T-SQL查询2
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了T-SQL查询2相关的知识,希望对你有一定的参考价值。
? 嵌套子查询
子查询是一个嵌套在select、insert、update或delete语句或其他子查询中的查询。任何允许使用表达式的地方都可以使用子查询。子查询也称为内部查询或内部选择,而包含子查询的语句也成为外部查询或外部选择。
# from (select … table)示例
将一个table的查询结果当做一个新表进行查询
select * from (
select id, name from student where sex = 1
) t where t.id > 2;
上面括号中的语句,就是子查询语句(内部查询)。在外面的是外部查询,其中外部查询可以包含以下语句:
1、 包含常规选择列表组件的常规select查询
2、 包含一个或多个表或视图名称的常规from语句
3、 可选的where子句
4、 可选的group by子句
5、 可选的having子句
# 示例
查询班级信息,统计班级学生人生
select *, (select count(*) from student where cid = classes.id) as num
from classes order by num;
# in, not in子句查询示例
查询班级id大于小于的这些班级的学生信息
select * from student where cid in (
select id from classes where id > 2 and id < 4
);
查询不是班的学生信息
select * from student where cid not in (
select id from classes where name = ‘2班‘
)
in、not in 后面的子句返回的结果必须是一列,这一列的结果将会作为查询条件对应前面的条件。如cid对应子句的id;
# exists和not exists子句查询示例
查询存在班级id为的学生信息
select * from student where exists (
select * from classes where id = student.cid and id = 3
);
查询没有分配班级的学生信息
select * from student where not exists (
select * from classes where id = student.cid
);
exists和not exists查询需要内部查询和外部查询进行一个关联的条件,如果没有这个条件将是查询到的所有信息。如:id等于student.id;
# some、any、all子句查询示例
-- t1表数据 2,3 -- t2表数据 1,2,3,4 -- ‘>all‘ 表示:t2表中列n的数据大于t1表中列n的数据的数,结果只有4. select * from t2 where n > all(select n from t1 ) --4 select * from t2 where n > any(select n from t1 ) --3,4 select * from t2 where n > some(selectn from t1) --3,4 select * from t2 where n = all(select n from t1 ) --无数据 select * from t2 where n = any(select n from t1 ) --2,3 select * from t2 where n = some(selectn from t1) --2,3 select * from t2 where n < all(select n from t1 ) --1 select * from t2 where n < any(select n from t1 ) --1,2 select * from t2 where n < some(selectn from t1) --1,2 select * from t2 where n <>all (select n from t1 ) --1,4 select * from t2 where n <>any (select n from t1 ) --1,2,3,4 select * from t2 where n <>some(select n from t1) --1,2,3,4
? 聚合查询
1、 distinct去掉重复数据
select distinct sex from student;
select count(sex), count(distinct sex) from student;
2、 compute和compute by汇总查询
这里过于复杂,参考http://www.cnblogs.com/waitingfor/articles/2220698.html
3、 cube汇总
cube汇总和compute效果类似,但语法较简洁,而且返回的是一个结果集。
select count(*), sex from student group by sex with cube;
select count(*), age, sum(age) from student where age is not null group by age with cube;
cube要结合group by语句完成分组汇总
CUBE运算符生成的结果集是多维数据集,多维数据集是事实数据的扩展,事实数据即记录个别时间的数据,扩展建立在用户准备分析的列上,这些列被称为维,多维数据集是一个结果集,其中包含各纬度所有可能的交叉表格.
CUBE运算符是在Select语句的group by子句中指定的,group by应指定维度列和关键字with cube,结果集将包括维度列中各值的所有可能组合.
示例1.
Sql语句如下:
select * from student
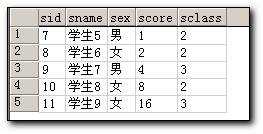
select sex,sclass,sum(score) as 合计
from student
group by sex,sclass with cube
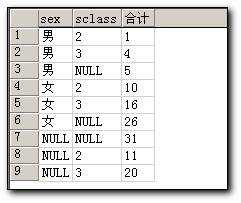
select sex,sclass,sum(score) as 合计
from student
group by sclass,sex with cube
Sql查询时这样运行:
1. 查询到性别的第一个性别为男,则先查询男生,然后分班级
2. 查询完成之后,对性别为Sex为男的数据进行合计
3. 查询性别为女的数据,查询完成之后同样也进行合计
4. 不分性别、班级进行合计汇总
5. 以上均是以性别为组来分类,因为至此时关于性别的所有汇总都已经完成
6. 按照sclass进行分组汇总.
注意:
1. 分类依据并不是根据select 中的顺序,而是根据group by中的顺序.
2. 尽量按照使select和group by中的字段顺序一致,这样在显示起来看着更舒服,具体情况具体分析.
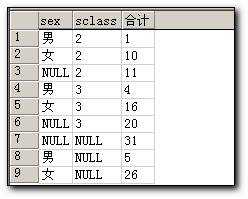
对于上述查询的结果,我们可以看出,数据中存在空置问题,绑定到GridView后显示如下:
此中效果并没有达到能够满足实际项目中的需要,所以,我们对Sql语句应进行改进.
使用Grouping区分空值.
如何区分使用CUBE之后产生的空值和实际查询中得到的空值.这个问题可以用grouping函数来解决.如果列中的值来来自查询数据,则grouping返回0,如果列中的值是cube产生的空值,则返回1
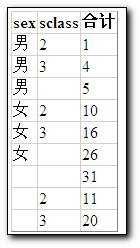
示例2.
Sql如下:
select case when(grouping(sex)=1) then ‘小记‘ else sex
end as 性别,
case when(grouping(sclass)=1) then ‘小记‘ else sclass
end as 班级,
sum(score)
from student
group by sex,sclass with cube
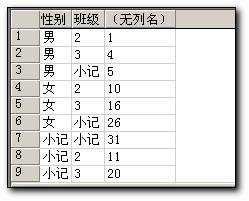
在页面上显示时如下:
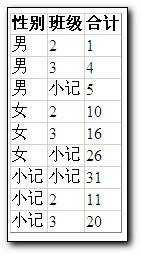
CUBE可以生成n维的多维数据集,即具有任意维目的多维数据集,只有一个维度的多维数据集可用于生成合计.
示例3:
SQL:
select case when(grouping(sex)=1) then ‘合计‘ else sex end as 性别,
sum(score) as 合计
from student
group by sex with cube
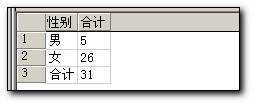
生成许多维度的数据集合结果可能很大,办法就是生成一个大的视图,选择显示即可.
以上是关于T-SQL查询2的主要内容,如果未能解决你的问题,请参考以下文章