SQL Server 索引碎片产生原理重建索引和重新组织索引
Posted wissly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL Server 索引碎片产生原理重建索引和重新组织索引相关的知识,希望对你有一定的参考价值。
数据库存储本身是无序的,建立了聚集索引,会按照聚集索引物理顺序存入硬盘。既键值的逻辑顺序决定了表中相应行的物理顺序
多数情况下,数据库读取频率远高于写入频率,索引的存在 为了读取速度牺牲写入速度
页 为最小单位 8kb
区 物理连续的页(8页)的集合
内部碎片 数据库页内部产生的碎片,外部反之
碎片的产生:
有一个表里有8条数据,已经将一页填满,这个时候要插入第九条数据,页也就分裂了。这就产生了内部碎片。如下图所示(excel示意一下 懒癌晚期)
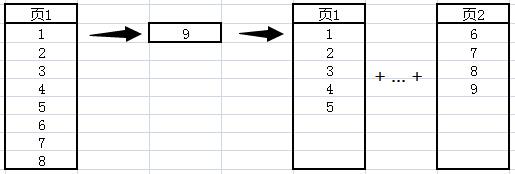
注: 不会将9单独分到第二页,索引B+树存储,会让存储尽量平衡,以减少检索层级。
且一般情况下SQL Server数据库默认设置有20%的填充因子(可设置),既新建页80%存数据,20%为update和insert预留。
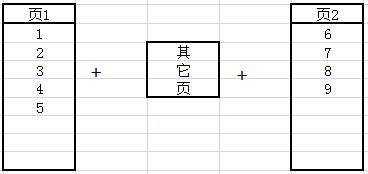
另外,在插入1~8之后 9之前,很可能数据库在这段时间有N多新增数据,也就是在物理结构上 页1 和 页2 无法连续。这就无法避免的产生了外部碎片。
查看碎片情况:
用到这个极重要的 sys.dm_db_index_physical_stats 动态函数,传闻数据库引擎在思考自己如何高效的查询数据的时候都要来这瞅瞅。
太高深的我并不会,目前我就看以下几个,其他参照MSDN
avg_fragmentation_in_percent =>当前索引碎片百分比 【如果碎片小于10%~20%,碎片不太可能会成为问题,如果索引碎片在20%~40%,碎片可能成为问题,但是可以通过索引重组来消除索引解决,大规模的碎片(当碎片大于40%),可能要求索引重建。】
avg_page_space_used_in_percent =>所有页中使用的可用数据存储空间的平均百分比
page_count =>索引或数据页的总数
select * from sys.dm_db_index_physical_stats(DB_ID() ,object_id(\'agent\') ,NULL,NULL,NULL)
碎片的解决:
1.删除索引并重建
这种方式有如下缺点:
索引不可用:在删除索引期间,索引不可用。
阻塞:卸载并重建索引会阻塞表上所有的其他请求,也可能被其他请求所阻塞。
对于删除聚集索引,则会导致对应的非聚集索引重建两次(删除时重建,建立时再重建,因为非聚集索引中有指向聚集索引的指针)。
唯一性约束:用于定义主键或者唯一性约束的索引不能使用DROP INDEX语句删除。而且,唯一性约束和主键都可能被外键约束引用。在主键卸载之前,所有引用该主键的外键必须首先被删除。尽管可以这么做,但这是一种冒险而且费时的碎片整理方法。
基于以上原因,不建议在生产数据库,尤其是非空闲时间不建议采用这种技术。
2.使用DROP_EXISTING语句重建索引
为了避免重建两次索引,使用DROP_EXISTING语句重建索引,因为这个语句是原子性的,不会导致非聚集索引重建两次,但同样的,这种方式也会造成阻塞。
CREATE UNIQUE CLUSTERED INDEX IX_C1 ON t1(c1) WITH (DROP_EXISTING = ON)
缺点:
阻塞:与卸载重建方法类似,这种技术也导致并面临来自其他访问该表(或该表的索引)的查询的阻塞问题。
使用约束的索引:与卸载重建不同,具有DROP_EXISTING子句的CREATE INDEX语句可以用于重新创建使用约束的索引。如果该约束是一个主键或与外键相关的唯一性约束,在CREATE语句中不能包含UNIQUE。
具有多个碎片化的索引的表:随着表数据产生碎片,索引常常也碎片化。如果使用这种碎片整理技术,表上所有索引都必须单独确认和重建。
3.使用ALTER INDEX REBUILD语句重建索引
使用这个语句同样也是重建索引,但是通过动态重建索引而不需要卸载并重建索引.是优于前两种方法的,但依旧会造成阻塞。可以通过ONLINE关键字减少锁,但会造成重建时间加长。
阻塞:这个依然有阻塞问题。
事务回滚:ALTER INDEX REBUILD完全是一个原子操作,如果它在结束前停止,所有到那时为止进行的碎片整理操作都将丢失,可以通过ONLINE关键字减少锁,但会造成重建时间加长。
4.使用ALTER INDEX REORGANIZE
这种方式不会重建索引,也不会生成新的页,仅仅是整理叶级数据,不涉及非叶级,当遇到加锁的页时跳过,所以不会造成阻塞。但同时,整理效果会差于前三种。
4种索引整理技术比较:
| 特性/问题 | 卸载并重建索引 | DROP_EXISTING | ALTER INDEX REBUILD | ALTER INDEX REORGANIZE |
| 在聚集索引碎片整理时,重建非聚集索引 | 两次 | 无 | 无 | 无 |
| 丢失索引 | 是 | 无 | 无 | 无 |
| 整理具有约束的索引的碎片 | 高度复杂 | 复杂性适中 | 简单 | 简单 |
| 同时进行多个索引的碎片整理 | 否 | 否 | 是 | 是 |
| 并发性 | 低 | 低 | 中等,取决于冰法用户活动 | 高 |
| 中途撤销 | 因为不使用事务,存在危险 | 进程丢失 | 进程丢失 | 进程被保留 |
| 碎片整理程度 | 高 | 高 | 高 | 中到低 |
| 应用新的填充因子 | 是 | 是 | 是 | 否 |
| 更新统计 | 是 | 是 | 是 | 否 |
参考: SQL Server索引的维护 - 索引碎片、填充因子 <第三篇>
msdn sys.dm_db_index_physical_stats (Transact-SQL)
以上是关于SQL Server 索引碎片产生原理重建索引和重新组织索引的主要内容,如果未能解决你的问题,请参考以下文章
sql 用于管理SQL Server重建和重组索引碎片的脚本