Percona Toolkit mysql辅助利器
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Percona Toolkit mysql辅助利器相关的知识,希望对你有一定的参考价值。
1 PT介绍
Percona Toolkit简称pt工具—PT-Tools,是Percona公司开发用于管理mysql的工具,功能包括检查主从复制的数据一致性、检查重复索引、定位IO占用高的表文件、在线DDL等,DBA熟悉掌握后将极大提高工作效率。
2 PT 安装
下载地址 :https://www.percona.com/downloads/percona-toolkit/
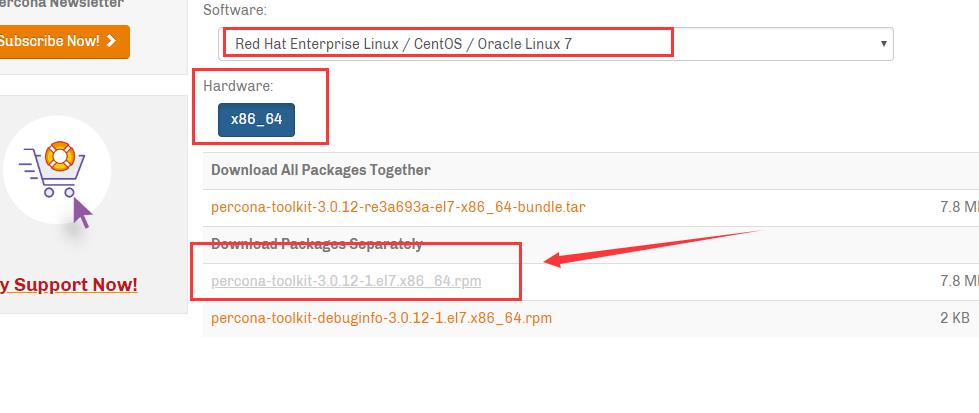
下载完上传到linux 服务器
安装PT
[root@master01 ~]# yum -y install percona-toolkit-3.0.12-1.el7.x86_64.rpm
创建一个表生成10000000 条测试数据
创建一个用户表:
create table uc_user ( user_id int NOT NULL auto_increment primary key , user_name varchar(32) , create_time datetime )
随机生成10000000 条测试数据
#创建存储过程
delimiter //
create procedure user_data()
begin
declare i int default 1;
set i = 1;
while i<=10000000 do
-- rymd 表示随机年月日
set @rymd = CONCAT(FLOOR(1990 + (RAND() * 28)),\'-\',LPAD(FLOOR(1 + (RAND() * 12)),2,0),\'-\',LPAD(FLOOR(3 + (RAND() * 8)),2,0));
-- rhms 表示随机分钟小时秒
set @rhms = CONCAT(LPAD(FLOOR(0 + (RAND() * 23)),2,0),\':\',LPAD(FLOOR(0 + (RAND() * 59)),2,0),\':\',LPAD(FLOOR(0 + (RAND() * 59)),2,0));
-- rstring 生成4位随机字符串
set @rstring = substring(MD5(RAND()),1,4);
insert into uc_user values (i,@rstring,concat(@rymd,\' \',@rhms));
set i=i+1;
end while;
end //
delimiter ;
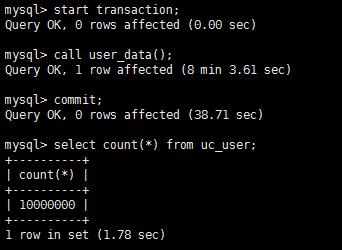
生成10000000 条测试数据
#开启一个事务 mysql> start transaction; #调用存储过程 mysql> call user_data(); #结束事务,提交到硬盘 mysql> commit;
我的mysql 版本是5.7.22
3 PT 常用的几个工具
3.1 pt-archiver
pt-archive 是MySQL的在线归档,无影响生产数据
为什么要归档:
若干年前的数据则很少再被使用.归档的意思就是将某些不常使用的数据 放置到其他地方.
归档前提条件:
pt-archive: —归档 用此操作的表必须有主键。一般的表设计的都会有主键的。
-
归档历史数据;
-
在线删除大批量数据;
-
数据导出和备份;
-
数据远程归档
-
数据清理
pt-archiver –help
pt-archiver 有很多参数,用这可以help一下
常用的一些选项说明:
--limit=1000 每次去1000行数据用pt-archiver处理 --txn-size 1000 设置1000行,为一个事务提交一次 --where \'id<3000\' 设置操作条件, id表示表的column --progress 5000 每处理5000行输出一次处理信息 --statistics 输出执行过程及最后的操作统计。(只要不加上--quiet,默认情况下pt-archiver都会输出执行过程的) --charset=UTF8 指定字符集为UTF8 -- 这个最后加上不然可能出现乱码 --bulk-delete 批量删除source 上的旧数据(例如每次1000行的批量删除操作) 选项很多很多 ,不会的多看help
注: 我这用的都是root 用户, 在实际环境 最好建立相应的用户赋予相应的权限进行归档。
3.1.1 用法示例
(1). 将uc_user表中create_time字段大于2017-01-01 00:00:00时间的数据进行归档,不删除原表记录
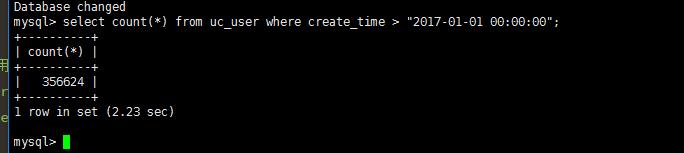
先看看大于create_time 大于2017-01-01 00:00:00 时间有多少数据
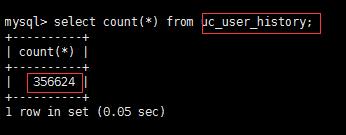
mysql> select count(*) from uc_user where create_time > "2017-01-01 00:00:00"; +----------+ | count(*) | +----------+ | 356624 | +----------+ 1 row in set (2.23 sec)
语法如下:
pt-archiver \\ --source h=源ip,P=端口号,u=用户,p=密码,D=库名,t=表名 \\ --dest h=目标ip,P=端口号,u=用户,p=密码,D=库名,t=表名 \\ --no-check-charset --where \'create_time>"2017-01-01 00:00:00"\' \\ --progress 5000 --no-delete --limit=10000 –statistics
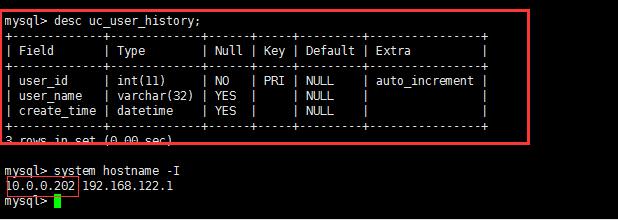
源服务器的表结构和目标服务器的表结构如下:
注:它们之间没有主从关系,只是单纯的两台数据库实例:
| 源服务器 ip | 归档服务器ip |
| 10.0.0.201 | 10.0.0.202 |
