大数据(hdfs集群及其集群的高级管理)
Posted lhc-hhh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据(hdfs集群及其集群的高级管理)相关的知识,希望对你有一定的参考价值。
大数据课程第二天
伪分布式hadoop的启动停止脚本[使用]
sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanager ? shell脚本 xxx.sh ls mkdir hadoop-start.sh sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanager ? chmod 744 hadoop-start.sh
?
1. 相对路径
./hadoop-start.sh
2. 绝对路径
/opt/install/hadoop-2.5.2/hadoop-stop.shHDFS的集群
-
HDFS配置集群的原理分析
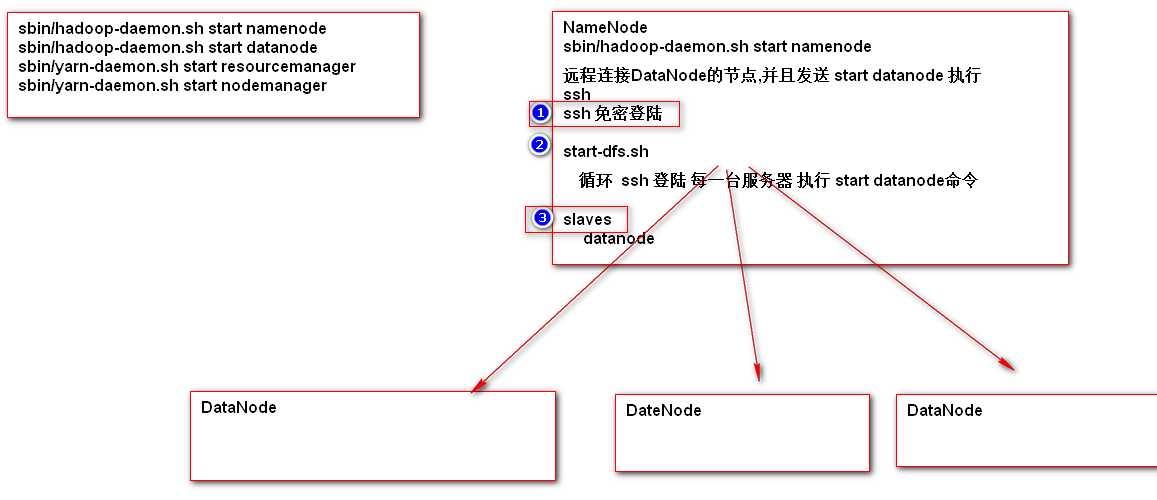
-
ssh免密登陆
-
通过工具生成公私钥对
ssh-keygen -t rsa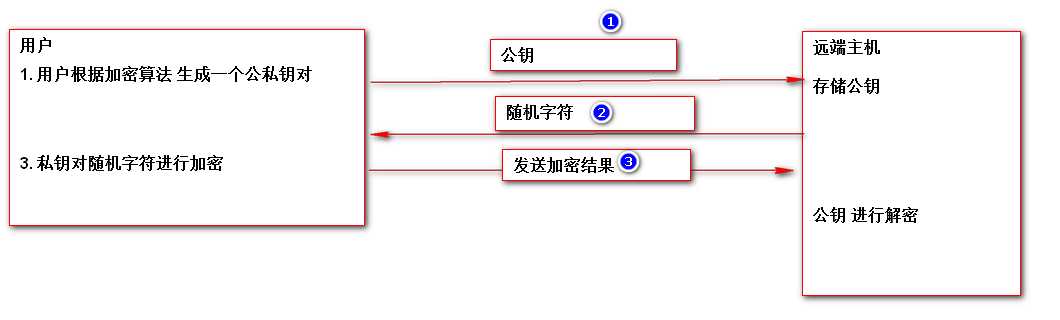
-
公钥发送远程主机
ssh-copy-id 用户@ip
-
-
修改slave文件
vi /opt/install/hadoop2.5.2/etc/hadoop/slaves
?
