Hadoop Mapreduce 工作机制
Posted Transkai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop Mapreduce 工作机制相关的知识,希望对你有一定的参考价值。
一.Mapreduce 中的Combiner


package com.gec.demo; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class WcCombiner extends Reducer<Text, IntWritable,Text,IntWritable> { private IntWritable sum=new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count=0; for (IntWritable value : values) { count+=value.get(); } sum.set(count); context.write(key,sum); } }
在job类中声明如下:
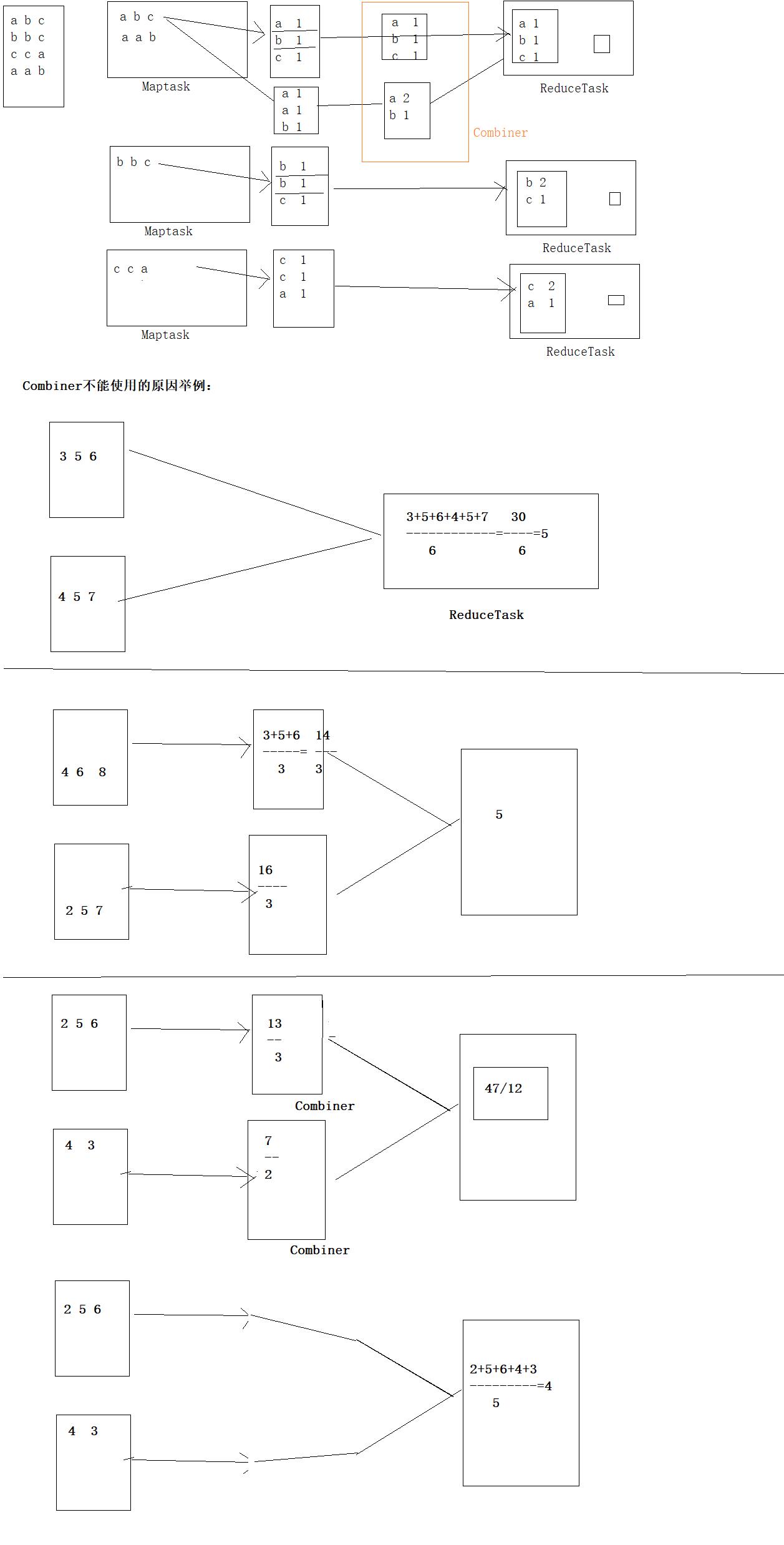
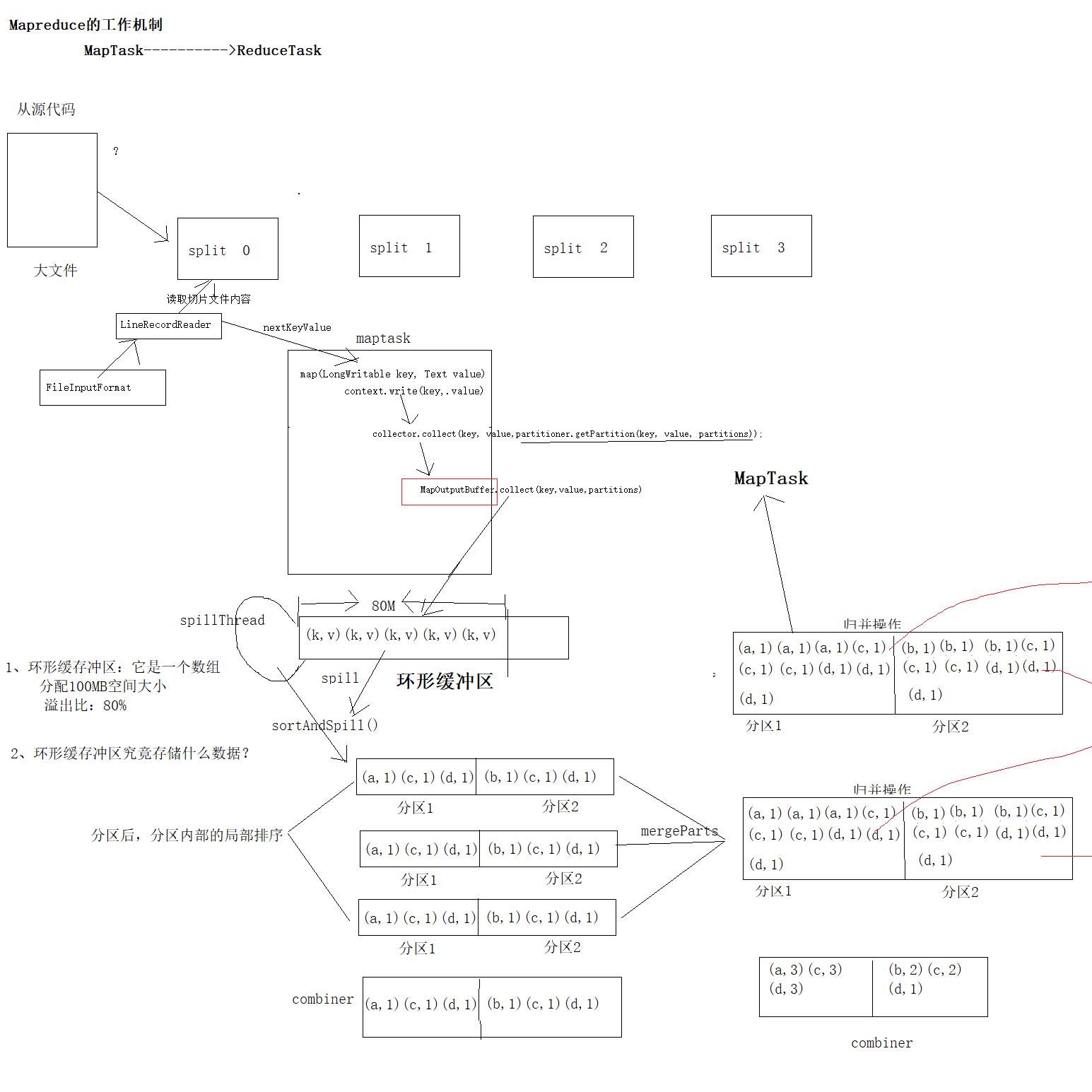
二.MapTask工作机制
主要的核心类:
读:
FileInputFormat
TextInputFormat
createRecordReader
LineRecordReader
nextKeyValue
写:
context.write
RecordWriter.write(k,value)
NewOutputCollector.write(key,value)
MapOutputCollector.collect(key,value,partitions)
MapOutputBuffer.collect(key,value,partitions)
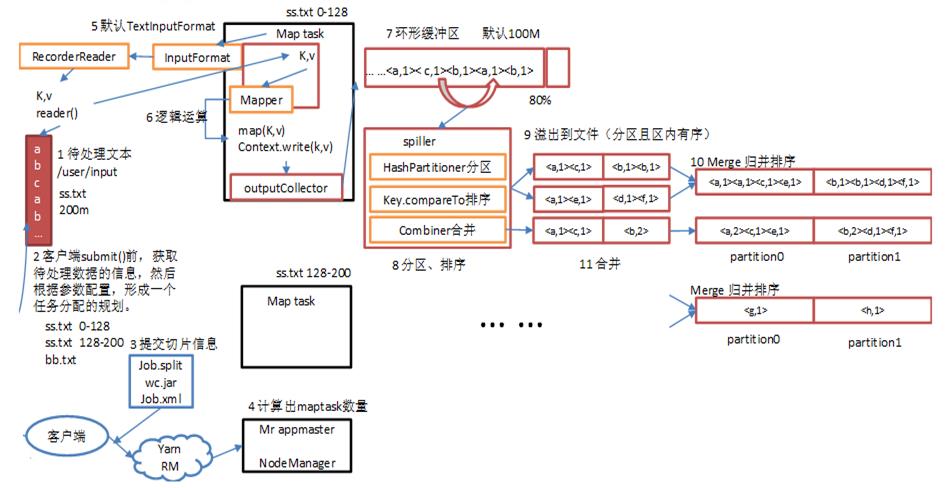
