SQL进阶随笔--case用法
Posted Apprentice
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL进阶随笔--case用法相关的知识,希望对你有一定的参考价值。
SQL进阶一整个是根据我看了pdf版本的整理以及自己的见解整理。后期也方便我自己查看和复习。
CASE 表达式
CASE 表达式是从 SQL-92 标准开始被引入的。可能因为它是相对较新的技术,所以尽管使用起来非常便利,但其真正的价值却并不怎么为人所知。很多人不用它,或者用它的简略版函数,例如 DECODE(Oracle)、IF (mysql)等。然而,正如 Joe Celko 所说,CASE表达式也许是 SQL-92 标准里加入的最有用的特性。如果能用好它,那么 SQL 能解决的问题就会更广泛,写法也会更加漂亮。而且,因为 CASE 表达式是不依赖于具体数据库的技术,所以可以提高 SQL 代码的可移植性。这里强烈推荐大家改用 CASE 表达式,特别是使用DECODE 函数的 Oracle 用户 。
正对decode,我们和case进行下对比,然后引出我们的主角case。
DECODE 是 Oracle 用户很熟悉的函数,它有以下四个不如 CASE 表达式的地方。
• 它是 Oracle 独有的函数,所以不具有可移植性。
• 分支数最大支持 127 个(参数上限 255 个,一个分支需要 2 个参数)。
• 如果分支数增加,代码会变得非常难读。
• 表达能力较弱。具体来说,参数里不能使用谓词,也不能嵌套子查询。
ok,现在用一些案例去了解学习下优点众多的case用法:
#CASE 表达式概述
首先我们来学习一下基本的写法,CASE 表达式有简单 CASE 表达式(simple case expression)和搜索 CASE 表达式(searched caseexpression)两种写法,它们分别如下所示。
■CASE 表达式的写法
-- 简单CASE 表达式 CASE sex WHEN \'1\' THEN \'男\' WHEN \'2\' THEN \'女\' ELSE \'其他\' END -- 搜索CASE 表达式 CASE WHEN sex = \'1\' THEN \'男\' WHEN sex = \'2\' THEN \'女\' ELSE \'其他\' END
这两种写法的执行结果是相同的,“sex”列(字段)如果是 \'1\' ,那么结果为男;如果是 \'2\' ,那么结果为女。简单 CASE 表达式正如其名,写法简单,但能实现的事情比较有限。简单 CASE 表达式能写的条件,搜索 CASE 表达式也能写,所以后面采用搜索 CASE 表达式的写法。
我们在编写 SQL 语句的时候需要注意,在发现为真的 WHEN 子句时,CASE 表达式的真假值判断就会中止,而剩余的 WHEN 子句会被忽略。为了避免引起不必要的混乱,使用 WHEN 子句时要注意条件的排他性。
■剩余的 WHEN 子句被忽略的写法示例
-- 例如,这样写的话,结果里不会出现“第二” CASE WHEN col_1 IN (\'a\', \'b\') THEN \'第一\' WHEN col_1 IN (\'a\') THEN \'第二\' ELSE \'其他\' END