原服务器的表结构:
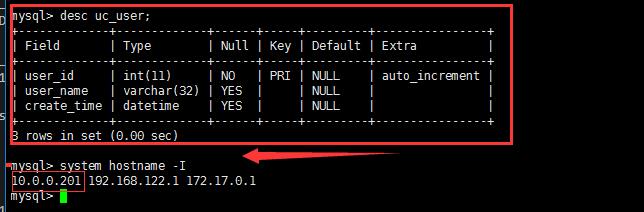
归档服务器的表结构
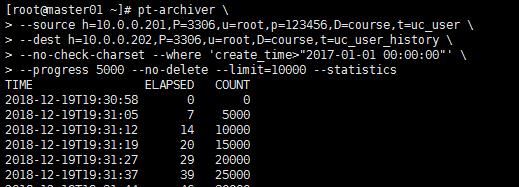
归档语句如下:
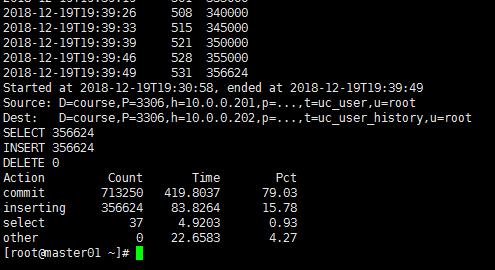
[root@master01 ~]# pt-archiver \\ --source h=10.0.0.201,P=3306,u=root,p=123456,D=course,t=uc_user \\ --dest h=10.0.0.202,P=3306,u=root,D=course,t=uc_user_history \\ --no-check-charset --where \'create_time>"2017-01-01 00:00:00"\' \\ --progress 5000 --no-delete --limit=10000 --statistics
归档完成,看看归档的服务器数据是否有356624条
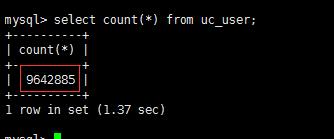
(2).将表中CREATE_DATE字段小于1991-01-01 00:00:00时间的数据进行归档, 删除原表记录(不用加no-delete)
看看小于1991-01-01 00:00:00 有多少条数据,在进行归档

归档删除原表记录
[root@master01 ~]# pt-archiver \\ --source h=10.0.0.201,P=3306,u=root,p=123456,D=course,t=uc_user \\ --dest h=10.0.0.202,P=3306,u=root,p=123456,D=course,t=uc_user_history \\ --no-check-charset --where \'create_time < "1991-01-01 00:00:00"\' \\ --progress 5000 --limit=10000 --statistics
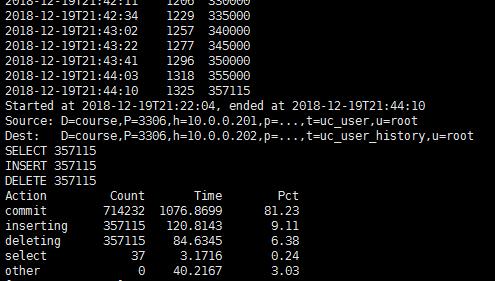
看看原表的数据少了,少了357115
(3).归档时加上字符集 --charset
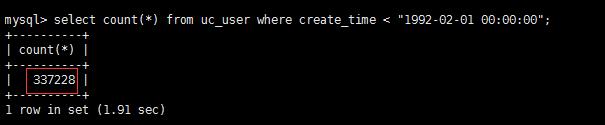
[root@master01 ~]# pt-archiver \\ --charset \'utf8\' \\ --source h=10.0.0.201,P=3306,u=root,p=123456,D=course,t=uc_user \\ --dest h=10.0.0.202,P=3306,u=root,p=123456,D=course,t=uc_user_history \\ --no-check-charset --where \'create_time < "1992-02-01 00:00:00"\' \\ --progress 5000 --limit=10000 --statistics
一般归档的最好还是指定好原表字符集和归档数据的字符集一致。
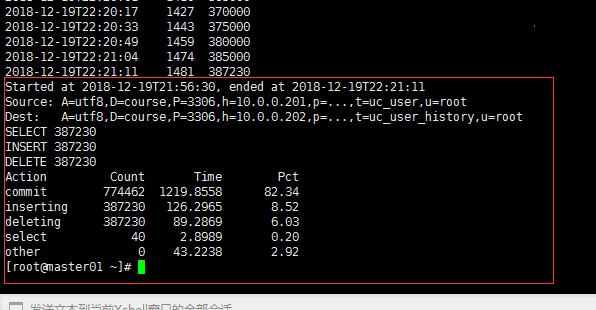
归档途中就会显示如下:
每个Limit 执行的时间,pt-arvhive的开始时间及结束时间 ,源服务器,目标服务器。最后操作的insert ,delete, commit 的数量
3.2 pt-kill
pt-kill 是一个优秀的kill MySQL连接的一个工具,是percona toolkit的一部分,这个工具可以kill掉你想Kill的任何语句,特别出现大量的阻塞,死锁,某个有问题的sql导致mysql负载很高黑客攻击。当有很多语句时你不可能用show processlist去查看,当QPS很高时,你根本找不到你找的语句或ID,这时就可以用pt-kill来帮你帮完成。他可以根据运行时间,开源IP,用户名,数据库名。SQL语句,sleep,running 等状态进行匹配然后kill. 能匹配的太多了一一举例肯定不现实,拿几个案例看看。。可以用pt-kill –help 进行查看帮助
pt-kill 一些常用参数
--daemonize 放在后台以守护进程的形式运行; --interval 多久运行一次,单位可以是s,m,h,d等默认是s ,不加这个默认是5秒 --victims 默认是oldest,只杀最古老的查询。这是防止被查杀是不是真的长时间运行的查询,他们只是长期等待 这种种匹配按时间查询,杀死一个时间最高值。 --all 杀掉所有满足的线程 --kill-query 只杀掉连接执行的语句,但是线程不会被终止 --print 打印满足条件的语句 --busy-time 批次查询已运行的时间超过这个时间的线程; --idle-time 杀掉sleep 空闲了多少时间的连接线程,必须在 --match-command sleep时才有效—也就是匹配使用 --match-command 匹配相关的语句。 --ignore-command 忽略相关的匹配。 这两个搭配使用一定是ignore-commandd在前 match-command在后, --match-db cdelzone 匹配哪个库 command有:Query、Sleep、Binlog Dump、Connect、Delayed insert、Execute、Fetch、Init DB、Kill、Prepare、Processlist、Quit、Reset stmt、Table Dump
3.2.1 pt-kill 举例
例如如下例子
-
杀掉空闲链接sleep 5秒的 SQL 并把日志放到/home/pt-kill.log文件中
[root@master01 ~]# /usr/bin/pt-kill \\ --match-command Sleep \\ --idle-time 5 \\ --victim all \\ --interval 5 \\ --kill --daemonize -S /tmp/mysql.sock \\ --user=root --password=123456 --port=3306 \\ --pid=/tmp/ptkill.pid --print --log=/home/pt-kill.log &
