ArrayBlcokingQueue,LinkedBlockingQueue与Disruptor三种队列对比与分析
Posted 大凡的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ArrayBlcokingQueue,LinkedBlockingQueue与Disruptor三种队列对比与分析相关的知识,希望对你有一定的参考价值。
一、基本介绍
ArrayBlcokingQueue,LinkedBlockingQueue是jdk中内置的阻塞队列,网上对它们的分析已经很多,主要有以下几点:
1、底层实现机制不同,ArrayBlcokingQueue是基于数组的,LinkedBlockingQueue是基于链表的;
2、初始化方式不同,ArrayBlcokingQueue是有界的,初始化时必须指定队列的大小;LinkedBlockingQueue可以是无界的,但如果初始化时指定了队列大小,也可以做为有界队列使用;
3、锁机制实现不同,ArrayBlcokingQueue生产和消费使用的是同一把锁,并没有做锁分离;LinkedBlockingQueue中生产、消费分别通过putLock与takeLock保证同步,进行了锁的分离;
使用的过程中,根据应该场景提供了可选插入和删除策略,我们需要掌握和区分
1、插入操作
//队列未满时,返回true;队列满则抛出IllegalStateException(“Queue full”)异常 add(e);
//队列未满时,直接插入没有返回值;队列满时会阻塞等待,一直等到队列未满时再插入。 put(e); //队列未满时,返回true;队列满时返回false。非阻塞立即返回。 offer(e); //设定等待的时间,如果在指定时间内还不能往队列中插入数据则返回false,插入成功返回true。 offer(e, timeout, unit);
2、删除操作
//队列不为空时,返回队首值并移除;队列为空时抛出NoSuchElementException()异常 remove(); //队列不为空返回队首值并移除;当队列为空时会阻塞等待,一直等到队列不为空时再返回队首值。 queue.take();
//队列不为空时返回队首值并移除;队列为空时返回null。非阻塞立即返回。 queue.poll(); //设定等待的时间,如果在指定时间内队列还未孔则返回null,不为空则返回队首值 queue.poll(timeout, unit)
Disruptor框架是由LMAX公司开发的一款高效的无锁内存队列。
Disruptor的最大特点就是高性能,它的内部与众不同的使用了环形队列(RingBuffer)来代替普通的线型队列,相比普通队列环形队列不需要针对性的同步head和tail头尾指针,减少了线程协作的复杂度,再加上它本身基于无锁操作的特性,从而可以达到了非常高的性能;
在使用Disruptor框架时,我们需要注意以下几个方面
1、Disruptor的构造
/** * * * @param eventFactory 定义的事件工厂 * @param ringBufferSize 环形队列RingBuffer的大小,必须是2的N次方 * @param threadFactory 消费者线程工厂 * @param producerType 生产者线程的设置,当你只有一个生产者线程时设置为 ProducerType.SINGLE,多个生产者线程ProducerType.MULTI * @param waitStrategy 消费者的等待策略 */ public Disruptor( final EventFactory<T> eventFactory, final int ringBufferSize, final ThreadFactory threadFactory, final ProducerType producerType, final WaitStrategy waitStrategy) { this( RingBuffer.create(producerType, eventFactory, ringBufferSize, waitStrategy), new BasicExecutor(threadFactory)); }
上面的消费者等待策略有以下:
BlockingWaitStrategy: 使用锁和条件变量。CPU资源的占用少,延迟大;
SleepingWaitStrategy: 在多次循环尝试不成功后,选择让出CPU,等待下次调度,多次调度后仍不成功,尝试前睡眠一个纳秒级别的时间再尝试。这种策略平衡了延迟和CPU资源占用,但延迟不均匀。
YieldingWaitStrategy: 在多次循环尝试不成功后,通过Thread.yield()让出CPU,等待下次调度。性能和CPU资源占用上较为平衡,但要注意使用该策略时消费者线程最好小于CPU的核心数
BusySpinWaitStrategy: 性能最高的一种,一直不停的自旋等待,获取资源。可以压榨出最高的性能,但会占用最多的CPU资源
