MySQL主从复制-GTID原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL主从复制-GTID原理相关的知识,希望对你有一定的参考价值。
一、mysql 主从复制原理阐述
Mysql主从复制:简单来说就是Mysql 同步,Ab 复制等,主从复制是单向的,只能从 Master 复制到 Slave 上,延时基本上是毫秒级别的(排除网络延迟等问题)。一组复制结构中可以有多个Slave,对于 Master一般场景推荐只有一个,【根据您的业务进行调配,主主复制、延迟复制等】
Mysql 传统复制是基于 Mysql 二进制文件(Mysql-Bin.000001),加上对应日志文件中每个事件的偏移量位置点(Postion)。
MySQL主从复制 三个线程来实现:
主库: Binlog Dump
从库: Io 和 Sql 线程
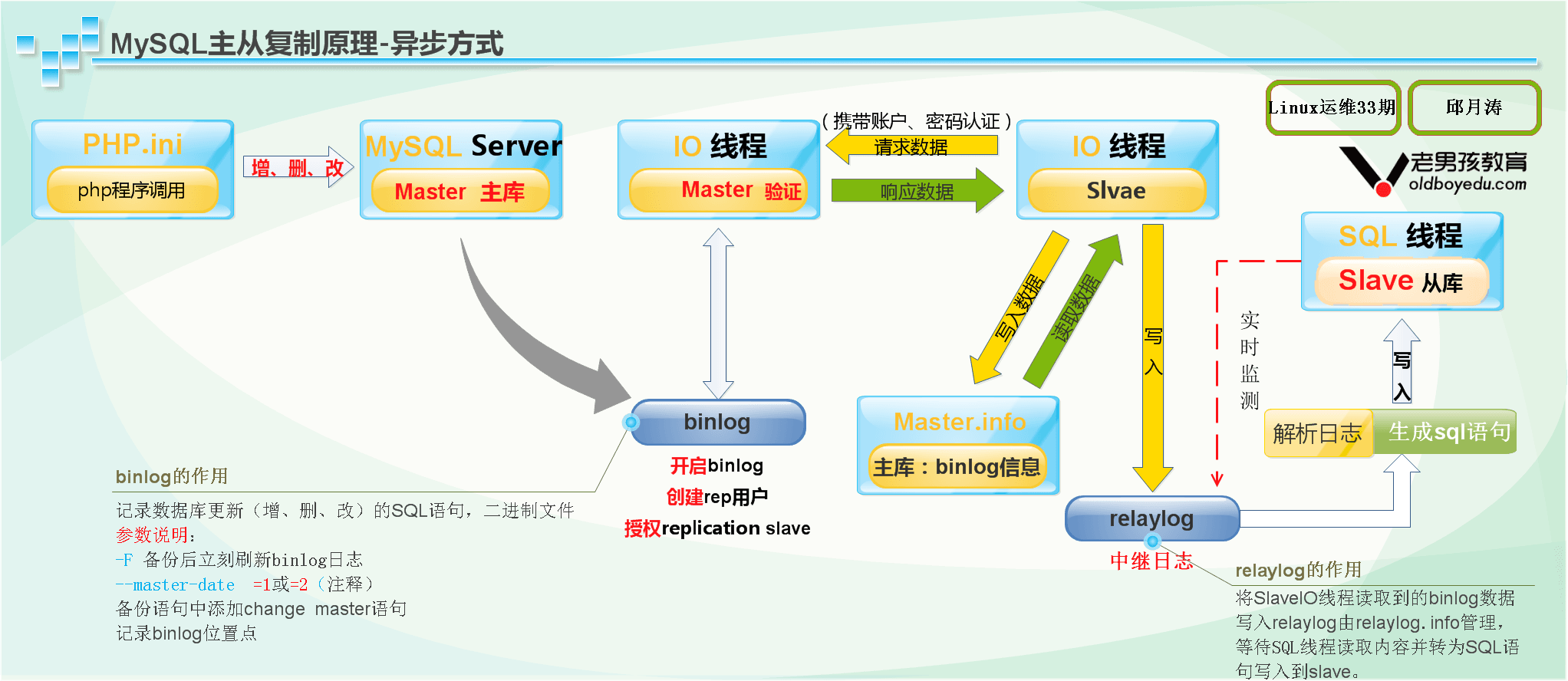
Mysql同步原理简述:
- Master 所有数据库变更写进 Binary Log, 主库线程 Binlog Dump 把 Binary Log 内容发送到从库 Slave 上(Slave 被动接受数据,不是主动去获取)。
- Slave Io 线程读取 Master 上 Binary Log 日志信息,把接受到的 Binary Log 日志写到本地中继日志 Relay Log
- Slave Sql 线程读取 Ralay Log 日志内容写入本地数据库实例
二、MySQL 异步复制架构中 GTID 复制的原理阐述
2.1 GTID 的概述:
1、全局事物标识:global transaction identifieds。
2、GTID 事物是全局唯一性的,且一个事务对应一个 GTID。
3、一个 GTID 在一个服务器上只执行一次,避免重复执行导致数据混乱或者主从不一致。
4、GTID 用来代替classic的复制方法,不在使用 binlog+pos 开启复制。而是使用 master_auto_postion=1 的方式自动匹配 GTID 断点进行复制。
5、MySQL-5.6.5 开始支持的,MySQL-5.6.10 后开始完善。
6、在传统的 slave 端,binlog 是不用开启的,但是在 GTID 中,slave 端的 binlog 是必须开启的,目的是记录执行过的 GTID(强制);但是从 5.7.5 版本开始无需在 GTID 模式下启用参数 log_slave_updates
2.2 GTID 的组成部分:
-
GTID = source_id:transaction_id
-
source_id 正常即是
server_uuid,在第一次启动时生成(函数 generate_server_uuid),并持久化到 DATADIR/auto.cnf 文件里。 -
transaction_id 是