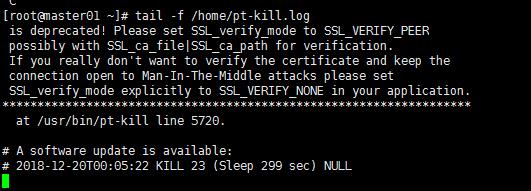
我这没什么Sleep 所以没什么日志输出

2. KILL 掉 查询SELECT 超过20秒的语句
[root@master01 ~]# /usr/bin/pt-kill --user=root --password=123456 --port=3306 \\ --busy-time 20 --match-info "SELECT|select" \\ --victim all --interval 5 \\ --kill --daemonize -S /tmp/mysql.sock --pid=/tmp/ptkill.pid --print --log=/home/pt-kill.log &
注: 一定要看服务这个后台服务启动没有 ,上面pt-kill 进程的pid 也是放在/tmp/ptkill.pid,所以一定的上面的那个进程给kill 掉, 然后开启新的进程
模拟测试超过查询20s

超过了20s pt-kill 设置的规则 ,会终止这个select ,看下日志如下:

3. Kill掉 select ifnull*语句开头的SQL,
[root@master01 ~]# ps aux | grep pt-kill | grep -v grep | awk -F\' \' \'{print $2}\' | xargs kill -9
[root@master01 ~]# pt-kill --user=root --password=123456 --port=3306 \\
--victims all --busy-time=0 --match-info="select ifnull*" \\
--interval 1 -S /tmp/mysql.sock \\
--kill --daemonize --pid=/tmp/ptkill.pid --print --log=/home/pt-kill123.log &

4. kill掉state Locked
[root@master01 ~]# ps aux | grep pt-kill | grep -v grep | awk -F\' \' \'{print $2}\' | xargs kill -9
[root@master01 ~]# /usr/bin/pt-kill --user=root --password=123456 --port=3306 \\
--victims all --match-state=\'Locked\' --victim all --interval 5 \\
--kill --daemonize -S /tmp/mysql.sock --pid=/tmp/ptkill.pid --print --log=/home/pt-kill-Locked.log &
5. kill掉 qz_business_server 库,web为110.59.2.37的链接
pt-kill --user=root --password=123456 --port=3306 \\ --victims all --match-db=\'qz_business_service\' \\ --match-host=\'10.59.2.37\' --kill --daemonize \\ --interval 10 -S /tmp/mysql.sock \\ --pid=/tmp/ptkill.pid --print --log=/home/pt-kill.log &
6. 指定哪个用户kill
pt-kill --user=root --password=123456 --port=3306 \\ --victims all --match-user=\'root\' --kill --daemonize --interval 10 -S /tmp/mysql.sock \\ --pid=/tmp/ptkill.pid --print --log=/home/pt-kill.log &
7. kill掉 command query | Execute
/usr/bin/pt-kill --user=root --password=123456 --port=3306 \\ --victims all --match-command= "query|Execute" --interval 5 \\ --kill --daemonize -S /tmp/mysql.sock \\ --pid=/tmp/ptkill.pid --print --log=/home/pt-kill.log &
3.2.2 pt-kill 使用注意事项
每台主服务器部署pt-kill进程后台跑着。根据业务情况设置间隔时间,多久检测一次(建议只设置SELECT )update 、DELETE不建议。
pt-kill --log-dsn D=dba,t=killed_sql_table \\ --create-log-table --host=127.0.0.1 --user=root --password=\'密码\' --port=6006 \\ --busy-time=300 --print --kill-query --ignore-info "into|INTO|update|UPDATE|delete|DELETE" \\ --match-info "SELECT|select" --victims all &
上面的语句会把大于5分钟的SELECT 语句insert 到本机的dba库里的killed_sql_table表里。注意:区分大小写的。
记录到本机是因为kill 到哪些语句,记录下来,方便好查询。
3.4 pt-online-schema-change
3.4.1 pt-osc 介绍
业界简称 pt-osc 在线更改表结构
MySQL 大字段的DDL操作:加减字段、索引、修改字段属性等,在5.1之前都是非常耗时耗力的,特别是会对MySQL服务产生影响。在5.1之后随着Plugin Innodb的出现在线加索引的提高了很多,但是还会影响(时间缩短了),主要是出现了MDL锁(MySQL为了保护数据字典元数据,使用了metadata lock)。不过5.6可以避免上面的情况,但目前大部分在用的版本都是5.6之前的,所以DDL操作一直是数据库管理人员“头疼”的事。那如何在不锁表的情况下安全快速地更新表结构?