注意事项 1:统一各分支返回的数据类型
虽然这一点无需多言,但这里还是要强调一下:一定要注意 CASE 表达式里各个分支返回的数据类型是否一致。某个分支返回字符型,而其他分支返回数值型的写法是不正确的。
注意事项 2:不要忘了写 END
使用 CASE 表达式的时候,最容易出现的语法错误是忘记写 END 。虽然忘记写时程序会返回比较容易理解的错误消息,不算多么致命的错误。但是,感觉自己写得没问题,而执行时却出错的情况大多是由这个原因引起的,所以请一定注意一下。
注意事项 3:养成写 ELSE 子句的习惯
与 END 不同,ELSE 子句是可选的,不写也不会出错。不写 ELSE 子句时,CASE 表达式的执行结果是 NULL 。但是不写可能会造成“语法没有错误,结果却不对”这种不易追查原因的麻烦,所以最好明确地写上 ELSE 子句(即便是在结果可以为 NULL 的情况下)。养成这样的习惯后,我们从代码上就可以清楚地看到这种条件下会生成 NULL,而且将来代码有修改时也能减少失误。
#将已有编号方式转换为新的方式并统计
在进行非定制化统计时,我们经常会遇到将已有编号方式转换为另外一种便于分析的方式并进行统计的需求。例如,现在有一张按照“‘1:北海道’、‘2:青森’、……、‘47:冲绳’”这种编号方式来统计都道府县 人口的表,我们需要以东北、关东、九州等地区为单位来分组,并统计人口数量。具体来说,就是统计下表 PopTbl 中的内容,得出如右表“统计结果”所示的结果。
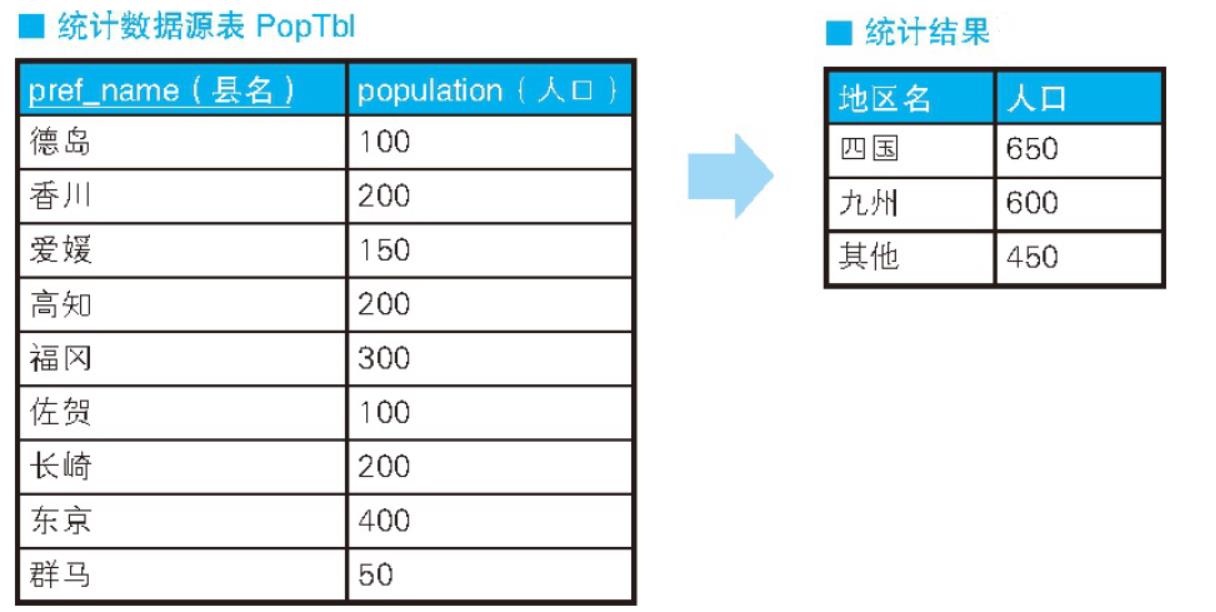
在“统计结果”这张表中,“四国”对应的是表 PopTbl 中的“德岛、香川、爱媛、高知 ”,“九 州”对应的是表 PopTbl 中的“福冈、佐贺、长崎”。
大家会怎么实现呢?定义一个包含“地区编号”列的视图是一种做法,但是这样一来,需要添加的列的数量将等同于统计对象的编号个数,而且很难动态地修改。
而如果使用 CASE 表达式,则用如下所示的一条 SQL 语句就可以完成。为了便于理解,这里用县名(pref_name )代替编号作为GROUP BY 的列。
-- 把县编号转换成地区编号(1) SELECT CASE pref_name WHEN \'德岛\' THEN \'四国\' WHEN \'香川\' THEN \'四国\' WHEN \'爱媛\' THEN \'四国\' WHEN \'高知\' THEN \'四国\' WHEN \'福冈\' THEN \'九州\' WHEN \'佐贺\' THEN \'九州\' WHEN \'长崎\' THEN \'九州\' ELSE \'其他\' END AS district, SUM(population) FROM PopTbl GROUP BY CASE pref_name WHEN \'德岛\' THEN \'四国\' WHEN \'香川\' THEN \'四国\' WHEN \'爱媛\' THEN \'四国\' WHEN \'高知\' THEN \'四国\' WHEN \'福冈\' THEN \'九州\' WHEN \'佐贺\' THEN \'九州\' WHEN \'长崎\' THEN \'九州\' ELSE \'其他\' END;