顺序化的序列号(sequence number),在每台 MySQL 服务器上都是从 1 开始自增长的序列,是事务的唯一标识。例如:3E11FA47-71CA-11E1-9E33-C80AA9429562:23 -
GTID 的集合(GTIDs)可以用 source_id+transaction_id 范围表示,例如:3E11FA47-71CA-11E1-9E33-C80AA9429562:1-18
- 复杂一点的:如果这组 GTIDs 来自不同的 source_id,各组 source_id 之间用逗号分隔;如果事务序号有多个范围区间,各组范围之间用冒号分隔,例如:3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5:11-18,2C256447-3F0D-431B-9A12-575BB20C1507:1-27
2.3 GTID 如何产生
-
GTID 的生成受
gtid_next控制。 -
在 Master 上,gtid_next 是默认的 AUTOMATIC,即 GTID 在每次事务提交时
自动生成。它从当前已执行的 GTID 集合(即 gtid_executed)中,找一个大于 0 的未使用的最小值作为下个事务 GTID。同时将 GTID 写入到 binlog(set gtid_next 记录),在实际的更新事务记录之前。 - 在 Slave 上,从 binlog 先读取到主库的 GTID(即 set gtid_next 记录),而后执行的事务采用该 GTID。
2.4 GTID 相关的变量
GTID_EXECUTED
#表示已经在该实例上执行过的事务; 执行 RESET MASTER 会将该变量置空; 我们还可以通过设置 GTID_NEXT 在执行一个空事务,来影响 GTID_EXECUTED
GTID_PURGED
#已经被删除了 binlog 的事务,它是 GTID_EXECUTED 的子集,只有在 GTID_EXECUTED 为空时才能设置该变量,修改 GTID_PURGED 会同时更新 GTID_EXECUTED 和 GTID_PURGED 的值。
GTID_OWNED
#表示正在执行的事务的 gtid 以及对应的线程 ID。
GTID_NEXT
#SESSION 级别变量,表示下一个将被使用的 GTID。2.5 GTID 比传统复制的优势与限制:
GTID优势
更简单的实现 failover,不用以前那样在需要找 log_file 和 log_Pos。
更简单的搭建主从复制。
复制集群有一个统一的方式识别复制位置,给集群管理带来了便利。
正常情况下,GTID 是连续没有空洞的,因此主从库出现数据冲突时,可以用添加空事物的方式进行跳过。GTID的限制:
1、在一个事务里面混合使用引擎,如 Innodb(支持事务)、MyISAM(不支持事务), 造成多个 GTIDs 和同一个事务相关联出错
2、CREATE TABLE…..SELECT 不能使用,该语句产生的两个 event 在某一情况 会使用同一个 GTID(同一个 GTID 在 slave 只能被使用一次)