核心map输出源代码分析类
NewOutputCollector类
构造器:
实例化MapOutputBuffer对象
调用MapOutputBuffer对象init方法
将MapOutputBuffer对象赋值给collector对象
解决分区值问题
//如果没有自定义分区类,则默认使用HashPartitioner
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
环形缓冲区实现原理
MapOutputBuffer实现缓冲区的核心实现

在这一头存储key和value,key和value依次排列,而那一头存储索引,向中间出发,当储存的空间占比百分之八十的时候,则溢出,两者的方向改变,分别开始从另外一头开始存储
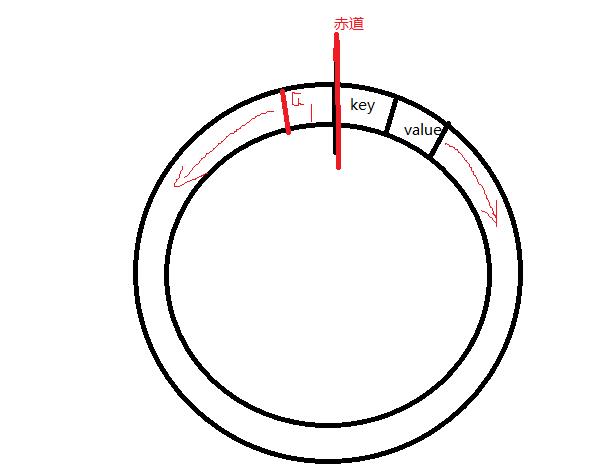
如上图,从赤道分别向不同方向出发
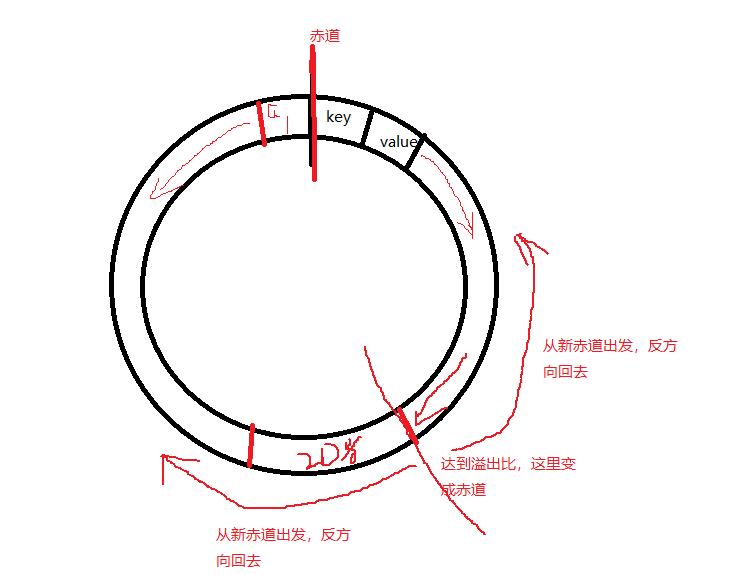