这里的关键在于将 SELECT 子句里的 CASE 表达式复制到 GROUP BY子句里。需要注意的是,如果对转换前的列“pref_name ”进行 GROUP BY ,就得不到正确的结果(因为这并不会引起语法错误,所以容易被忽视)。
同样地,也可以将数值按照适当的级别进行分类统计。例如,要按人口数量等级(pop_class )查询都道府县个数的时候,就可以像下面这样写 SQL 语句。
-- 按人口数量等级划分都道府县 SELECT CASE WHEN population < 100 THEN \'01\' WHEN population >= 100 AND population < 200 THEN \'02\' WHEN population >= 200 AND population < 300 THEN \'03\' WHEN population >= 300 THEN \'04\' ELSE NULL END AS pop_class, COUNT(*) AS cnt FROM PopTbl GROUP BY CASE WHEN population < 100 THEN \'01\' WHEN population >= 100 AND population < 200 THEN \'02\' WHEN population >= 200 AND population < 300 THEN \'03\' WHEN population >= 300 THEN \'04\' ELSE NULL END;
pop_class cnt --------- ---- 01 1 02 3 03 3 04 2
这个技巧非常好用。不过,必须在 SELECT 子句和 GROUP BY 子句这两处写一样的 CASE 表达式,这有点儿麻烦。后期需要修改的时候,很容易发生只改了这一处而忘掉改另一处的失误。
所以,如果我们可以像下面这样写,那就方便多了。
-- 把县编号转换成地区编号(2) :将CASE 表达式归纳到一处 SELECT CASE pref_name WHEN \'德岛\' THEN \'四国\' WHEN \'香川\' THEN \'四国\' WHEN \'爱媛\' THEN \'四国\' WHEN \'高知\' THEN \'四国\' WHEN \'福冈\' THEN \'九州\' WHEN \'佐贺\' THEN \'九州\' WHEN \'长崎\' THEN \'九州\' ELSE \'其他\' END AS district, SUM(population) FROM PopTbl GROUP BY district; ←-------GROUP BY 子句里引用了SELECT 子句中定义的别名
但是没错,这里的 GROUP BY 子句使用的正是 SELECT 子句里定义的列的别称——district 。但是严格来说,这种写法是违反标准 SQL 的规则的。因为 GROUP BY 子句比 SELECT 语句先执行,所以在 GROUP BY 子句中引用在 SELECT 子句里定义的别称是不被允许的。事实上,在 Oracle、DB2、SQL Server 等数据库里采用这种写法时就会出错。
