消息队列介绍、RabbitMQ&Redis的重点介绍与简单应用
消息队列介绍、RabbitMQ、Redis
一、什么是消息队列
这个概念我们百度Google能查到一大堆文章,所以我就通俗的讲下消息队列的基本思路。
还记得原来写过Queue的文章,不管是线程queue还是进程queue他都是一种消息队列。他都是基于生产者消费者模型来处理消息。
Python中的进程queue,是用于父进程与子进程,或者同属于一个父进程下的多个子进程之间进行信息交互。注意这种queue只能在同一个python程序下才能用,如果两个python程序,或者Python和别的什么程序,他是不能共用的。
那么问题来了,那怎么办那??我就是要用我的QQ程序来调用我的Word文档,怎么办??
这时候跨程序的消息队列工具就出现了,现在主流的有:RabbitQM,ZeroMQ(saltstack就是用的他),Kafka,Redis的消息队列等等
具体什么原理呢?
我想要用QQ调用word,QQ先链接消息队列(broker),把调用word的消息发给broker,如果word和QQ在一个频道,好像是我在微博关注了你,你一发消息,我这里就能收到你的信息了。word一看QQ要启动我,好啊,那来啊,互相伤害啊,然后就启动了。
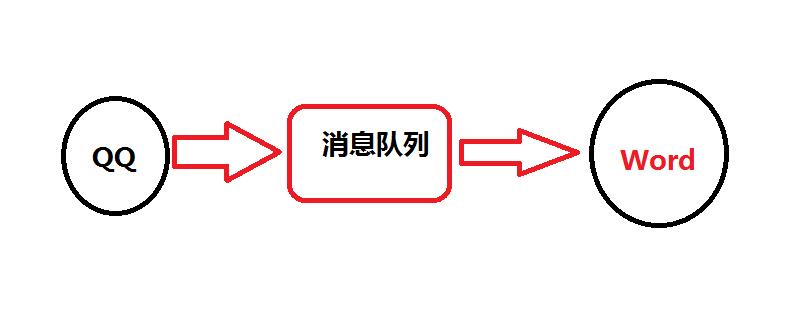
有的大神就说了,感觉好麻烦,还得经过一个中间商,我直接QQ给word发socket请求不行吗,多直接啊~~我微微一笑,从原理上确实是可以,可是实际操作却太难了,消息队列有完善、专业的消息处理机制,可以同时处理大量应用发来的海量消息,并且几乎没有丢消息的可能,而且,关键一点,用着很方便,不用管人家怎么处理你的消息,丢给他就好啦。
二、RabbitMQ介绍与简单应用
1、安装
RabbitMQ是用erlang语言开发的,所以先装语言环境
erlang安装好后,就装RabbitMQ,上官网下rpm,源码,或者yum装都行。
对了,Python开发环境需要pika模块支持
|
1
2
3
4
5
6
7
|
pip install pikaoreasy_install pikaor源码 https://pypi.python.org/pypi/pika |
2、RabbitMQ基本架构及原理
下面为RabbitMQ的基本使用原理的架构图:
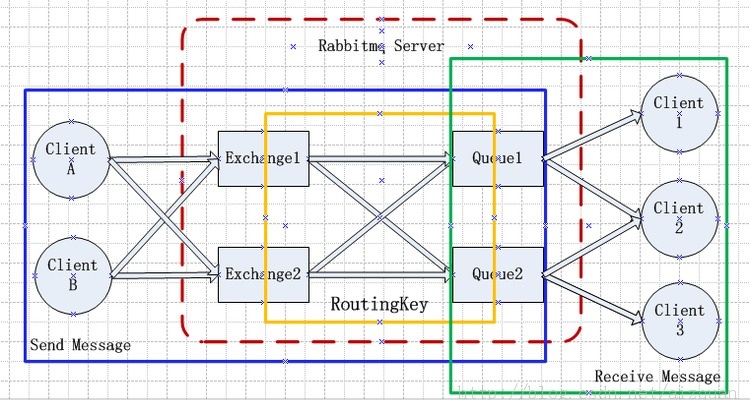
这个系统架构图版权属于sunjun041640。
RabbitMQ Server: 也叫broker server,它不是运送食物的卡车,而是一种传输服务。原话是RabbitMQisn’t a food truck, it’s a delivery service. 他的角色就是维护一条从Producer到Consumer的路线,保证数据能够按照指定的方式进行传输。但是这个保证也不是100%的保证,但是对于普通的应用来说这已经足够了。当然对于商业系统来说,可以再做一层数据一致性的guard,就可以彻底保证系统的一致性了。
Client A & B: 也叫Producer,数据的发送方。createmessages and publish (send) them to a broker server (RabbitMQ).一个Message有两个部分:payload(有效载荷)和label(标签)。payload顾名思义就是传输的数据。label是exchange的名字或者说是一个tag,它描述了payload,而且RabbitMQ也是通过这个label来决定把这个Message发给哪个Consumer。AMQP仅仅描述了label,而RabbitMQ决定了如何使用这个label的规则。
Client 1,2,3:也叫Consumer,数据的接收方。Consumersattach to a broker server (RabbitMQ) and subscribe to a queue。把queue比作是一个有名字的邮箱。当有Message到达某个邮箱后,RabbitMQ把它发送给它的某个订阅者即Consumer。当然可能会把同一个Message发送给很多的Consumer。在这个Message中,只有payload,label已经被删掉了。对于Consumer来说,它是不知道谁发送的这个信息的。就是协议本身不支持。但是当然了如果Producer发送的payload包含了Producer的信息就另当别论了。
对于一个数据从Producer到Consumer的正确传递,还有三个概念需要明确:exchanges, queues and bindings。
Exchanges are where producers publish their messages.