pt-osc模仿MySQL内部的改表方式进行改表,但整个改表过程是通过对原始表的拷贝来完成的,即在改表过程中原始表不会被锁定,并不影响对该表的读写操作。
首先,osc创建与原始表相同的不包含数据的新表(下划线开头)并按照需求进行表结构的修改,然后将原始表中的数据按逐步拷贝到新表中,当拷贝完成后,会自动同时修改原始表和新表的名字并默认将原始表删除
有两个注意点:被操作的表如果有 触发器,或外键用不了。要特别注意(标准规范MySQL是不建议用外键与触发器的)如果有,要把外键与触发器去掉再操作
注:1. 虽然有工具可以修改,但是修改的时候最好是在业务低峰期进行操作
2 还需了解官方的online-ddl ,做好安全措施,哪些可以改都要了解清楚 https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl.html
3.4.2 pt-osc 简单使用说明
pt-online-schema-change —-
在线DDL操作,对上亿的大表加索引加字段且对生产无影响
主要工作原理:
1.创建一个和要执行 alter 操作的表一样的新的空表结构(是alter之前的结构)
2.在新表执行alter table 语句(速度应该很快)
3.在原表中创建触发器3个触发器分别对应insert,update,delete操作
4.以一定块大小从原表拷贝数据到临时表,拷贝过程中通过原表上的触发器在原表进行的写操作都会更新到新建的临时表
5.Rename 原表到old表中,在把临时表Rename为原表
6.如果有参考该表的外键,根据alter-foreign-keys-method参数的值,检测外键相关的表,做相应设置的处理
7. 默认最后将旧原表删除
如果执行失败了,或手动停止了,需要手动删除下划线开头的表(_表名)及三个触发器
主要几个参数: --max-load
默认为Threads_running=25。每个chunk拷贝完后,会检查SHOW GLOBAL STATUS的内容,检查指标是否超过了指定的阈值。如果超过,则先暂停。这里可以用逗号分隔,指定多个条件,每个条件格式: status指标=MAX_VALUE或者status指标:MAX_VALUE。如果不指定MAX_VALUE,那么工具会这只其为当前值的120%。
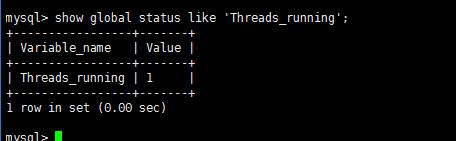
--critical-load 默认为Threads_running=50。用法基本与–max-load类似,如果不指定MAX_VALUE,那么工具会这只其为当前值的200%。如果超过指定值,则工具直接退出,而不是暂停。
--user: -u,连接的用户名 --password: -p,连接的密码 --database: -D,连接的数据库 --port -P,连接数据库的端口 --host: -h,连接的主机地址 --socket: -S,连接mysql套接字文件 --statistics 打印出内部事件的数目,可以看到复制数据插入的数目。 --dry-run 创建和修改新表,但不会创建触发器、复制数据、和替换原表。并不真正执行,可以看到生成的执行语句,了解其执行步骤与细节。--dry-run与--execute必须指定一个,二者相互排斥。和--print配合最佳。 --execute 确定修改表,则指定该参数。真正执行。--dry-run与--execute必须指定一个,二者相互排斥。 --print 打印SQL语句到标准输出。指定此选项可以让你看到该工具所执行的语句,和--dry-run配合最佳。 --progress 复制数据的时候打印进度报告,二部分组成:第一部分是百分比,第二部分是时间。 --quiet -q,不把信息标准输出。
3.4.3 pt-osc 案例
1 . 添加索引的案例
对t=uc_user ,对uc_user表的user_name 列添加索引,索引名为index_uname。
pt-online-schema-change \\ --user=root --password=\'123456\' --port=3306 --host=127.0.0.1 --critical-load Threads_running=100 \\ --alter "ADD INDEX index_uname (user_name)" D=course,t=uc_user --print --execute