1th event:创建表语句 create table
2th event:插入数据语句 insert
3、CREATE TEMPORARY TABLE and DROP TEMPORARY TABLE 不能在事务内使用 (启用了–enforce-gtid-consistency 参数)。三、GTID 的工作原理:
master 更新数据时,会在事务前产生 GTID,`一同记录到 binlog 日志中`。
slave 端的 i/o 线程将变更的 binlog,写入到本地的 relay log 中,读取值是根据`gitd_next变量`,告诉我们slave下一个执行哪个GTID。
sql 线程从 relay log 中获取 GTID,然后对比 slave 端的 binlog 是否有记录。
如果有记录,说明该 GTID 的事务已经执行,slave 会忽略。
如果没有记录,slave 就会从 relay log 中执行该 GTID 的事务,并记录到 binlog。
在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有二级索引就用全部扫描。3.1 pos 与 GTID 有什么区别?
两者都是日志文件里事件的一个标志,如果将整个 mysql 集群看作一个整体,pos就是局部的,GTID就是全局的.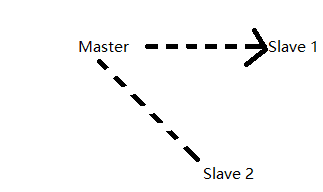
上图就是一个 mysql 节点的集群,一主两从,在 master,slave1,slave2 日志文件里的 pos,都各不相同,就是一个 event,在 master 的日志里,pos 可能是 700,而在 slave1,slave2 里,pos 可能就是 300,400 了,因为众多 slave 也可能不是同时加入集群的,不是从同一个位置进行同步.
而 GTID,在 master,slave1,slave2 各自的日志文件里,同一个 event 的 GTID 值都是一样的.
3.2 为什么要有这个区分呢?
大家都知道,这整个集群架构的节点,通常情况下,是 master 在工作,其他两个结点做备份,而且,各个节点的机器,性能不可能完全一致,所以,在做备份时,备份的速度就不一样,当 master 突然宕掉之后,马上会启用从节点机器,接管 master 的工作,当有多个从节点时,选择备份日志文件最接近 master 的那个节点;
现在就出现情况了,当 salve1 变成主节点,那slave2就应该从 slave1 去获取日志文件,进行同步.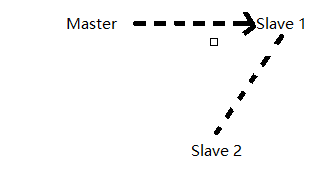
大家来想想这个问题
如果使用的是pos,三者的pos不一致,slave2 怎么去获取它当前要同步的事件在 slave1 里的 pos 呢?????????
所以就有了GTID全局的,将所有节点对于同一个 event 的标记完全一致,当 master 宕掉之后,slave2 根据同一个 GTID 直接去读取 slave1 的日志文件,继续同步.