Queuesare where the messages end up and are received by consumers
Bindings are how the messages get routed from the exchange to particular queues.
还有几个概念是上述图中没有标明的,那就是Connection(连接),Channel(通道,频道)。
Connection: 就是一个TCP的连接。Producer和Consumer都是通过TCP连接到RabbitMQ Server的。以后我们可以看到,程序的起始处就是建立这个TCP连接。
Channels: 虚拟连接。它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是程序起始建立TCP连接,第二步就是建立这个Channel。
那么,为什么使用Channel,而不是直接使用TCP连接?
对于OS来说,建立和关闭TCP连接是有代价的,频繁的建立关闭TCP连接对于系统的性能有很大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。但是,在TCP连接中建立Channel是没有上述代价的。对于Producer或者Consumer来说,可以并发的使用多个Channel进行Publish或者Receive。有实验表明,1s的数据可以Publish10K的数据包。当然对于不同的硬件环境,不同的数据包大小这个数据肯定不一样,但是我只想说明,对于普通的Consumer或者Producer来说,这已经足够了。如果不够用,你考虑的应该是如何细化split你的设计。
3、基本原理搞清了,下面来个简单的RabbitMQ的使用栗子:
一对一的发送与接收
发送端:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#!/usr/bin/env pythonimport pika connection = pika.BlockingConnection(pika.ConnectionParameters( \'localhost\'))channel = connection.channel() #声明queuechannel.queue_declare(queue=\'hello\') # RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.channel.basic_publish(exchange=\'\', routing_key=\'hello\', body=\'Hello World!\')print(" [x] Sent \'Hello World!\'")connection.close() |
接收端:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#_*_coding:utf-8_*___author__ = \'Alex Li\'import pika connection = pika.BlockingConnection(pika.ConnectionParameters( \'localhost\'))channel = connection.channel() #You may ask why we declare the queue again ‒ we have already declared it in our previous code.# We could avoid that if we were sure that the queue already exists. For example if send.py program#was run before. But we\'re not yet sure which program to run first. In such cases it\'s a good# practice to repeat declaring the queue in both programs.channel.queue_declare(queue=\'hello\') def callback(ch, method, properties, body): print(" [x] Received %r" % body) channel.basic_consume(callback, queue=\'hello\', no_ack=True) print(\' [*] Waiting for messages. To exit press CTRL+C\')channel.start_consuming() |
一个生产者,多个消费者,实现消息轮询分发:
生产者:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
import pikaimport timeconnection = pika.BlockingConnection(pika.ConnectionParameters( \'localhost\'))channel = connection.channel() # 声明queuechannel.queue_declare(queue=\'task_queue\') # n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.import sys message = \' \'.join(sys.argv[1:]) or "Hello World! %s" % time.time()channel.basic_publish(exchange=\'\', routing_key=\'task_queue\', body=message, properties=pika.BasicProperties( delivery_mode=2, # make message persistent ) )print(" [x] Sent %r" % message)connection.close() |
消费者:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#_*_coding:utf-8_*_ import pika, time connection = pika.BlockingConnection(pika.ConnectionParameters( \'localhost\'))channel = connection.channel() def callback(ch, method, properties, body): print(" [x] Received %r" % body) time.sleep(20) print(" [x] Done") print("method.delivery_tag",method.delivery_tag) ch.basic_ack(delivery_tag=method.delivery_tag) #告诉发送端我已经处理完了 channel.basic_consume(callback, #回调函数 queue=\'task_queue\', no_ack=True ) print(\' [*] Waiting for messages. To exit press CTRL+C\')channel.start_consuming() |
当有多个消费者消费时,如果其中一个在处理消息时挂啦,那么消息会不会丢失呢?