如上图,到达溢出时,产生新赤道,又分别从新赤道往回走
init方法
1、分配溢出比
final float spillper =job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8);
2、分配环形缓存区的大小
final int sortmb = job.getInt(JobContext.IO_SORT_MB, 100);
3、实例化快排对象
sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class",
QuickSort.class, IndexedSorter.class), job);
4、定义环形缓存区数组
kvmeta = ByteBuffer.wrap(kvbuffer)
.order(ByteOrder.nativeOrder()).asIntBuffer();
5、开始化赤道
setEquator(0);
6、获取key的比较器对象
comparator = job.getOutputKeyComparator();
7、是否定义combineCollector对象
8、启动spillThread线程,监听溢出比,触发此 sortAndSpill()
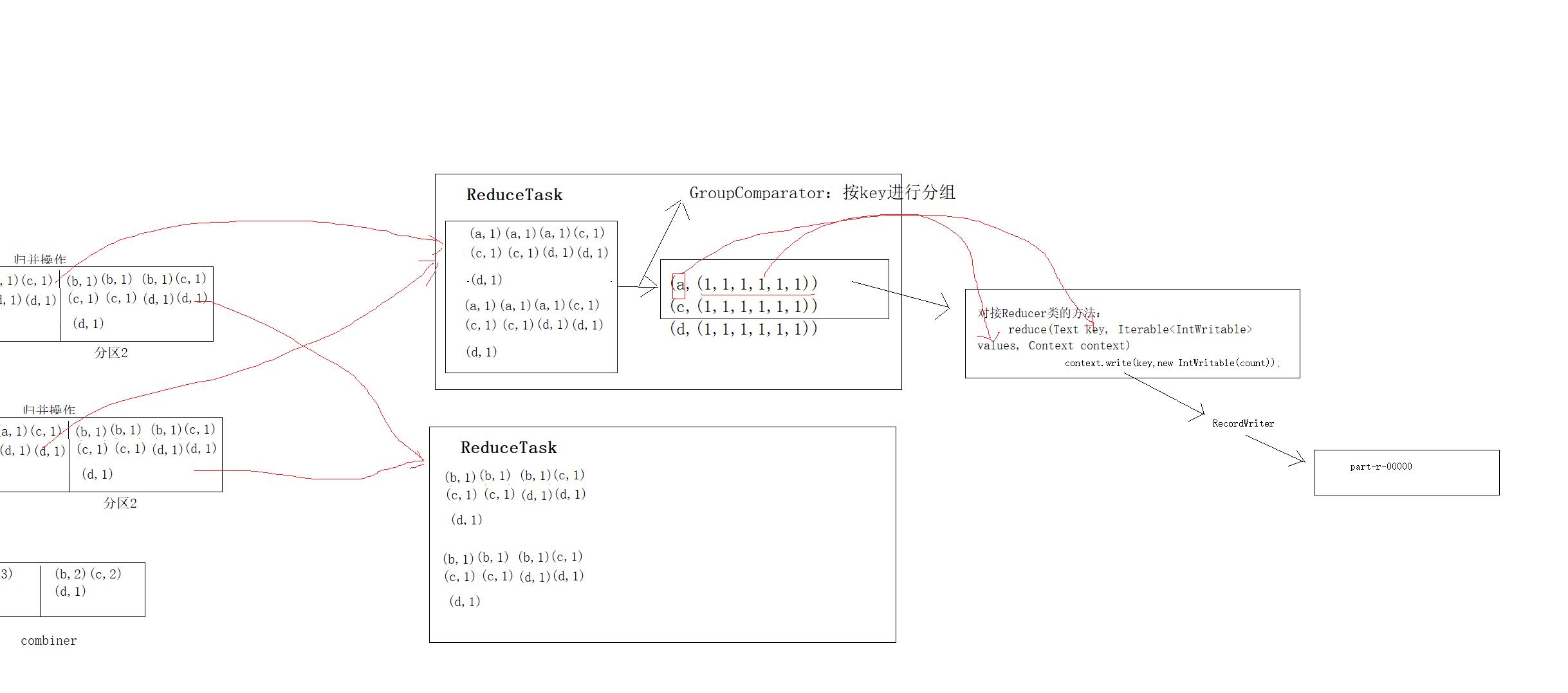
对接Reducer类的方法:
reduce(Text key, Iterable<IntWritable> values, Context context)
ReduceTask工作机制
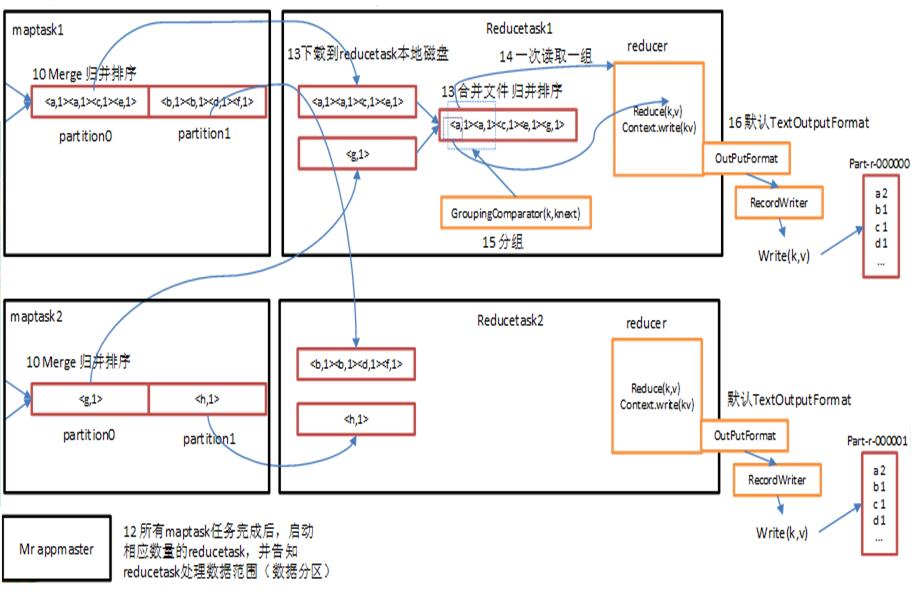
三.shuffer
shuffer缓存流程
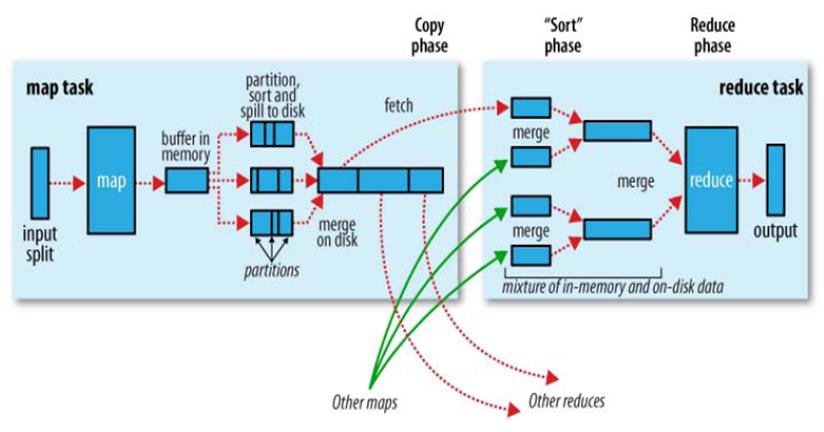

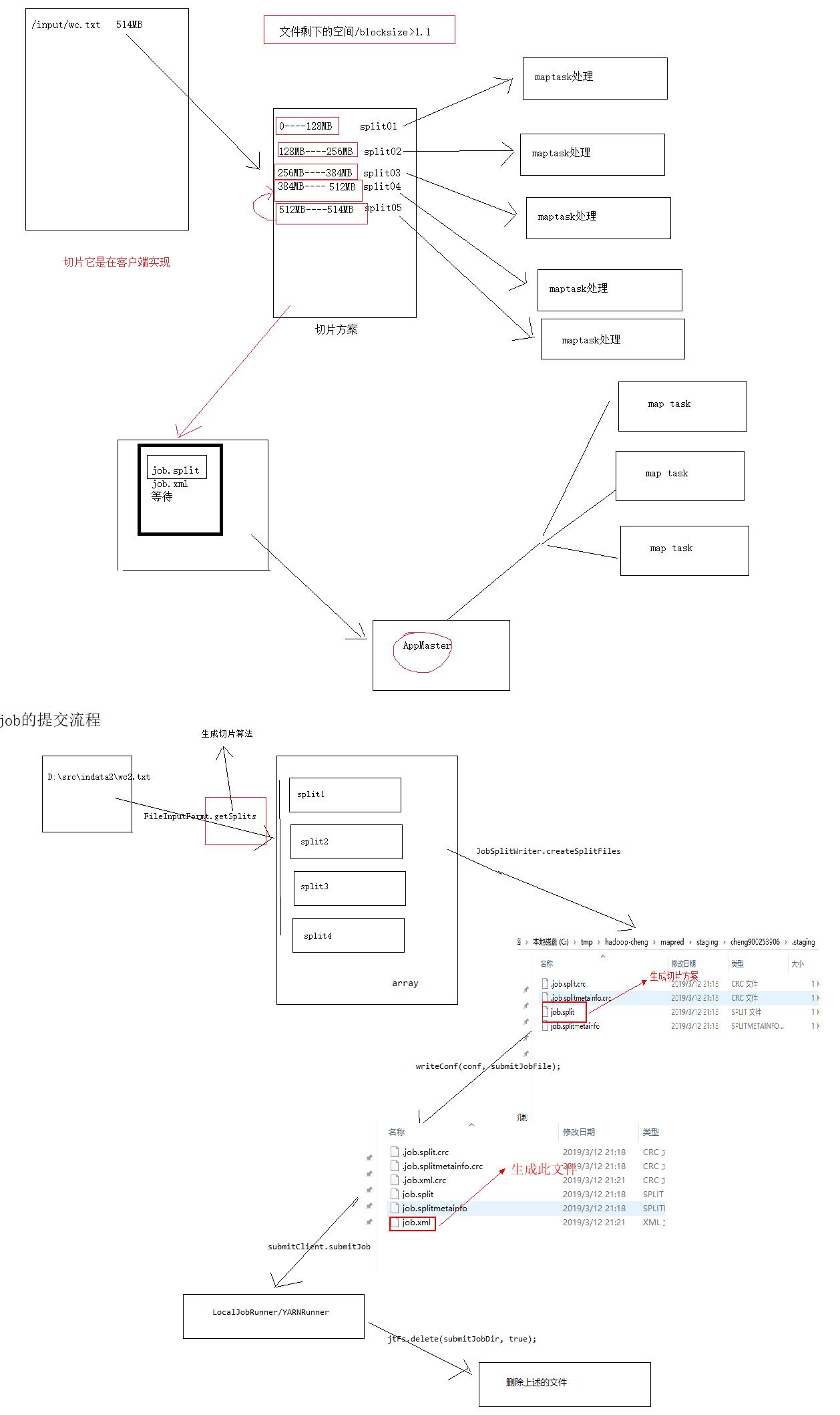
四.map切片过程
重点分析job类的
waitForCompletion方法
a、connect方法
根据mapreduce.framework.name的值,再决定
生成LocalJobRunner对象
生成YARNRunner对象
submitJobInternal
checkSpecs //输出路径的检查
copyAndConfigureFiles
生成
tmp\\hadoop-cheng\\mapred\\staging\\cheng1725886371\\.staging\\job_local1725886371_0001
writeSplit
实现切片的核心方法
InputFormat.input.getSplits(job)
long minSize =1;
long maxSize =9223372036854775807;
JobSplitWriter.createSplitFiles
submitClient.submitJob
以上是关于Hadoop Mapreduce 工作机制的主要内容,如果未能解决你的问题,请参考以下文章