不过也有支持这种 SQL 语句的数据库,例如在 PostgreSQL 和MySQL 中,这个查询语句就可以顺利执行。这是因为,这些数据库在执行查询语句时,会先对 SELECT 子句里的列表进行扫描,并对列进行计算。不过因为这是违反标准的写法,所以这里不强烈推荐大家使用。但是,这样写出来的 SQL 语句确实非常简洁,而且可读性也很好。
■用一条 SQL 语句进行不同条件的统计
进行不同条件的统计是 CASE 表达式的著名用法之一。例如,我们需要往存储各县人口数量的表 PopTbl 里添加上“性别”列,然后求按性别、县名汇总的人数。具体来说,就是统计表 PopTbl2 中的数据,然后求出如表“统计结果”所示的结果。图片没有截取完全。
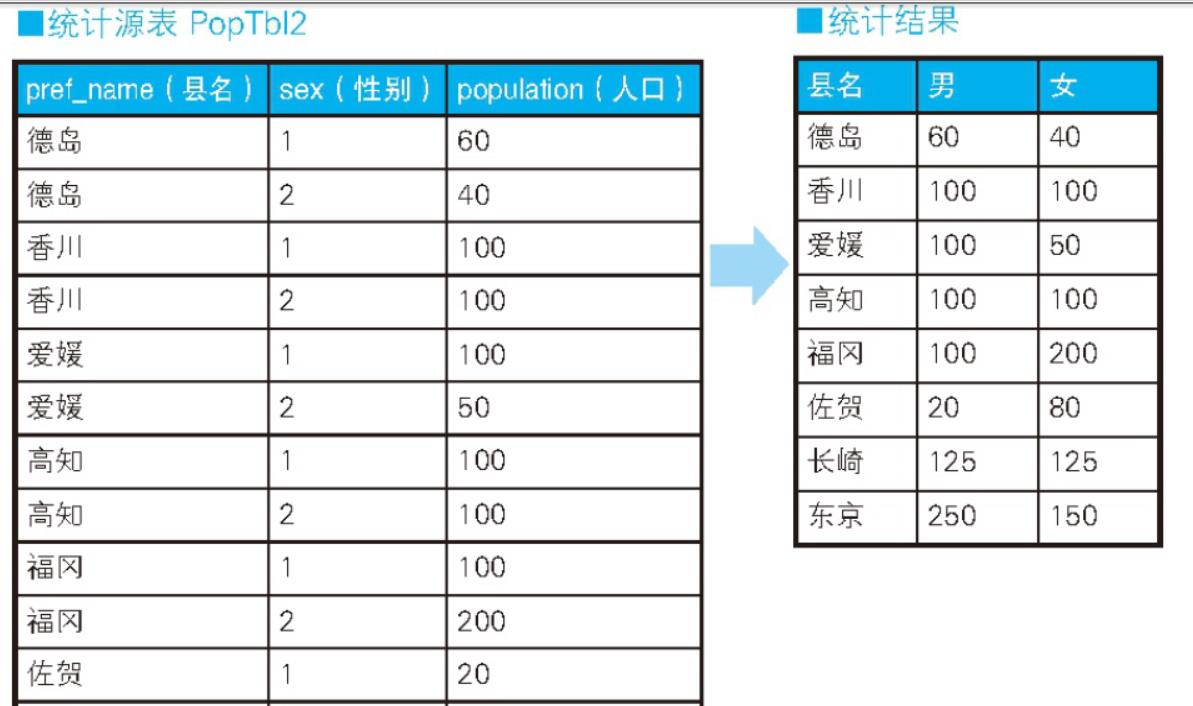
通常的做法是像下面这样,通过在 WHERE 子句里分别写上不同的条件,然后执行两条 SQL 语句来查询。
■示例代码 3
-- 男性人口 SELECT pref_name, SUM(population) FROM PopTbl2 WHERE sex = \'1\' GROUP BY pref_name; -- 女性人口 SELECT pref_name, SUM(population) FROM PopTbl2 WHERE sex = \'2\' GROUP BY pref_name;
最后需要通过宿主语言或者应用程序将查询结果按列展开。如果使用UNION ,只用一条 SQL 语句就可以实现,但使用这种做法时,工作量并没有减少,SQL 语句也会变得很长。而如果使用 CASE 表达式,下面这一条简单的 SQL 语句就可以搞定。
SELECT pref_name, -- 男性人口 SUM( CASE WHEN sex = \'1\' THEN population ELSE 0 END) AS cnt_m, -- 女性人口 SUM( CASE WHEN sex = \'2\' THEN population ELSE 0 END) AS cnt_f FROM PopTbl2 GROUP BY pref_name;
上面这段代码所做的是,分别统计每个县的“男性”(即 \'1\' )人数和“女性”(即 \'2\' )人数。也就是说,这里是将“行结构”的数据转换成了“列结构”的数据。除了 SUM ,COUNT 、AVG 等聚合函数也都可以用于将行结构的数据转换成列结构的数据。
这个技巧可贵的地方在于,它能将 SQL 的查询结果转换为二维表的格式。如果只是简单地用 GROUP BY 进行聚合,那么查询后必须通过宿主语言或者 Excel 等应用程序将结果的格式转换一下,才能使之成为交叉表。看上面的执行结果会发现,此时输出的已经是侧栏为县名、表头为性别的交叉表了。在制作统计表时,这个功能非常方便。如果用一句话来形容这个技巧,可以这样说:
新手用 WHERE 子句进行条件分支,高手用 SELECT 子句进行条件分支。
以上是关于SQL进阶随笔--case用法的主要内容,如果未能解决你的问题,请参考以下文章