PhasedBackoffWaitStrategy: 上面多种策略的综合,CPU资源的占用少,延迟大。
2、handleEventsWith与handleEventsWithWorkerPool的区别
这两个方法区别主要就是在于是否重复消费队列中的消息,前者加载的不同消费者会各自对消息进行消费,各个消费者之间不存在竞争。后者消费者对于队列中的同一条消息不重复消费;
二、性能对比
上面我们对三种阻塞队列做了一个基本的介绍,下面我们分别对它们进行性能上的测试与比对,看下ArrayBlcokingQueue与LinkedBlockingQueue性能上有哪些差别,而Disruptor是否像说的那样具备很高的并发性能
首先我们构造一个加单的消息事件实体
public class InfoEvent implements Serializable { private static final long serialVersionUID = 1L; private long id; private String value; public InfoEvent() { } public InfoEvent(long id, String value) { this.id = id; this.value = value; } public long getId() { return id; } public void setId(long id) { this.id = id; } public String getValue() { return value; } public void setValue(String value) { this.value = value; } }
定义事件工厂
public class InfoEventFactory implements EventFactory<InfoEvent>{ public InfoEvent newInstance() { return new InfoEvent(); } }
定义Disruptor的消费者
public class InfoEventConsumer implements WorkHandler<InfoEvent> { private long startTime; private int cnt; public InfoEventConsumer() { this.startTime = System.currentTimeMillis(); } @Override public void onEvent(InfoEvent event) throws Exception { // TODO Auto-generated method stub cnt++; if (cnt == DisruptorTest.infoNum) { long endTime = System.currentTimeMillis(); System.out.println(" 消耗时间: " + (endTime - startTime) + "毫秒"); } } }
接下来分别针对ArrayBlockingQueue、LinkedBlockingQueue与Disruptor编写测试程序
ArrayBlcokingQueueTest
public class ArrayBlcokingQueueTest { public static int infoNum = 5000000; public static void main(String[] args) { final BlockingQueue<InfoEvent> queue = new ArrayBlockingQueue<InfoEvent>(100); final long startTime = System.currentTimeMillis(); new Thread(new Runnable() { @Override public void run() { int pcnt = 0; while (pcnt < infoNum) { InfoEvent kafkaInfoEvent = new InfoEvent(pcnt, pcnt+"info"); try { queue.put(kafkaInfoEvent); } catch (InterruptedException e) { e.printStackTrace(); } pcnt++; } } }).start(); new Thread(new Runnable() { @Override public void run() { int cnt = 0; while (cnt < infoNum) { try { queue.take(); } catch (InterruptedException e) { e.printStackTrace(); } cnt++; } long endTime = System.currentTimeMillis(); System.out.println("消耗时间 : " + (endTime - startTime) + "毫秒"); } }).start(); } }