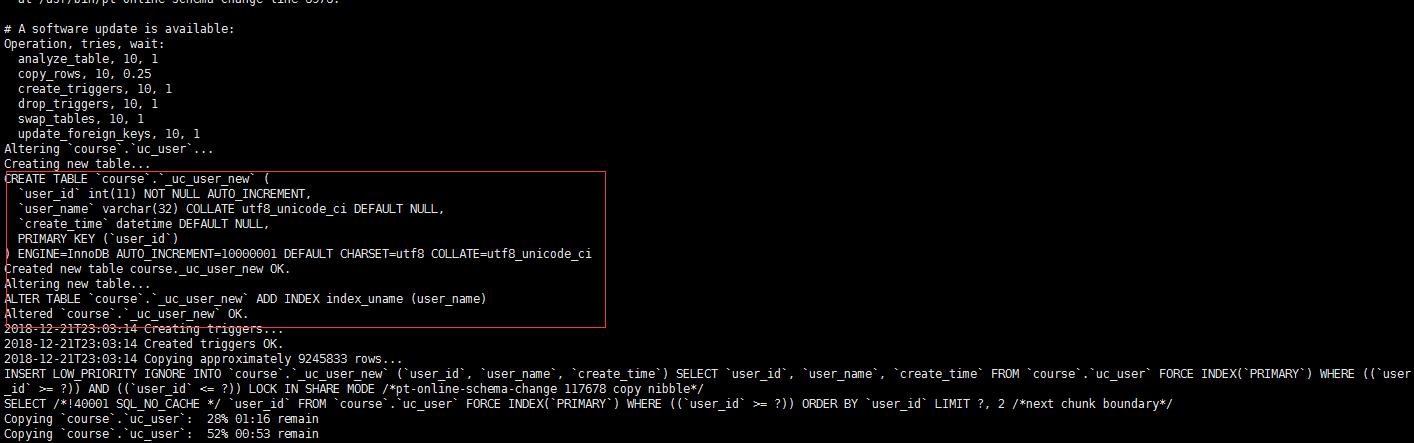
修改过程中
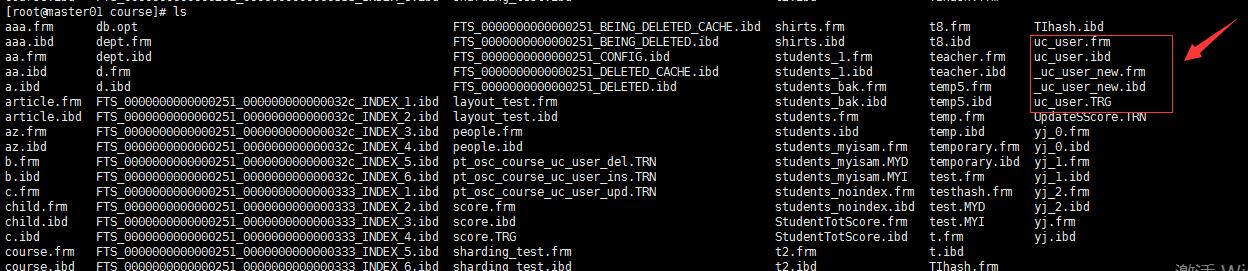
查看uc_user表的结构
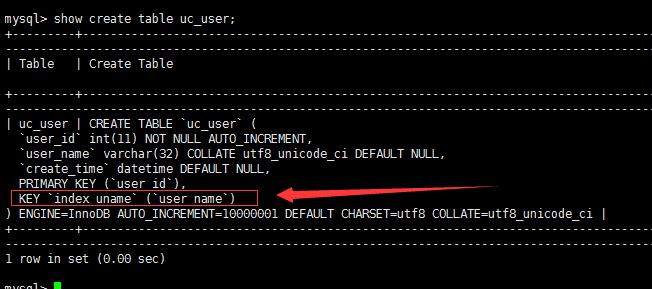
ok
-
对uc_user 添加periodID列
pt-online-schema-change \\ --user=root --password=\'123456\' --port=3306 --host=127.0.0.1 \\ --critical-load Threads_running=200 --alter "ADD COLUMN periodID int(11)" \\ D=course,t=uc_user --print --execute
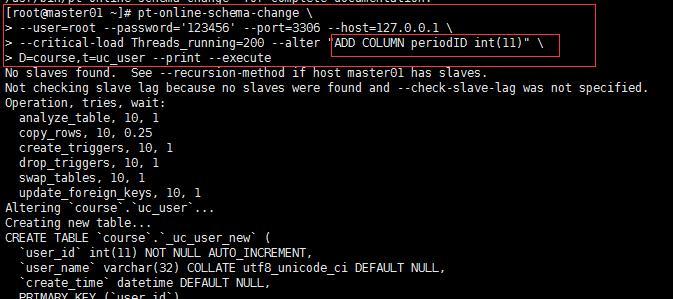
ok
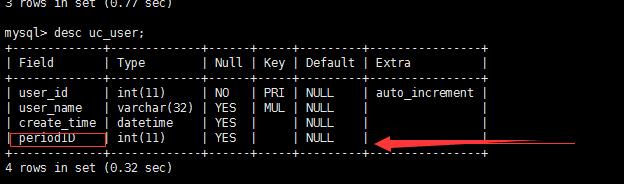
3. 删除列 periodID
删除过程中,中断这个语句会发生什么,看看创建的_uc_user_new 触发器等,试一下。
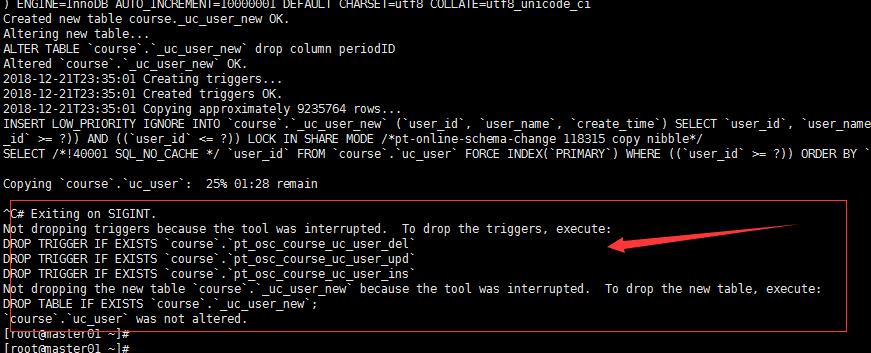
看看数据库是否还有_uc_user_new 还有这个表没有
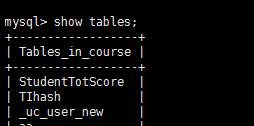
还有这个表, 那数据是不是还有,如果_uc_user_new 有数据,原表是否还有这个数据
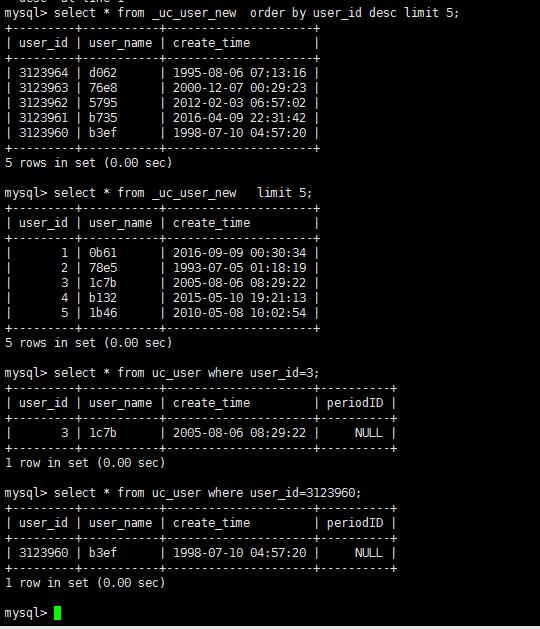
数据也都有,对原来这个表的数据没影响。
上面说过:
如果执行失败了,或手动停止了,需要手动删除下划线开头的表(_表名)及三个触发器
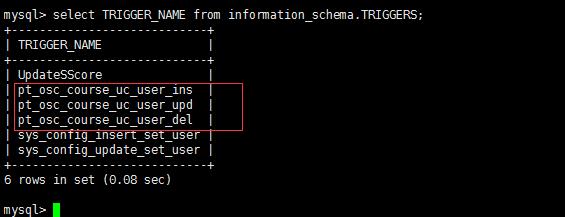

DROP TABLE IF EXISTS `course`.`_uc_user_new`; DROP TRIGGER IF EXISTS `course`.`pt_osc_course_uc_user_del`; DROP TRIGGER IF EXISTS `course`.`pt_osc_course_uc_user_upd`; DROP TRIGGER IF EXISTS `course`.`pt_osc_course_uc_user_ins`;
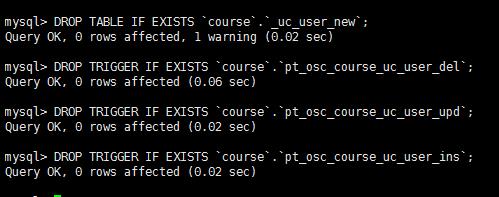
现在删除列 periodID
pt-online-schema-change \\ --user=root --password=\'123456\' --port=3306 --host=127.0.0.1 \\ --critical-load Threads_running=200 --alter "drop column periodID" D=course,t=uc_user --print --execute
验证:
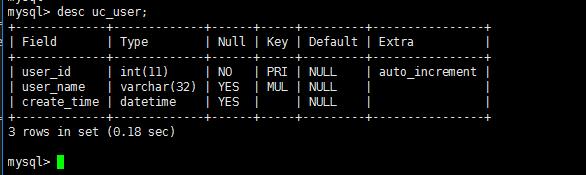
3.5 pt-query-digest
慢查询Log的分析—此对DBA抓取慢查询很有帮助:
使用这个的前提必须开启了MySQL慢查询.
虽然可以cat 慢查询的日志文件,但慢查询文件特别大了, 哪一个sql 执行是最慢的了,哪一个执行次数最多了。
用pt-query-digest 查询就很方便
3.5.1 pt-query-digest 常用参数
