hadoop生态系统介绍
Posted 谦谦君子,陌上其华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop生态系统介绍相关的知识,希望对你有一定的参考价值。
hadoop生态系统如下图所示:
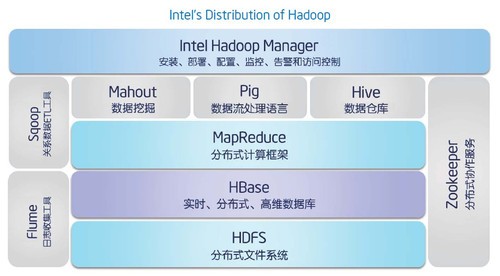
HDFS:
HDFS(Hadoop Distributed File System)是分布式文件系统,是针对谷歌开发的分布式文件系统GFS(Google File System)的开源实现,是Hadoop两大核心组成部分之一。
HDFS有NameNode和DataNode两部分,NameNode是整个文件系统目录,基于内存存储,存储的是一些文件的详细信息,比如文件名、文件大小、创建时间、文件位置等,有且仅有一个;DataNode存储文件的数据信息,也就是文件本身,不过是分割后的小文件。
HDFS是一种底层数据存储方式。Hive与Hbase的数据一般都存储在HDFS上,HDFS为他们提供高可靠性的底层存储支持。
HBase:
HBase是针对谷歌BigTable的开源实现,是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。需要注意的是,HBase可以使用本地文件系统而不用HDFS作为底层数据存储方式,不过为了提高数据可靠性和系统的健壮性,发挥HBase处理大数据量等功能,一般都使用HDFS作为HBase的底层数据存储方式。
HBase的运行建立在hadoop上,在hadoop生态系统中,HDFS为HBase提供了高可靠性的底层存储支持,MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS(关系型数据库)数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
HBase是一个开源的Not-Only-SQL的数据库,像其他数据库一样提供随即读写功能。HDFS最适于执行批次分析,而不能满足实时需要,HBase能够处理大规模数据,它不适于批次分析,但它可以向Hadoop实时地调用数据。如果需要实时访问一些数据,就把它存入HBase。
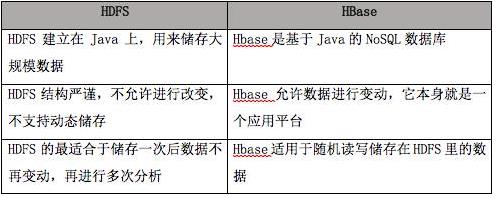
下面再以表格的形式对HDFS和HBase作一个比较:
以上是关于hadoop生态系统介绍的主要内容,如果未能解决你的问题,请参考以下文章