slavesip -
HDFS的集群搭建
-
ssh免密登陆
ssh-keygen -t rsa
ssh-copy-id 用户@ip -
清除mac地址的影响
rm -rf /etc/udev/rule.d/70-persistence.net.rules -
设置网络
1. ip地址设置 主机名 映射 关闭防火墙 关闭selinux -
安装hadoop,jdk
1. 安装jdk 2. hadoop解压缩 3. 配置文件 hadoop-env.sh core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml slaves 一致 4. 格式化 NameNode所在的节点 格式化 [清空原有 data/tmp 内容] bin/hdfs namenode -format 5. 启动相关服务 sbin/start-dfs.sh 出现如下则成功:(从节点连接不成功可以先手动ssh连一下,确保可以无密码无验证才可进行以下) [[email protected] hadoop-2.5.2]# sbin/start-dfs.sh 19/01/23 04:09:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [hadoop] hadoop: starting namenode, logging to /opt/install/hadoop-2.5.2/logs/hadoop-root-namenode-hadoop.out hadoop2: starting datanode, logging to /opt/install/hadoop-2.5.2/logs/hadoop-root-datanode-hadoop2.out hadoop: starting datanode, logging to /opt/install/hadoop-2.5.2/logs/hadoop-root-datanode-hadoop.out hadoop1: starting datanode, logging to /opt/install/hadoop-2.5.2/logs/hadoop-root-datanode-hadoop1.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /opt/install/hadoop-2.5.2/logs/hadoop-root-secondarynamenode-hadoop.out 19/01/23 04:10:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 6.运行jps [[email protected] hadoop-2.5.2]# jps 3034 DataNode 3178 SecondaryNameNode 3311 Jps 2946 NameNode 2824 GetConf 7.在从节点运行jps,出现如下则正常 [[email protected] etc]# jps 1782 Jps 1715 DataNode 访问hadoop:50070查看datanode:
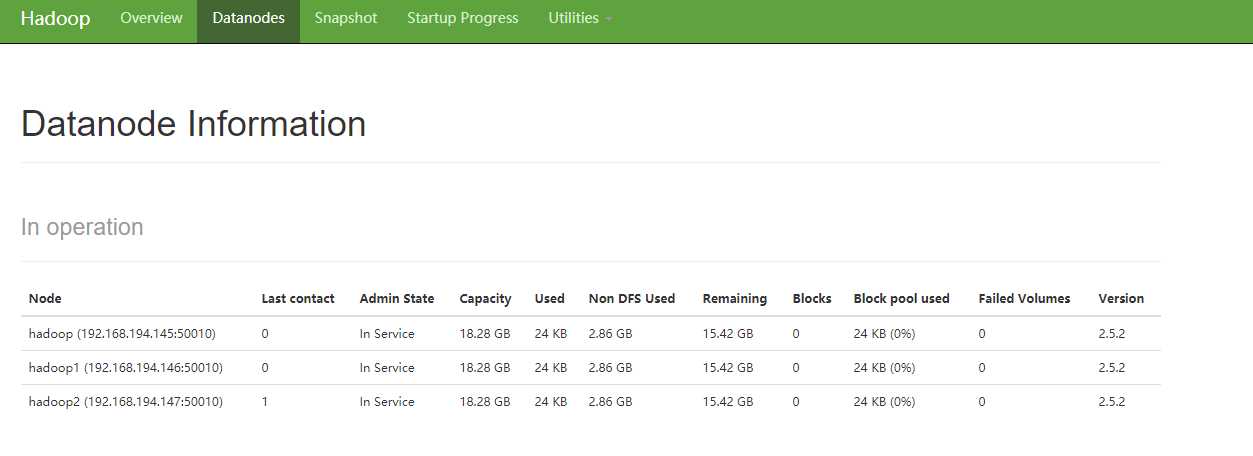
-
HDFS高级管理内容
-
NameNode持久化[了解]
-
什么是NameNode的持久化
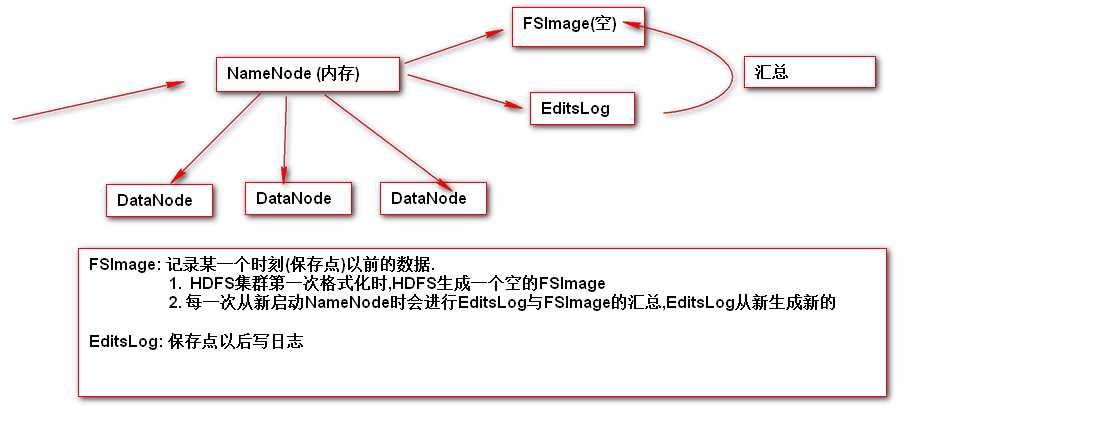
-
FSImage和EditsLog文件默认存储的位置
#默认存储位置: /opt/install/hadoop-2.5.2/data/tmp/dfs/name
hadoop.tmp.dir=/opt/install/hadoop-2.5.2/data/tmp
dfs.namenode.name.dir=file://${hadoop.tmp.dir}/dfs/name
dfs.namenode.edits.dir = ${dfs.namenode.name.dir} -
自定义FSImage和EditsLog的存储位置?
hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/xxx/xxx</value>
</property>
?