我们可以看到在消费者代码有一个参数,no_ack=true,他的作用是如果为true,不管消费者有没有处理消息,都不给生产者反馈,这样的话,如果真的出现消费者异常挂掉了,那么正在处理的消息就真的丢了。如果no_ack=false,消费者在处理完消息后会给生产者反馈,我处理完了,这时生产者才把消息删掉,如果生产者发现消费者没正常反馈信息,就会把这条消息发给别的消费者,保证消息不丢失。
4、消息持久化
上面说的是客户端挂了,服务端还能保存消息不丢失,那服务端挂了咋弄,答案是如果服务端不进行数据持久化,服务挂了连channel都不会给你留的。。。。。
我们在声明队列时需要加句话:
|
1
|
channel.queue_declare(queue=\'hello\', durable=True) |
声明队列持久化。服务端和客户端都要写。
写了这句就行了么??不行,这只是把咱们的队列持久化了,队列里的消息依然会丢,然并卵啊。。。
所以要想不丢数据,还得再加代码:
我们需要在生产者这一段加入下面的代码,主要是那个properties
|
1
2
3
4
5
6
|
channel.basic_publish(exchange=\'\', routing_key="task_queue", body=message, properties=pika.BasicProperties( delivery_mode = 2, # make message persistent )) |
我们看到delivery_mode这个参数,delivery_mode=2就是消息持久化的作用。
5、消息的公平分发
当消费者的处理性能有差异时,可能会出现性能好的机器处理消息速度比接受速度还快,性能不好的机器由于处理的慢会出现消息堵塞,最后就是好机器闲着,一般机器忙不过来的情况,造成资源浪费。这里RabbitMQ会提供一个实现消息公平分发的机制,使机器有多大能力收多少消息。
这个机制的配置就是perfetch=1
|
1
|
channel.basic_qos(prefetch_count=1) |
带消息持久化+公平分发的完整示例
生产者
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#!/usr/bin/env pythonimport pikaimport sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\'))channel = connection.channel() channel.queue_declare(queue=\'task_queue\', durable=True) message = \' \'.join(sys.argv[1:]) or "Hello World!"channel.basic_publish(exchange=\'\', routing_key=\'task_queue\', body=message, properties=pika.BasicProperties( delivery_mode = 2, # make message persistent ))print(" [x] Sent %r" % message)connection.close() |
消费者
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
#!/usr/bin/env pythonimport pikaimport time connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\'))channel = connection.channel() channel.queue_declare(queue=\'task_queue\', durable=True)print(\' [*] Waiting for messages. To exit press CTRL+C\') def callback(ch, method, properties, body): print(" [x] Received %r" % body) time.sleep(10) print(" [x] Done") ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1)channel.basic_consume(callback, queue=\'task_queue\') channel.start_consuming() |
上面栗子用sleep模拟处理时间,我们可以多起几个不同sleep的消费者,观察他们接受消息的规律,我们就会发现,处理的快的消费者接受的消息多,慢的就少。
6、Publish\\Subscribe(消息发布\\订阅)
如果我们不想一对一的发送消息,而是想让所有channel都收到,就可以用所谓的广播来进行消息发布。这时我们就用到了exchange
Exchange在定义的时候是有类型的,以决定到底是哪些Queue符合条件,可以接收消息
fanout: 所有bind到此exchange的queue都可以接收消息
direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
表达式符号说明:#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aa.a,aaa.a等
*.a会匹配a.a,b.a,c.a等
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
headers: 通过headers 来决定把消息发给哪些queue
消息publisher
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import pikaimport sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\'))channel = connection.channel() channel.exchange_declare(exchange=\'logs\', type=\'fanout\') message = \' \'.join(sys.argv[1:]) or "info: Hello World!"channel.basic_publish(exchange=\'logs\', routing_key=\'\', body=message)print(" [x] Sent %r" % message)connection.close() |
消息subscriber
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#_*_coding:utf-8_*___author__ = \'Alex Li\'import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\'))channel = connection.channel() channel.exchange_declare(exchange=\'logs\', type=\'fanout\') result = channel.queue_declare(exclusive=True) #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除queue_name = result.method.queue channel.queue_bind(exchange=\'logs\', queue=queue_name) print(\' [*] Waiting for logs. To exit press CTRL+C\') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming() |
7、有选择的接收消息(exchange type=direct)
可以指定某些更细致的过滤规则来进行指定channel发送
publisher
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import pikaimport sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\'))channel = connection.channel() channel.exchange_declare(exchange=\'direct_logs\', type=\'direct\') severity = sys.argv[1] if len(sys.argv) > 1 else \'info\'message = \' \'.join(sys.argv[2:]) or \'Hello World!\'channel.basic_publish(exchange=\'direct_logs\',以上是关于消息队列介绍RabbitMQ&Redis的重点介绍与简单应用的主要内容,如果未能解决你的问题,请参考以下文章
|