大数据(MapReduce的编程细节及其Hive的安装,简单操作)
Posted DaDa~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据(MapReduce的编程细节及其Hive的安装,简单操作)相关的知识,希望对你有一定的参考价值。
MapReduce编程细节分析
-
MapReduce中,Reduce可以没有 (纯数据的清洗,不用Reduce)
job.setNumReduceTasks(0); -
设置多个Reduce
// 默认在MapReduce中 Reduce的数量是1
job.setNumReduceTasks(3);
//为什么Reduce的数量可以设置为多个
内存角度 并行角度
//如果Reduce数量多个话,那么生成结果也是多个独立的文件,放置在同一个目录下 -
Partition 分区
分区的作用: Map 输出的key,合理分配对应的Reduce进行处理
默认的分区策略:key%reduceNum = public class HashPartitioner<K, V> extends Partitioner<K, V> { public HashPartitioner() { } public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode() & 2147483647) % numReduceTasks; } } 自定义分区策略 public class MyPartitioner<K,V> extends Partitioner<K,V>{ } job.setPartitionerClass(MyPartitioner.class);
-
Map的压缩
1. core-site.xml
2. mapred-site.xml

-
Combainer编程
Map端的Reduce
job.setCombinerClass(MyReduce3.class); -
Counter计数器
Counter counter = context.getCounter("lhcCounter", "mapCount");
counter.increment(1L);
Hive编程
概念: Hive是apache组织开源的一个数据仓库框架,最开始是FaceBook提供的.
1. 数据仓库
数据库 DataBase
存储的数据量级 小 价值高
数据仓库 DataWareHouse
存储的数据量级 大 价值低
2. Hive底层依附的是Hadoop
3. 以类SQL(HQL Hive Query Languge) 的方式运行MR,操作HDFS上的数据
-
Hive的原理分析
Hive Hadoop on SQL
SparkQL Spark on SQL
Presto Impala kylin 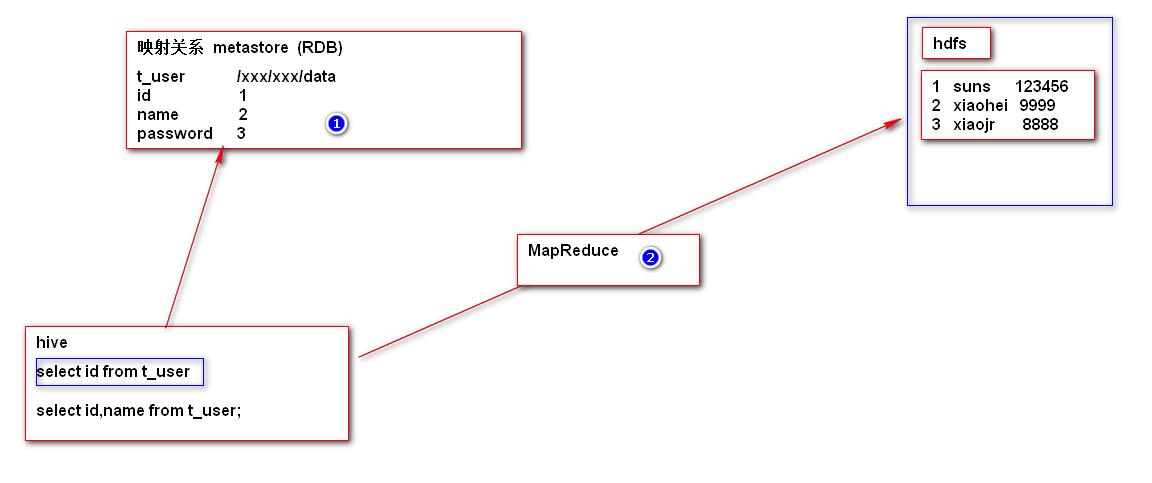
-
Hive基本环境的搭建
1. 搭建Hadoop 2. Hive安装 加压缩 3. 配置 hive-env.sh # Set HADOOP_HOME to point to a specific hadoop install directory HADOOP_HOME=/opt/install/hadoop-2.5.2 # Hive Configuration Directory can be controlled by: export HIVE_CONF_DIR=/opt/install/apache-hive-0.13.1-bin/conf 4. 在hdfs 创建 /tmp 数据库表对应的路径 /user/hive/warehouse 5. 启动hive
bin/hive -
Hive的基本使用
1. hive数据库 show databases; create database if not exists lhc_140 use lhc_140 2. 表相关操作 show tables; create table if not exists t_user( id int, name string )row format delimited fields terminated by \'\\t\'; 3. 插入数据 导入数据 本地操作系统文件 向 hive表 导入数据 load data local inpath \'/root/data3\' into table t_user; 4. SQL语句 select * from t_user;
-
Hive与HDFS对应的一个介绍
1. 数据库对应的就是一个HDFS目录 lhc141 /user/hive/warehouse/mydb 2. 表对应一个HDFS目录 /user/hive/warehouse/mydb/t_user 3. 表中的数据 对应的是 HDFS上的文件 load data local inpath \'/root/data3\' into table t_user; bin/hdfs dfs -put /root/data3 /user/hive/warehouse/mydb/t_user
以上是关于大数据(MapReduce的编程细节及其Hive的安装,简单操作)的主要内容,如果未能解决你的问题,请参考以下文章