四、MySQL经典主从配置实战
4.1 核心配置 my.cnf
[mysqld]
log-bin
server-id
gtid_mode=off #禁掉 gtid4.2 添加主从复制用户
grant replication slave on *.* to ‘repl‘@‘%‘ identified by ‘qiuyuetao‘;
flush privileges;
4.3 添加一个新的从库
获取主库上一个带 binlog 及 pos 偏移量的备份
在从库上恢复后
>change master to
master_host=‘192.168.199.117‘,
master_user=‘slave‘,
master_port=7000,
master_password=‘slavepass‘,
master_log_file=‘mysql-bin.000008‘,
master_log_pos=896;
>start slave;
>show slave statusG;跳过复制错误
stop slave;
set global sql_slave_skip_counter=1;
start slave;
show slave statusG;如果出现错误代码,那么一般错误,可以跳过,具体哪些错误代码可以跳,哪些不能调,后续我会在专门写一篇文章。
五、GTID 配置
所有节点上都要进行设置
vim /etc/my.cnf
[mysqld]
#GTID:
gtid_mode=on #开启 GTID
enforce-gtid-consistency=on
#binlog
log-bin=mysql-bin #开启二进制文件系统
server-id=1 #必须为 1-231 之间的一个正整数值,各个值节点不能一致
log-slave-updates=1 # 5.7.5 版本开始无需在 GTID 模式下启用参数 log_slave_updates在从节点上 mysql 设置:
mysql>change master to master_host=‘xxxxxxx‘,master_user=‘xxxxxx‘,master_password=‘xxxxx‘,MASTER_AUTO_POSITION=1;
mysql> start slave;
mysql> stop slave io_thread; #重启 io 线程,刷新状态
mysql> start slave io_thread;注意事项:
master_host,master_user,master_password与经典的Mysql主从复制一致。
唯一不一致的是使用了 MASTER_AUTO_POSITION 参数
当使用 MASTER_AUTO_POSITION 参数的时候,MASTER_LOG_FILE,MASTER_LOG_POS 参数不能使用
如果想要从 GTID 配置回 pos,再次执行这条语句,不过把 MASTER_AUTO_POSITION 置为 0
GTID添加从库有两种方法:
1.如果 master 所有的 binlog 还在,安装 slave 后,直接 change master 到 master
原理: 直接获取 master 所有的 gtid 并执行
优点: 简单
缺点: 如果 binlog 太多,数据完全同步需要的时间较长,并且需要 master 一开始就启用了 GTID
总结:适用于 master 也是新建不久的情况2.通过 master 或者其它 slave 的备份搭建新的 slave.
原理:获取 master 的数据和这些数据对应的 GTID 范围,然后通过在 slave 设置@@GLOBAL.GTID_PURGED 从而跳过备份包含的 GTID
优点: 可以避免第一种方法中的不足
缺点: 操作相对复杂
总结:适用于拥有较大数据集的情况GTID 添加从库:
1、mysqldump
在备份的时候需要指定–master-data
导出的语句中包括:
set @@GLOBAL.GTID_PURGED=’c8d960f1-83ca-11e5-a8eb-000c29ea831c:1-745497′;
#恢复时,需要先在slave上执行一个
reset master;
#再执行
