从Oracle导出数据并导入到Hive
Posted 昊合DI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从Oracle导出数据并导入到Hive相关的知识,希望对你有一定的参考价值。
1、配置源和目标的数据连接
源(oracle):

目标(Hive 2.1.1)

系统自带2.1.1的驱动jar包,如果该版本无法兼容你的Hive,可将对应版本hive驱动jar包导入HHDI的lib目录中。
自带的jar包包括以下文件:
hadoop-common-2.6.0.jar
hive-common-2.1.0.jar
hive-jdbc-2.1.0.jar
hive-metastore-2.1.0.jar
hive-serde-2.1.0.jar
hive-service-2.1.0.jar
hive-service-rpc-2.1.0.jar
hive-shims-2.1.0.jar
jar包可通过这里查找下载:https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc/2.1.1
2、配置数据抽取任务,设定源和目标
源页签:
选择源数据连接和源表,生成查询语句,默认抽取该表中的所有字段和所有记录(20w条记录)

目标页签:
目标页签选择Hive数据连接后,界面判断如果是Hive2类型,会自动更新为Hive导入的配置界面,在本地缓存文件下拉框中选择“采用流方式上传HDFS”,并定义好列分隔符,行分隔符一般不用修改。每批提交行数是指每多少行会回显一次,数据量大时可相应调高。
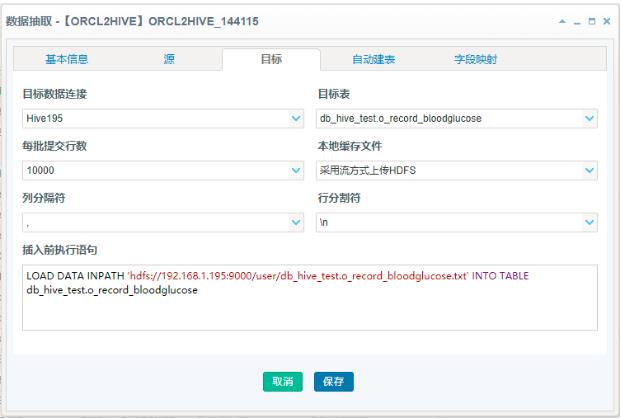
系统会根据Hive数据连接的配置和目标表名自动生成LOAD DATA 语句,其中包含文件上传到的HDFS地址,这个地址用户可以自行修改,也可以修改Load Data语句,增加适当的参数等等。需要注意的是,在HDFS上需要给这个HHDI的操作系统用户分配读写的权限,比如:hadoop fs -chmod -R 777 /user
注意:选择Hive作为目标导入时,“字段映射”页签中的配置是无效的。
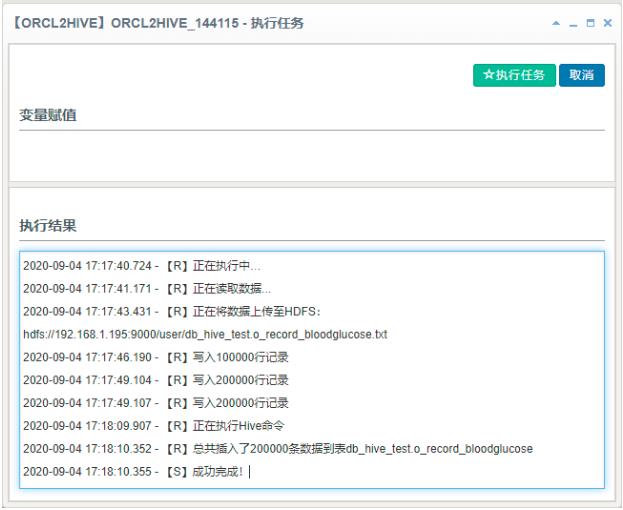
6、手工执行该抽取任务进行测试。服务器性能和带宽足够的情况下,真实环境实测3GB数据导入时间大约是1分半钟左右
HaoheDI让ETL变得简单,http://www.haohedi.com
以上是关于从Oracle导出数据并导入到Hive的主要内容,如果未能解决你的问题,请参考以下文章
Sqoop_具体总结 使用Sqoop将HDFS/Hive/HBase与MySQL/Oracle中的数据相互导入导出