MYSQL:随机抽取一条数据库记录
Posted 佳佳嘉佳佳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MYSQL:随机抽取一条数据库记录相关的知识,希望对你有一定的参考价值。
今天我们要实现从随机抽取一条数据库记录的功能,并且抽取出来的数据记录不能重复;
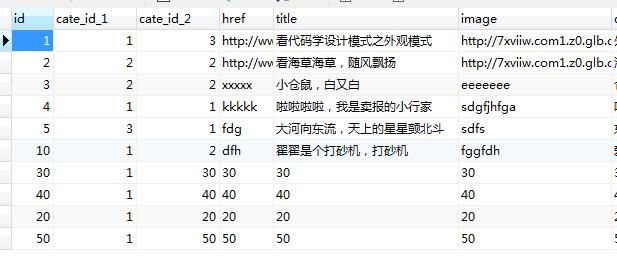
1、首先我们看文章表中的数据:
2、实现功能代码如下:
1 /** 2 * 获取随机的N篇文篇 3 * @param int $len 文章篇数 4 */ 5 public static function getRandom($len = 6) { 6 # 查询数据库,得到最小Id 7 # SELECT min(id) FROM mimi_aritcle 8 $min = Db::name(self::$tb)->field(\'min(id)\')->select(); 9 $min = $min[0][\'min(id)\']; 10 11 # 查询数据库,得到最大id 12 # SELECT max(id) FROM mimi_article 13 $max = Db::name(self::$tb)->field(\'max(id)\')->select(); 14 $max = $max[0][\'max(id)\']; 15 16 # 初始化存储数据 17 $result = []; 18 # 初始化id数组 19 $randId_arr = []; 20 21 for ($i = 1; $i <= $len; $i++) { 22 # 先设重复提取记录为false,进入do循环 23 $is_repeat_2 = false; 24 25 # do..while,即使条件不成立,循环起码执行一次 26 do { 27 do { 28 # 产生一个随机整数 29 # 注意:产生的整数与数据库无关,不要因为两个参数是从数据库中得到的, 30 # 就误以为是在产生数据库中的随机id 31 $randId = rand($min, $max); 32 33 # 判断是否有重复提取的记录 34 $is_repeat = in_array($randId, $randId_arr); 35 } while ($is_repeat); 36 37 if($is_repeat_2){ 38 # 将提取出的不同id进行入栈 39 array_push($randId_arr, $row[0][\'id\']); 40 } 41 42 # 抽取一条数据库记录 43 /** 44 * 首先,我们要记住: 45 * 步骤一表图中查询数据库,获取到最小id是1, 最大id是50,就能知道数据库中一定有id=1和id=50的记录 46 * 所以, 47 * 1、这里使用id>$randId而不是id=$randId,是防止数据库中的某条记录被删除,导致找不到数据库中对应的id记录; 48 * 例子: 49 * (1) 如果随机抽取的$randId为6,那么使用条件id>$randId-1的话,就会读取到数据库中所有id>5的记录; 50 * 从数据库截图中,我们可以看到,能够读取到数据库id=10、20、30、40、50的记录 51 * (2) 如果我们使用id=$randId,随机抽取的$randId为6,那么使用功能id=$randId的话,就会读取到数据库中id=6的固定记录, 52 * 但是数据库中没有id=6的记录,就会发生错误 53 * 54 * 2、这里使用id>$randId-1而不是id>$randId,是为了防止我们随机抽取的数为最大数50的时候,条件不成立, 55 * 从而导致报错,因为id=50是数据库中最大数了 56 * 例如: 57 * (1) 如果随机抽取的$randId为最大数50,那么使用条件id>$randId-1的话,就会读取到数据库中所有id>49的记录, 58 * 由于符合id>49条件的只有id=50的记录,那么就能保证,我有数据可以提取到; 59 * (2) 如果随机抽取的$randId为最大数50,那么使用条件id>$randId的话,就会读取到数据库中所有id>50的记录, 60 * 但是数据库中没有符合条件的数据,就会发生错误 61 * (3) 如果随机抽取的$randId为最小数1,使用条件 id>$randId 的话,id = 1 的记录永远也不能被随机选中 62 * 63 * 3、这里使用order(\'id ASC\')而不是order(\'id DESC\')原因:当我们获取到数据后,要获取最接近$randId的值 64 * (1) 如果随机抽取的$randId为6,我们就能从所有id>5的记录,即id=10、20、30、40、50 65 * 的记录,这时候的结果是循环6次后的总体列表,那我们需要最靠近6的记录,就需要使用order(\'id ASC\') 66 * 进行升序排列,这时候,列表中的第一个数据就是id=10的,就是我们想要的记录 67 * (2) 如果随机抽取的$randId为6,我们就能从所有id>5的记录,即id=10、20、30、40、50 68 * 的记录,如果使用order(\'id DESC\'),那么我们得到的数据永远是最不靠近6的记录,即id=50的记录 69 * (3) 不使用order,有时候会排列不一样,(通常在数据记录不同时才会发现到) 70 * 71 * 4、这里使用limit原因:因为我们需要的是一条记录,而不是一个列表,所以,我们只需要提取符合条件的第一条记录即可 72 * 例子: 73 * (1) 如果随机抽取的$randId为6,那么使用条件id>$randId-1的话,就会读取到数据库中所有id>5的记录而不是固定一条记录; 74 * 从数据库截图中,我们可以看到,能够读取到数据库id=10、20、30、40、50的记录,但是我们循环一次只需要一条记录,那么 75 * 只需要提取第一条符合的记录,就是id=10的记录 76 * (2) 如果我们不使用limit的话,那么系统就会把所有符合条件的记录都提取出来 77 * 78 */ 79 $row = Db::name(self::$tb) 80 ->field(\'id, title, href\') 81 ->where([\'id\' => [\'>\', $randId - 1]]) 82 ->order(\'id ASC\') 83 ->limit(0, 1) 84 ->select(); 85 86 # 判断是否有重复提取的数据库记录 87 $is_repeat_2 = in_array($row[0][\'id\'], $randId_arr); 88 } while ($is_repeat_2); 89 90 91 # 将提取出来的数据库id进行入栈 92 array_push($randId_arr, $row[0][\'id\']); 93 94 if(empty($row)){ 95 return false; 96 } 97 98 # 将提取出的所有最终数据库数据入栈 99 array_push($result, $row[0]); 100 } 101 102 return $result; 103 }
以上
加油ヾ(◍°∇°◍)ノ゙
以上是关于MYSQL:随机抽取一条数据库记录的主要内容,如果未能解决你的问题,请参考以下文章