--create-review-table 当使用--review参数把分析结果输出到表中时,如果没有表就自动创建。 --create-history-table 当使用--history参数把分析结果输出到表中时,如果没有表就自动创建。 --filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析 --limit限制输出结果百分比或数量,默认值是20,即将最慢的20条语句输出,如果是50%则按总响应时间占比从大到小排序,输出到总和达到50%位置截止。 --host mysql服务器地址 --user mysql用户名 --password mysql用户密码 --history 将分析结果保存到表中,分析结果比较详细,下次再使用--history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化。 --review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用--review时,如果存在相同的语句分析,就不会记录到数据表中。 --output 分析结果输出类型,值可以是report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用report,以便于阅读。 --since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]”格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如12h就表示从12小时前开始统计。 --until 截止时间,配合—since可以分析一段时间内的慢查询。
3.5.2 pt-query-digst 案例
-
分析指定时间段的慢查询
分析2018-09-07 00:00:00 到 2018-12-24 15:50:00
pt-query-digest /usr/local/mysql/data/master01-slow.log --since \'2018-09-07 00:00:00\' --until \'2018-12-24 15:50:00\'
分析指定时间的慢查询日志 ,这样出的数据直接打印到屏幕上,可以输入到一个文件里 后面加上 > 就可以了
展示图如下:靠前的都是比较慢的SQL ,需要优先处理
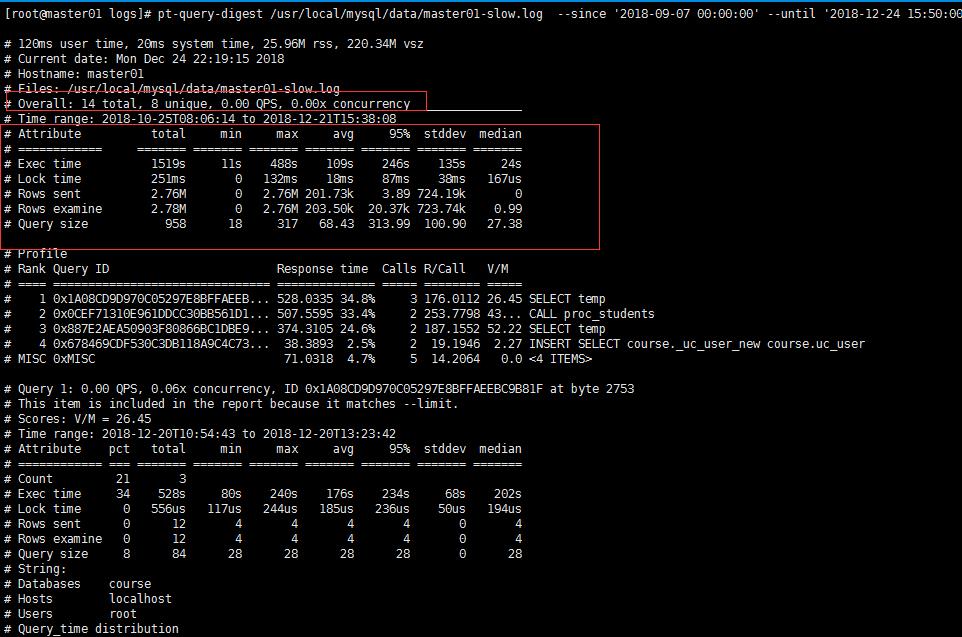
Overall: 总共有多少条查询,上例为总共14个查询(这是我的测试机器)。
Time range: 查询执行的时间范围。
unique: 唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询,该例为64。
total: 总计
min : 最小
max : 最大
avg : 平均 95%: 把所有值从小到大排列,位置位于95%的那个数,这个数一般最具有参考价值。
median : 中位数,把所有值从小到大排列,位置位于中间那个数。
2. 分析指含有select语句的慢查询
pt-query-digest --filter \'$event->{fingerprint} =~ m/^select/i\' /usr/local/mysql/data/master01-slow.log > slow_report4.log
3. 针对某个用户的慢查询
pt-query-digest --filter \'($event->{user} || "") =~ m/^root/i\' /usr/local/mysql/data/master01-slow.log > slow_report5.log
3.6 pt-slave-delay
--pt-slave-delay ---就是指定从库比主库延迟多长时间,从库上执行
MySQL 5.6 之后就有自带的延迟配置
延迟复制配置,通过设置Slave上的MASTER TO MASTER_DELAY
参数实现:
CHANGE MASTER TO MASTER_DELAY = N;
作用:
MySQL在做主从同步时,可以指定从库从主库延迟多长时间,这样有一个好处,当主库上勿删数据时,可以到延迟从库上stop slave 上,然后可以从从库上恢复一些数据
原理:
通过启动和停止从服务器的sql线程来设置从落后于主。它是通过slave的relay log(中继日志)的position(偏移量),不断启动,关闭replication SQL thread来保持主从一直延时固定长的时间来实现。因此不需要连接到主服务器。如果IO进程不落后主服务器太多的话,这个检查方式还是有效的,如果IO线程延时过大,pt-slave-delay也可以连接到主库来获取binlog的位置信息。
