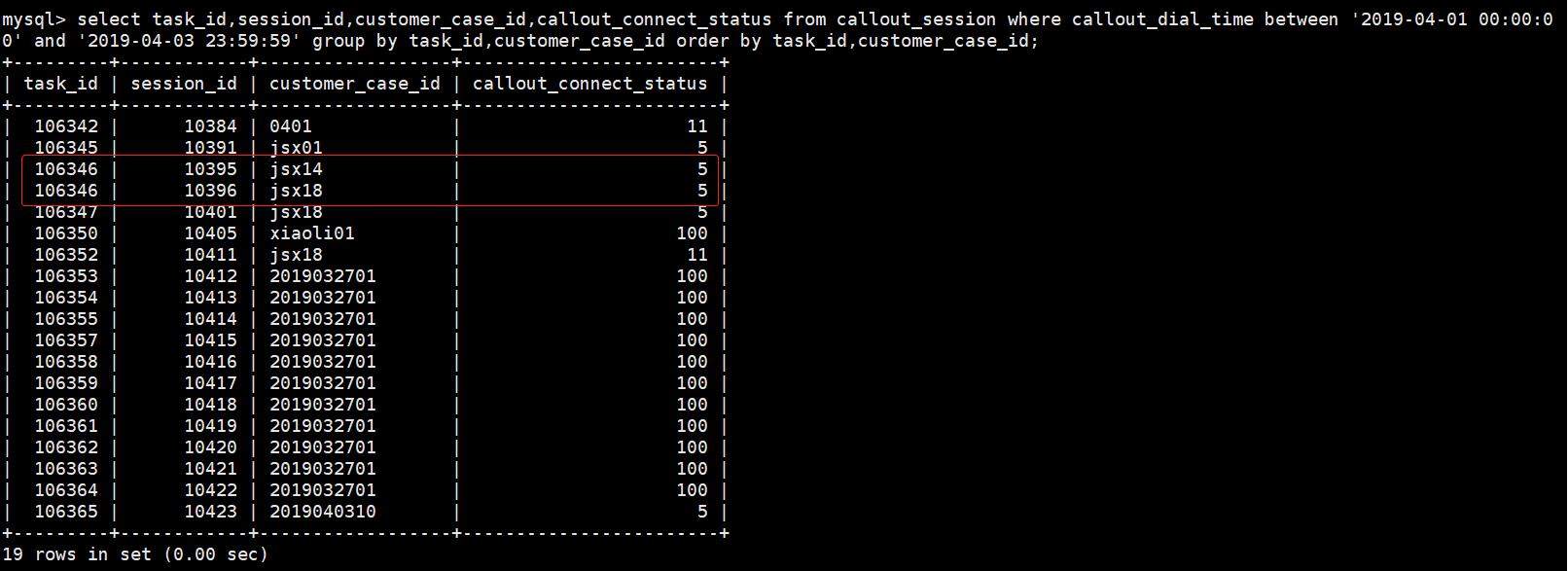
表1.1-2
1.2、group by与聚合函数使用
sql语句:select task_id,count(task_id),session_id,customer_case_id,callout_connect_status from callout_session where callout_dial_time between \'2019-04-01 9-04-01 00:00:00\' and \'2019-04-03 23:59:59\' group by task_id order by task_id,customer_case_id;
count(task_id) 这里统计了task_id值相同的行数量,与表1数据进行对比
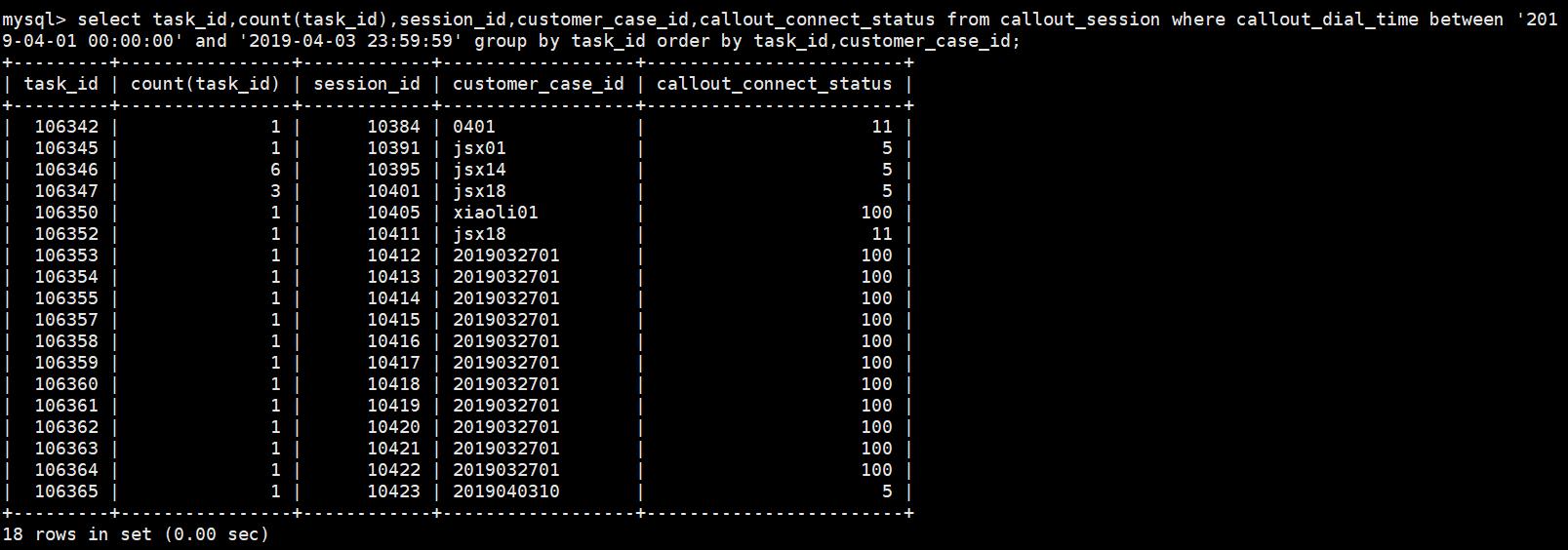
2、order by:对查询结果进行排序,后面跟字段名
order by 字段名 desc:降序排列
order by 字段名 asc:升序排列
以上是关于mysql_group by与聚合函数order by联合使用的主要内容,如果未能解决你的问题,请参考以下文章
聚合函数种类和功能有哪些和分组查询 group by 与 order by的区别?
聚合函数种类和功能有哪些和分组查询 group by 与 order by的区别?
oracle 之分析函数 over (partition by ...order by ...)
ORDER BY 子句中的列无效,因为它不包含在聚合函数或 GROUP BY 子句中
2018-07-10聚合函数+比较条件+''和NULL+DISTINCT+ORDER BY+LIMIT+GROUP BY