MySQL学习第七篇索引管理及执行计划
Posted busiren
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL学习第七篇索引管理及执行计划相关的知识,希望对你有一定的参考价值。
一.索引介绍
1.什么是索引?
索引由如字典,目的就是为了更快寻找到要找的内容。
令搜索查询的数据更有目的性,从而提高数据检索的能力
2.索引类型介绍
1.BTREE: B+树索引
2.HASH: HASH 索引
3.FULLTEXT: 全文索引
4.RTREE:R树索引
一般人不用懂上面4种算法!!!!!讲起来太特么麻烦了!!!!
简单介绍下hash索引一般就是查url的,网址一般都很长,查询则会变得十分麻烦,而hash则是令这一段url定义为一个hash值指向url,查找就是查这个hash值。
全文索引则是从非结构化中提取信息,从而使其变得有结构起来,如同字典一般。
R树索引,不讲,懂就懂了,靠悟性
主要讲解一下B+tree算法
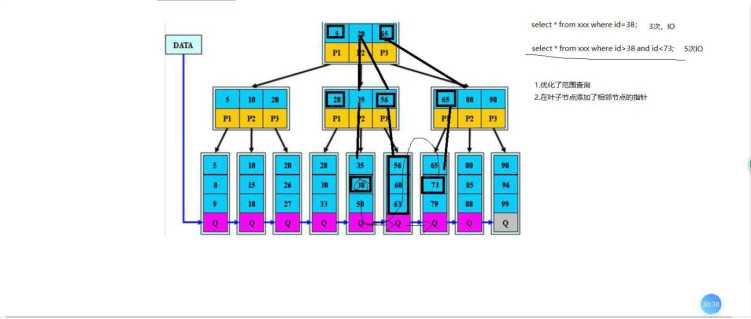
二.索引管理
1.特点
1.索引建立在表的列上(字段)
2.在where后面的列建立索引才会加快查询速度
3.pages<---索引(属性)<---查数据。
2.索引分类
1.主键索引:数据不能重复,不能为空
2.普通索引
3.唯一索引:可以为空
3.添加索引
1.创建索引
alter table test add index index_name(name);
另外一种方法
create index index_name on test(name);
2.查看索引
desc table;
另外。。。
show index from table;
3.删除索引
alter table test drop key index_name;
4.添加唯一性索引
alter table student add unique key uni_name(name);
4.前缀索引
1.根据字段的前N个字符建立索引,数据库数据太长,选择前几天作为索引,加快效率
alter table test add index idx_name(name(10));
2.优点
避免对大列建立索引,如果有大列的数据,就使用前缀索引
5.联合索引
alter table people add index idx_gam(a,b,c);
当你查询为abc,则查询走索引,查询为ab,部分走索引,查询a也部分走索引,但不以a开头,如bc,b,c都不走索引,但是b,a则部分走索引
6.explain详解
1.使用方法
mysql> explain select name,countrycode from city where id=1;

2.全表查询(在explain语句结果中的type为all)
当出现全表扫描:
1)业务确实要获取所有的数据
2)不走索引导致的全表扫描(没有索引,索引有问题,sql语句有问题)
生产中能避免避免,效率极差
3.索引扫描
索引至少到达range级别,性能从上倒下,由差到好
index
range
ref
eq_ref
const
system
null
4.index和all区别是all不走索引,而index则遍历索引树

5.range,索引范围查询,where里拥有>,<等条件,搜索的行数超过总的25%则为all

6.eq_ref ,类似ref,区别在于使用的索引是唯一索引,对于每个索引兼值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key 或者unique key 作为关联条件

7.const,system,实际上差距不大,所以合到一处。当mysql对查询部分进行优化,转化为一个常量,使用这类访问时,如将主键置于where列表中,mysql就能将该查询转化为一个常量

8.NULL,就是数据空中找不到该数据,没有,因为没有所以最快

7.一些问题
Using temporary
Using filesort (使用了默认的文件排序,如果使用了索引,会避免这类排序)
Using join buffer
如果出现Using filesort检查order by ,group by, distinct, join 条件列上应该是没有索引,当order by语句中出现Using filesort,那就尽量让排序值在where条件中出现,key_len越小越好,rows越小越好
mysql> explain select * from city where population>30000000 order by population;
以上是关于MySQL学习第七篇索引管理及执行计划的主要内容,如果未能解决你的问题,请参考以下文章