SQL查询优化
Posted anyv
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL查询优化相关的知识,希望对你有一定的参考价值。
SQL优化是老生常谈的话题。随着关系型数据库的发展,数据库内部现在可以进行一些优化。在查询分析,查询检查,数据库内部会代数优化和物理优化之后再执行。但是,这需要我们理解数据库内部规律才能进行。现在,我们需要找出RDBMS的优化规律,以写出适合RDBMS自动优化的SQL语句。只看SQL优化总结,可以翻到文章末尾。
先谈谈数据库内部的代数优化和物理优化,就是查询优化主要的两个部分。数据库查询过程的代价有IO,cpu,通信代价,内存代价,但是最要就是IO代价。
查询优化的优点 1、用户不必考虑如何最好地表达查询以获得较好的效率 2、系统可以比用户程序的“优化”做得更好
代数优化,按照一定的规则,通过对关系代数表达式进行等价变换,改变代数表达式中操作的次序和组合,使查询执行更高效。公式有很多,例如
1.连接、笛卡尔积交换律

2. 连接、笛卡尔积的结合律
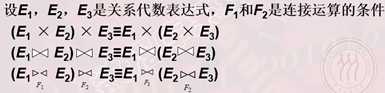
物理优化,就是要选择高效合理的操作算法或存取路径,求得优化的查询计划
1)基于规则的启发式优化
启发式规则是指那些在大多数情况下都适用,但不是在每种情况下都是最好的规则。
2)基于代价估算的优化
优化器估算不同执行策略的代价,并选出具有最小代价的执行计划。
3)两者结合的优化方法:
常常先使用启发式规则,选取若干较优的候选方案,减少代价估算的工作量
(定性)选择操作
对于小关系,使用全表顺序扫描,即使选择列上有索引
对于大关系,启发式规则有:
1)对于选择条件是“主码=值”的查询,查询结果最多是一个元组,可以选择主码索引,一般的RDBMS会自动建立主码索引
2)对于选择条件是“非主属性=值”的查询,并且选择列上有索引,要估算查询结果的元组数目,如果比例较小(<10%)可以使用索引扫描方法,否则还是使用全表顺序扫描
3)对于选择条件是属性上的非等值查询或者范围查询,并且选择列上有索引,要估算查询结果的元组数目,如果比例较小(<10%)可以使用索引扫描方法,否则还是使用全表顺序扫描
4)对于用AND连接的合取选择条件,如果有涉及这些属性的组合索引,优先采用组合索引扫描方法
5)对于用OR连接的析取选择条件,一般使用全表顺序扫描
(定性)连接操作
1)如果2个表都已经按照连接属性排序:选用排序-合并算法
2)如果一个表在连接属性上有索引,选用索引连接算法
3)如果上面2个规则都不适用,其中一个表较小,选用Hash join算法
(定量)工作量估计:
全表扫描算法 普通的全表扫描,cost=B 选择条件是“码=值”,那么平均搜索代价 cost=B/2
索引扫描算法 若为B+树,层数为L,需要存取B+树中从根结点到叶结点L块,再加上基本表中该元组所在的那一块,所以cost=L+1
如果比较条件是>,>=,<,<=操作,假设有一半的元组满足条件,就要存取一半的叶结点,通过索引访问一半的表存储块,cost=L+Y/2+B/2
排序-合并连接算法 如果连接表已经按照连接属性排好序,则cost=Br+Bs+(Frs*Nr*Ns)/Mrs
如果必须对文件排序还需要在代价函数中加上排序的代价 对于包含B个块的文件排序的代价大约是 (2*B)+(2*B*log2B)
根据以上理论,实际操作和他人经验,可以总结如下一些规律(仅供参考):
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。一个表的索引不能过多,过多不利于删除,插入等操作。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=205.in 和 not in 也要慎用,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
6.下面的查询也将导致全表扫描:
select id from t where name like ‘%abc%‘
7.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
8.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)=‘abc‘--name以abc开头的id
应改为:
select id from t where name like ‘abc%‘
9.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
10.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,
否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
11.不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(...)
12.很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
13.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引, 如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
14.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率, 因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定
一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
15.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。 这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
16.尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间, 其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
17.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
18.避免频繁创建和删除临时表,以减少系统表资源的消耗。
本文在自己学习和他人经验之上,提炼而成。初次写作,文章多有不足之处,不吝赐教。
文章引用:https://blog.csdn.net/jie_liang/article/details/77340905
http://www.cnblogs.com/smartloli/p/4356660.html
以上是关于SQL查询优化的主要内容,如果未能解决你的问题,请参考以下文章