change master to2、percona xtrabackup
xtrabackup_binlog_info 包含了 GTID 在信息
做从库恢复后,需要手工设置:
[email protected]@GLOBAL.GTID_PURGED=‘c8d960f1-83ca-11e5-a8eb-000c29ea831c:1-745497‘;恢复后,执行 change master to
>change master to
master_host=‘192.168.199.117‘,
master_user=‘slave‘,
master_port=7000,
master_password=‘slavepass‘,
master_auto_position=1;错误跳过
stop slave;
set gtid_next=‘xxxxxxxx:N‘;
begin;
commit;
set gtid_next=‘automatic‘;
start slave;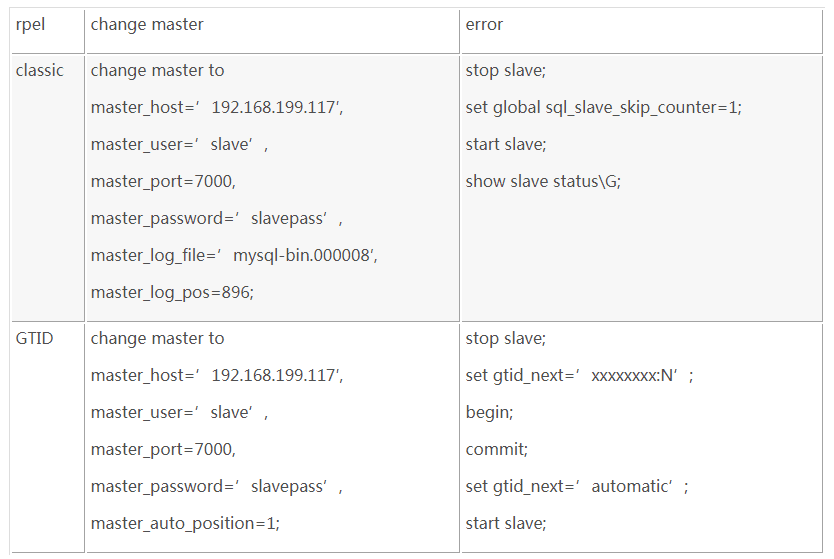
GTID的限制总结:
不支持非事务引擎(从库报错,stop slave; start slave; 忽略)
不支持 create table … select 语句复制(主库直接报错)
不允许在一个 SQL 同时更新一个事务引擎和非事务引擎的表
在一个复制组中,必须要求统一开启CTID或是关闭GTID
开启DTID需要重启(5.7中可能不需要)
开启DTID后,就不在使用原来的传统的复制方式
对于create temporary table 和drop temporary table语句不支持
不支持sql_slave_skip_counter
六、MySQL半同步复制
MySQL 复制默认是异步复制,Master 将事件写入 binlog,但并不知道 Slave 是否或何时已经接收且已处理。在异步复制的机制的情况下,如果 Master 宕机,事务在 Master 上已提交,但很可能这些事务没有传到任何的 Slave 上。假设有 Master->Salve 故障转移的机制,此时 Slave 也可能会丢失事务。
官方半同步复制的概念:
1.当 Slave 主机连接到 Master 时,能够查看其是否处于半同步复制的机制。
2.当 Master 上开启半同步复制的功能时,至少应该有一个 Slave 开启其功能。此时,一个线程在 Master 上提交事务将受到阻塞,直到得知一个已开启半同步复制功能的 Slave 已收到此事务的所有事件,或等待超时。
3.当一个事务的事件都已写入其 relay-log 中且已刷新到磁盘上,Slave 才会告知已收到。
4.如果等待超时,也就是 Master 没被告知已收到,此时 Master 会自动转换为异步复制的机制。当至少一个半同步的 Slave 赶上了,Master 与其 Slave 自动转换为半同步复制的机制。
5.半同步复制的功能要在 Master,Slave 都开启,半同步复制才会起作用;否则,只开启一边,它依然为异步复制。
同步(社区增强半同步),异步,半同步复制的比较:
同步复制:Master 提交事务,直到事务在所有的 Slave 都已提交,此时才会返回客户端,事务执行完毕。缺点:完成一个事务可能会有很大的延迟。
异步复制:当 Slave 准备好才会向 Master 请求 binlog。
缺点:不能保证一些事件都能够被所有的 Slave 所接收。
半同步复制:半同步复制工作的机制处于同步和异步之间,Master 的事务提交阻塞,只要一个 Slave 已收到该事务的事件且已记录。它不会等待所有的 Slave 都告知已收到,且它只是接收,并不用等其完全执行且提交。
解决主库不关心日志是否被从库读到
半同步,开启后严重影响性能
半同步配置,在master和slave上都配置
master
[mysqld]
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=1000 #1s
slave
[mysqld]
rpl_semi_sync_slave_enabled=1 复制参数以上是关于MySQL主从复制-GTID原理的主要内容,如果未能解决你的问题,请参考以下文章