例如:
pt-slave-delay --delay=1m --interval=15s --run-time=10m u=root,p=123456,h=127.0.0.1,P=3306
--delay :从库延迟主库的时间,上面为1分钟。 --interval :检查的间隔时间,上面为15s检查一次。(可选),不选则1分钟检查一次(默认)。 --run-time :该命令运行时间,上面为该命令运行10分钟关闭。(可选),不选则永远运行。--一搬不加此参数
注意:延迟的时间实际为 delay+interval,即该命令的让从延迟主75s。
3.7 pt-table-checksum & pt-table-sync
3.7.1 检查 pt-table-checksum
pt-table-checksum & pt-table-sync—–检查主从是否一致性—–检查主从不一致之后用这个工具进行处理
这两个一搬是搭配使用(一搬主从不一样肯定要查一下,不能直接修复就完事了。)
–参数讲解:
replicate=test.checksum:主从不一致的结果放到哪一张表中,一般我放在一个既有的数据库中,这个checksum表由pt-table-checksum工具自行建立。 databases=testdb :我们要检测的数据库有哪些,这里是testdb数据库,如果想检测所有数据库那么就不要写这个参数了,如果有多个数据库,我们用逗号连接就可以了。 host=’127.0.0.1’ :主库的IP地址或者主机名。 user=dba :主机用户名。 —确定此用户可以访问主从数据库 port=6006:主库端口号。 recursion-method=hosts :主库探测从库的方式。 empty-replicate-table:清理上一次的检测结果后开始新的检测。 no-check-bin-log-format:不检查二进制日志格式,鉴于目前大多数生产数据库都将二进制日志设置为“ROW”格式,而我们的pt-table-checksum会话会自行设定用“STATEMENT”格式,
所以这个选项请务必加上。(具体什么格式,在服务器最好查一下show variables like ‘binlog_format’;)
pt-table-checksum的使用
pt-table-checksum --nocheck-replication-filters \\ --no-check-binlog-format --replicate=test.checksums --recursion-method=hosts --databases=log_manage \\ h=localhost,u=sys_dba,p=\'密码\',P=6006
注:主与从库一定要有一个公用帐号。权限大一些,也就是从主库能登录到从库上的。不然会有如下报错。提示找不到,因为会自动找从库比对

下面加上正确的权限之后:

TS :完成检查的时间。
ERRORS :检查时候发生错误和警告的数量。
DIFFS :0表示一致,1表示不一致。当指定–no-replicate-check时,会一直为0,当指定–replicate-check-only会显示不同的信息。
ROWS :表的行数。
CHUNKS :被划分到表中的块的数目。
SKIPPED :由于错误或警告或过大,则跳过块的数目。
TIME :执行的时间。
TABLE :被检查的表名
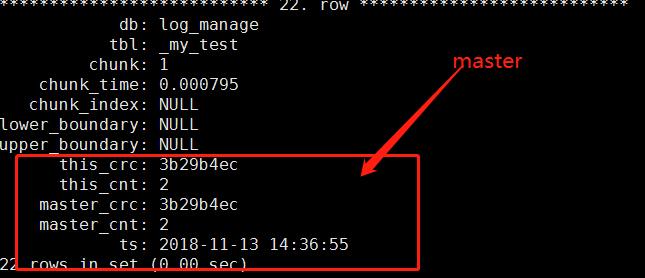
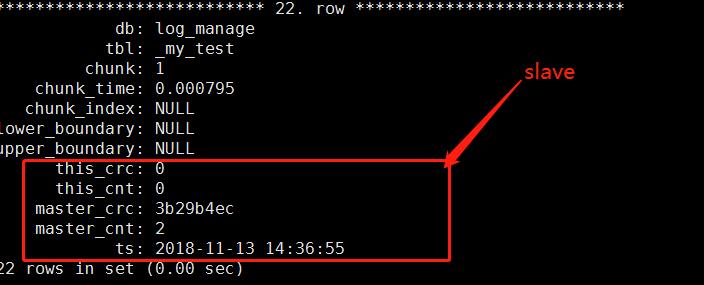
检测DIFF有异常时,立刻到从库去看:记住了是从库:this_crc.这是本机。
上面这个是正常没有差异的
SELECT db, tbl, SUM(this_cnt) AS total_rows, COUNT(*) AS chunks FROM test.checksums WHERE ( master_cnt <> this_cnt OR master_crc <> this_crc OR ISNULL(master_crc) <> ISNULL(this_crc)) GROUP BY db, tbl;