LinkedBlockingQueueTest
public class LinkedBlockingQueueTest { public static int infoNum = 50000000; public static void main(String[] args) { final BlockingQueue<InfoEvent> queue = new LinkedBlockingQueue<InfoEvent>(); final long startTime = System.currentTimeMillis(); new Thread(new Runnable() { @Override public void run() { int pcnt = 0; while (pcnt < infoNum) { InfoEvent kafkaInfoEvent = new InfoEvent(pcnt, pcnt + "info"); try { queue.put(kafkaInfoEvent); } catch (InterruptedException e) { e.printStackTrace(); } pcnt++; } } }).start(); new Thread(new Runnable() { @Override public void run() { int cnt = 0; while (cnt < infoNum) { try { queue.take(); } catch (InterruptedException e) { e.printStackTrace(); } cnt++; } long endTime = System.currentTimeMillis(); System.out.println("消耗时间: " + (endTime - startTime) + "毫秒"); } }).start(); } }
DisruptorTest
public class DisruptorTest { public static int infoNum = 5000000; @SuppressWarnings("unchecked") public static void main(String[] args) { InfoEventFactory factory = new InfoEventFactory(); int ringBufferSize = 65536; //数据缓冲区的大小 必须为2的次幂 /** * * factory,定义的事件工厂 * ringBufferSize,环形队列RingBuffer的大小,必须是2的N次方 * ProducerType,生产者线程的设置,当你只有一个生产者线程时设置为 ProducerType.SINGLE,多个生产者线程ProducerType.MULTI * waitStrategy,消费者的等待策略 * */ final Disruptor<InfoEvent> disruptor = new Disruptor<InfoEvent>(factory, ringBufferSize, DaemonThreadFactory.INSTANCE, ProducerType.SINGLE, new YieldingWaitStrategy()); InfoEventConsumer consumer = new InfoEventConsumer(); disruptor.handleEventsWithWorkerPool(consumer); disruptor.start(); new Thread(new Runnable() { @Override public void run() { RingBuffer<InfoEvent> ringBuffer = disruptor.getRingBuffer(); for (int i = 0; i < infoNum; i++) { long seq = ringBuffer.next(); InfoEvent infoEvent = ringBuffer.get(seq); infoEvent.setId(i); infoEvent.setValue("info" + i); ringBuffer.publish(seq); } } }).start(); } }
我们在十万、百万、千万三个数量级上,分别对ArrayBlockingQueue,LinkedBlockingQueue初始化为无界和有界队列,Disruptor的BlockingWaitStrategy和YieldingWaitStrategy,进行三次测试,生产者与消费者均在单线程模式下运行,对结果进行统计记录;
测试环境:
操作系统:win7 64位,CPU:Intel Core i7-3250M 2.9GHz ,内存:8G,JDK:1.8,disruptor版本:3.4.2
五十万数据
|
第一次 |