<property>
<name>dfs.namenode.edits.dir</name>
<value>/xxx/xxx<</value>
</property> -
安全模式 safemode
每一次从新启动NameNode时,都会进行EditsLog与FSImage的汇总,为了避免这个过程中,用户写操作会对系统造成影响,HDFS设置了安全模式(safemode),在安全模式中,不允许用户做写操作.完成合并后,安全模式会自动退出
手工干预安全模式
bin/hdfs dfsadmin -safemode enter|leave|get
-
-
SecondaryNameNode
-
定期合并FSImage和EditsLog
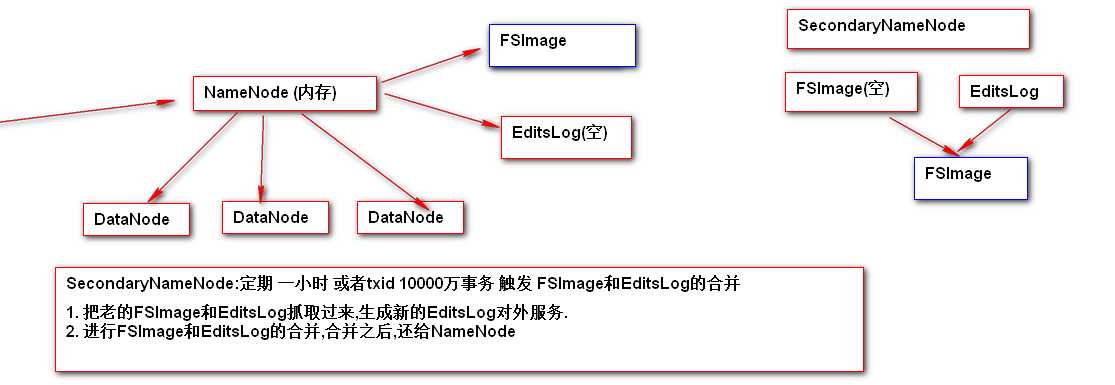
-
可以在NameNode进程宕机,FSImage和EditsLog硬盘损坏的情况下,部分还原NameNode数据
-
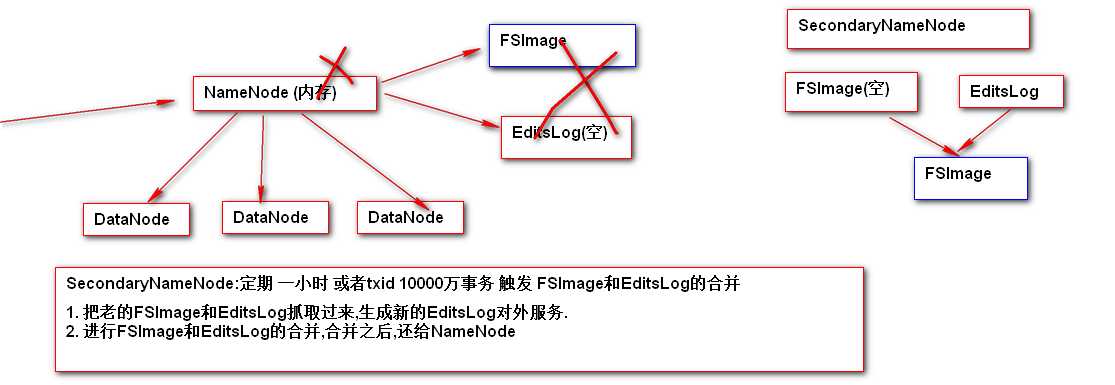
SecondaryNameNode获取的FSImage和EditsLog 存储位置 /opt/install/hadoop2.5.2/data/tmp/dfs/namesecondary #secondarynamenode还原namenode数据的方式 #rm -rf /opt/install/hadoop2.5.2/data/tmp/dfs/namesecondary/in_use.lock 1. 指定namenode持久化中FSImage 和 EditsLog的新位置 hdfs-site.xml <property> <name>dfs.namenode.name.dir</name> <value>file:///opt/install/nn/fs</value> </property> <property> <name>dfs.namenode.edits.dir</name> <value>file:///opt/install/nn/edits</value> </property> 2. kill namenode 目的为了演示 namenode 当机 日志查看/logs/hadoop-root-namenode-hadoop.log tail -100 查看最新的100行 3. 通过SecondaryNameNode恢复NameNode sbin/hadoop-daemon.sh start namenode -importCheckpoint 如果namenode没启动,查看查看hadoop2.5/data/tmp/dfs/namesecondary目录是否被锁,如果锁掉则删掉该目录下的in_use.lock
以上是关于大数据(hdfs集群及其集群的高级管理)的主要内容,如果未能解决你的问题,请参考以下文章