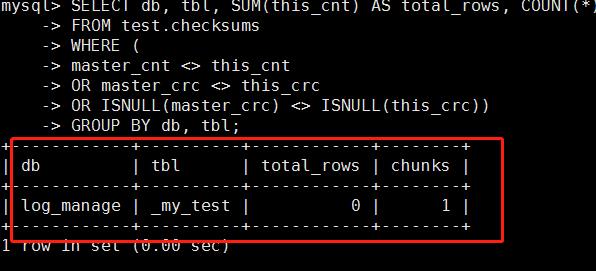
3.7.2 修复pt-table-sync
检测有差异之后到从库上执行一下修复:
用这个前提是此表必须要有主键或唯一索引。

pt-table-sync --sync-to-master --replicate=test.checksums h=127.0.0.1,u=dba,P=6006,p=‘密码’ --print
只打印不执行—看详细

执行
pt-table-sync --sync-to-master --replicate=test.checksums h=127.0.0.1,u=dba,P=6006,p=\'密码\' --execute
开始执行就修复了,再看一下就OK了
再检测就没有了
3.8 pt-find
1. 找出大于10G的表
/usr/bin/pt-find --socket=/mysql-socket的文件 --user=root --password=\'密码\' --port=6006 --tablesize +10G
2. 25分钟之修改过的表
/usr/bin/pt-find --socket=/mysql-socket的文件 --user=root --password=\'密码\' --port=6006 --mmin -25
3. 空表没有数据的表
/usr/bin/pt-find --socket=/mysql-socket的文件 --user=root --password=\'密码\' --port=6006 --empty
3.9 pt-slave-restart
pt-slave-restart —–主从报错,跳过报错 ,在从库执行
常用参数:
--always :永不停止slave线程,手工停止也不行
--ask-pass :替换-p命令,防止密码输入被身后的开发窥屏
--error-numbers :指定跳过哪些错误,可用,进行分隔
--error-text :根据错误信息进行匹配跳过
--log :输出到文件
--recurse :在主端执行,监控从端
--runtime :工具执行多长时间后退出:默认秒, m=minute,h=hours,d=days
--slave-user --slave-password :从库的账号密码,从主端运行时使用
--skip-count :一次跳过错误的个数,胆大的可以设置大些,不指定默认1个
--master-uuid :级联复制的时候,指定跳过上级或者上上级事务的错误
--until-master :到达指定的master_log_pos,file位置后停止,
格式:”file:pos“
--until-relay :和上面一样,但是时根据relay_log的位置来停止
自动跳过主从同步1032的报错 建议在从库上如下这个就可以了,多个以逗号隔开就可以了
例:
/usr/bin/pt-slave-restart --user=root --password=\'密码\' --port=6006 --host=127.0.0.1 --error-numbers=1032
3.10 pt-mysql-summary
pt-mysql-summary —MySQL的描述信息,包括配置文件的描述
show processlist 查看MySQL的连接,
pt-find打印出来的信息包括:版本信息、数据目录、命令的统计、用户,数据库以及复制等信息还包括各个变量(status、variables)信息和各个变量的比例信息,还有配置文件等信息。
pt-mysql-summary --user=root --password=\'password\' --host=127.0.0.1 --port=6007
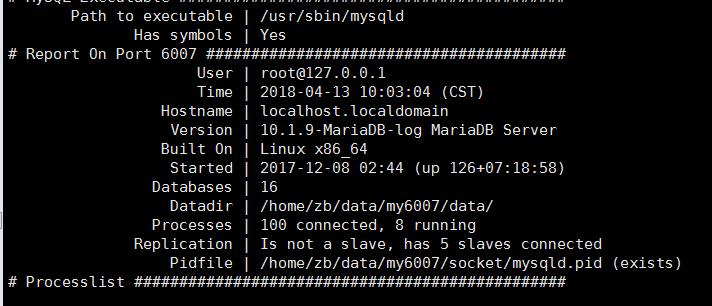
工具很多 可以看看官方文档:https://www.percona.com/doc/percona-toolkit/LATEST/index.html
以上是关于Percona Toolkit mysql辅助利器的主要内容,如果未能解决你的问题,请参考以下文章