本地idea开发mapreduce程序提交到远程hadoop集群执行
Posted 小航哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了本地idea开发mapreduce程序提交到远程hadoop集群执行相关的知识,希望对你有一定的参考价值。
https://www.codetd.com/article/664330

https://blog.csdn.net/dream_an/article/details/84342770
通过idea开发mapreduce程序并直接run,提交到远程hadoop集群执行mapreduce。
简要流程:本地开发mapreduce程序–>设置yarn 模式 --> 直接本地run–>远程集群执行mapreduce程序;
完整的流程:本地开发mapreduce程序——> 设置yarn模式——>初次编译产生jar文件——>增加 job.setJar("mapreduce/build/libs/mapreduce-0.1.jar");——>直接在Idea中run——>远程集群执行mapreduce程序;
一图说明问题:
源码
build.gradle
plugins { id \'java\' } group \'com.ruizhiedu\' version \'0.1\' sourceCompatibility = 1.8 repositories { mavenCentral() } dependencies { compile group: \'org.apache.hadoop\', name: \'hadoop-common\', version: \'3.1.0\' compile group: \'org.apache.hadoop\', name: \'hadoop-mapreduce-client-core\', version: \'3.1.0\' compile group: \'org.apache.hadoop\', name: \'hadoop-mapreduce-client-jobclient\', version: \'3.1.0\' testCompile group: \'junit\', name: \'junit\', version: \'4.12\' }
java文件
输入、输出已经让我写死了,可以直接run。不需要再运行时候设置idea运行参数
wc.java
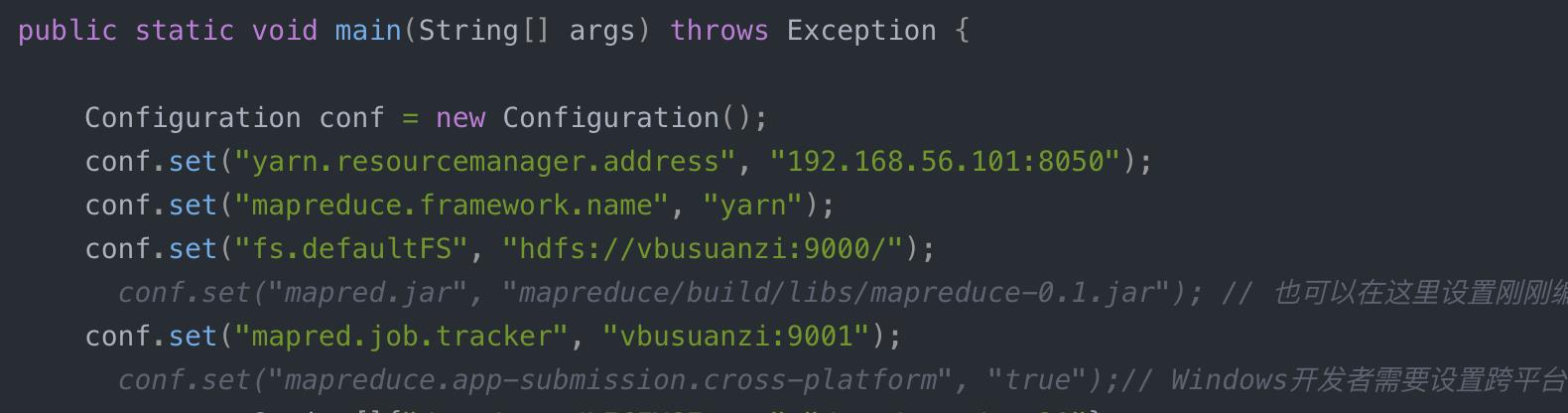
package com; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Counter; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; import org.apache.hadoop.util.StringUtils; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.net.URI; import java.util.*; /** * @author wangxiaolei(王小雷) * @since 2018/11/22 */ public class wc { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { static enum CountersEnum { INPUT_WORDS } private final static IntWritable one = new IntWritable(1); private Text word = new Text(); private boolean caseSensitive; private Set<String> patternsToSkip = new HashSet<String>(); private Configuration conf; private BufferedReader fis; @Override public void setup(Context context) throws IOException, InterruptedException { conf = context.getConfiguration(); caseSensitive = conf.getBoolean("wordcount.case.sensitive", true); if (conf.getBoolean("wordcount.skip.patterns", false)) { URI[] patternsURIs = Job.getInstance(conf).getCacheFiles(); for (URI patternsURI : patternsURIs) { Path patternsPath = new Path(patternsURI.getPath()); String patternsFileName = patternsPath.getName().toString(); parseSkipFile(patternsFileName); } } } private void parseSkipFile(String fileName) { try { fis = new BufferedReader(new FileReader(fileName)); String pattern = null; while ((pattern = fis.readLine()) != null) { patternsToSkip.add(pattern); } } catch (IOException ioe) { System.err.println("Caught exception while parsing the cached file \'" + StringUtils.stringifyException(ioe)); } } @Override public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { String line = (caseSensitive) ? value.toString() : value.toString().toLowerCase(); for (String pattern : patternsToSkip) { line = line.replaceAll(pattern, ""); } StringTokenizer itr = new StringTokenizer(line); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); Counter counter = context.getCounter(CountersEnum.class.getName(), CountersEnum.INPUT_WORDS.toString()); counter.increment(1); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("yarn.resourcemanager.address", "192.168.56.101:8050"); conf.set("mapreduce.framework.name", "yarn"); conf.set("fs.defaultFS", "hdfs://vbusuanzi:9000/"); // conf.set("mapred.jar", "mapreduce/build/libs/mapreduce-0.1.jar"); // 也可以在这里设置刚刚编译好的jar conf.set("mapred.job.tracker", "vbusuanzi:9001"); // conf.set("mapreduce.app-submission.cross-platform", "true");// Windows开发者需要设置跨平台 args = new String[]{"/tmp/test/LICENSE.txt","/tmp/test/out30"}; GenericOptionsParser optionParser = new GenericOptionsParser(conf, args); String[] remainingArgs = optionParser.getRemainingArgs(); if ((remainingArgs.length != 2) && (remainingArgs.length != 4)) { System.err.println("Usage: wordcount <in> <out> [-skip skipPatternFile]"); System.exit(2); } Job job = Job.getInstance(conf,"test"); job.setJar("mapreduce/build/libs/mapreduce-0.1.jar"); job.setJarByClass(com.wc.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); List<String> otherArgs = new ArrayList<String>(); for (int i=0; i < remainingArgs.length; ++i) { if ("-skip".equals(remainingArgs[i])) { job.addCacheFile(new Path(remainingArgs[++i]).toUri()); job.getConfiguration().setBoolean("wordcount.skip.patterns", true); } else { otherArgs.add(remainingArgs[i]); } } FileInputFormat.addInputPath(job, new Path(otherArgs.get(0))); FileOutputFormat.setOutputPath(job, new Path(otherArgs.get(1))); job.waitForCompletion(true); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
以上是关于本地idea开发mapreduce程序提交到远程hadoop集群执行的主要内容,如果未能解决你的问题,请参考以下文章