第二次 |
第三次 |
|
|
ArrayBlcokingQueue |
229ms |
233ms |
253ms |
|
LinkedBlockingQueue(无界) |
211ms |
207ms |
202ms |
|
LinkedBlockingQueue(有界) |
265ms |
207ms |
256ms |
|
Disruptor(BlockingWaitStrategy) |
71ms |
56ms |
65ms |
|
Disruptor(YieldingWaitStrategy) |
56ms |
48ms |
49ms |
五百万数据
|
第一次 |
第二次 |
第三次 |
|
|
ArrayBlcokingQueue |
1530ms |
1603ms |
1576ms |
|
LinkedBlockingQueue(无界) |
1369ms |
1390ms |
1409ms |
|
LinkedBlockingQueue(有界) |
1408ms |
1397ms |
1494ms |
|
Disruptor(BlockingWaitStrategy) |
345ms |
363ms |
357ms |
|
Disruptor(YieldingWaitStrategy) |
104ms |
108ms |
107ms |
五千万数据
|
|
第一次 |
第二次 |
第三次 |
|
ArrayBlcokingQueue |
14799ms |
14928ms |
15122ms |
|
LinkedBlockingQueue(无界) |
14226ms |
14008ms |
13518ms |
|
LinkedBlockingQueue(有界) |
14039ms |
14434ms |
13839ms |
|
Disruptor(BlockingWaitStrategy) |
2972ms |
2910ms |
2848ms |
|
Disruptor(YieldingWaitStrategy) |
699ms |
742ms |
698ms |
然后我对程序进行了修改,让测试程序持续运行,每五千万输出一次,对运行期间CPU和内存使用情况进行了记录
ArrayBlcokingQueue
LinkedBlockingQueue(无界)
LinkedBlockingQueue(有界)
Disruptor(BlockingWaitStrategy)
Disruptor(YieldingWaitStrategy)
从上面的测试中我们可以看到ArrayBlcokingQueue与LinkedBlockingQueue性能上区别不是很大,LinkedBlockingQueue由于读写锁的分离,平均性能会稍微好些,但差距并不明显。
而Disruptor性能表现突出,特别是随着数据量的增大,优势会越发明显。同时在单线程生产和消费的应用场景下,相比jdk内置的阻塞队列,CPU和GC的压力反而更小。
三、总结


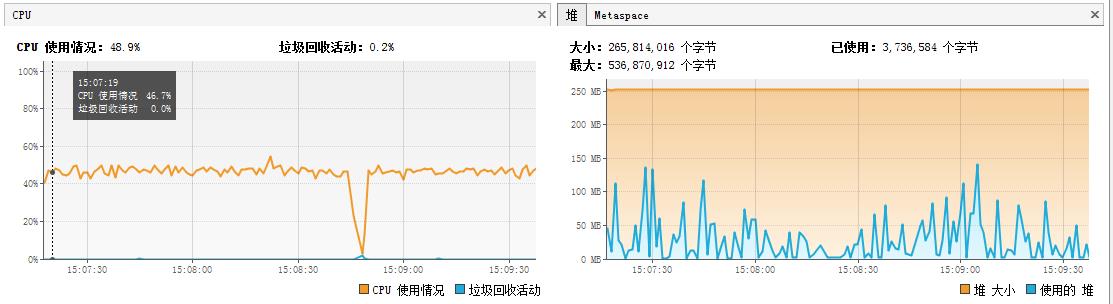

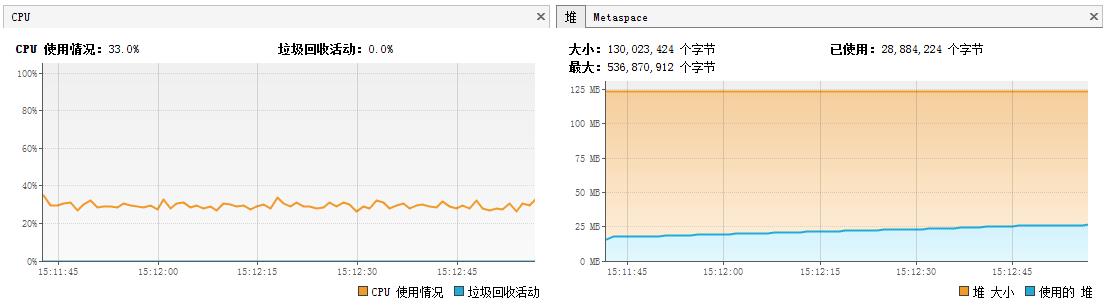
1、ArrayBlcokingQueue与LinkedBlockingQueue,一般认为前者基于数组实现,初始化后不需要再创建新的对象,但没有进行锁分离,所以内存GC压力较小,但性能会相对较低;后者基于链表实现,每次都需要创建 一个node对象,会存在频繁的创建销毁操作,GC压力较大,但插入和删除数据是不同的锁,进行了锁分离,性能会相对较好;从测试结果上看,其实两者性能和GC上差别都不大,在实际运用过程中,我认为一般场景下ArrayBlcokingQueue的性能已经足够应对,处于对GC压力的考虑,及潜在的OOM的风险我建议普通情况下使用ArrayBlcokingQueue即可。当然你也可以使用LinkedBlockingQueue,从测试结果上看,它相比ArrayBlcokingQueue性能上有有所提升但并不明显,结合gc的压力和潜在OOM的风险,所以结合应用的场景需要综合考虑。
2、Disruptor做为一款高性能队列框架,确实足够优秀,在测试中我们可以看到无论是性能和GC压力都远远好过ArrayBlcokingQueue与LinkedBlockingQueue;如果你追求更高的性能,那么Disruptor是一个很好的选择。
但需要注意的是,你需要结合自己的硬件配置和业务场景,正确配置Disruptor,选择合适的消费策略,这样不仅可以获取较高的性能,同时可以保证硬件资源的合理分配。
3、对这三种阻塞队列的测试,并不是为了比较孰优孰劣,主要是为了加强理解,实际的业务应用需要根据情况合理进行选择。这里只是结合自己的使用,对它们进行一个简单的总结,并没有进行较深入的探究,如有错误的的地方还请指正与海涵。
关注微信公众号,查看更多技术文章。

以上是关于ArrayBlcokingQueue,LinkedBlockingQueue与Disruptor三种队列对比与分析的主要内容,如果未能解决你的问题,请参考以下文章