Redis源码剖析--对象系统
Posted 我也要当大佬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis源码剖析--对象系统相关的知识,希望对你有一定的参考价值。
对象的类型与编码
在 Redis 中新创建一个键值对时, 我们至少会创建两个对象, 一个对象用作键值对的键(键对象), 另一个对象用作键值对的值(值对象)。Redis 中的每个对象都由一个 redisObject 结构表示:
typedef struct redisObject { // 类型 unsigned type:4; // 编码 unsigned encoding:4; // 对象最后一次被访问的时间 unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ // 引用计数 int refcount; // 指向实际值的指针 void *ptr; } robj;
对象类型
对象的type属性记录了对象的类型,type属性的值有以下几种:
|
类型 |
对象名称 |
|
REDIS_STRING |
字符串对象 |
|
REDIS_LIST |
列表对象 |
|
REDIS_HASH |
哈希对象 |
|
REDIS_SET |
集合对象 |
|
REDIS_ZSET |
有序集合对象 |
编码与底层实现
对象的encoding属性记录了对象使用的编码,即底层使用的数据结构,encoding的值有以下几种:
|
编码常量 |
底层数据结构 |
|
REDIS_ENCODING_INT |
|
|
REDIS_ENCODING_EMBSTR |
|
|
REDIS_ENCODING_RAW |
简单动态字符串 |
|
REDIS_ENCODING_HT |
字典 |
|
REDIS_ENCODING_LINKEDLIST |
双端链表 |
|
REDIS_ENCODING_ZIPLIST |
压缩列表 |
|
REDIS_ENCODING_INTSET |
整数集合 |
|
REDIS_ENCODING_SKIPLIST |
跳跃表 |
字符串对象
值对象编码
字符串对象的编码可以是 int 、 raw 或者 embstr。
如果字符串对象保存的是整数值, 那么这个整数值保存在 ptr属性(将 void* 转换成 long ) ,对象编码为int
如果字符串对象保存的是字符串值, 并且字符串长度大于 39 字节, 那么该字符串值使用简单动态字符串(SDS)来保存, 对象编码为 raw 。

如果字符串对象保存的字符串值, 并且字符串长度小于等于 39 字节, 那么字符串对象将使用 embstr 编码来保存字符串值。

字符串对象编码的部分代码如下:
robj *tryObjectEncoding(robj *o) { long value; sds s = o->ptr; size_t len; // 对字符串进行检查 // 只对长度小于或等于 21 字节,并且可以被解释为整数的字符串进行编码 len = sdslen(s); if (len <= 21 && string2l(s,len,&value)) { ......
o->ptr = (void*) value;
.......
} // 尝试将 RAW 编码的字符串编码为 EMBSTR 编码,#define REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39 if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT) { ...... } // 这个对象没办法进行编码,尝试从 SDS 中移除所有空余空间 if (o->encoding == REDIS_ENCODING_RAW && sdsavail(s) > len/10) { o->ptr = sdsRemoveFreeSpace(o->ptr); } return o; }
EMBSTR编码时,直接申请一段连续的空间,空间中依次包含 redisObject 和 sdshdr 两个结构:
robj *createEmbeddedStringObject(char *ptr, size_t len) { robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr)+len+1); ...... return o; }
编码的转换
当我们对 embstr 编码的字符串对象执行任何修改命令时, 程序会先将对象的编码从 embstr 转换成 raw , 然后再执行修改命令。下面给出APPEND命令部分代码:
void appendCommand(redisClient *c) { size_t totlen; robj *o, *append; // 取出键相应的值对象 o = lookupKeyWrite(c->db,c->argv[1]); // 检查追加操作之后,字符串的长度是否符合 Redis 的限制 append = c->argv[2]; totlen = stringObjectLen(o)+sdslen(append->ptr); if (checkStringLength(c,totlen) != REDIS_OK) return; // 执行追加操作,此处会进行编码的转换 o = dbUnshareStringValue(c->db,c->argv[1],o); o->ptr = sdscatlen(o->ptr,append->ptr,sdslen(append->ptr)); totlen = sdslen(o->ptr); }
dbUnshareStringValue函数实现:
robj *dbUnshareStringValue(redisDb *db, robj *key, robj *o) { redisAssert(o->type == REDIS_STRING); if (o->refcount != 1 || o->encoding != REDIS_ENCODING_RAW) { robj *decoded = getDecodedObject(o); //创建raw编码对象 o = createRawStringObject(decoded->ptr, sdslen(decoded->ptr)); decrRefCount(decoded); dbOverwrite(db,key,o); } return o; }
列表对象
编码转换
列表对象的编码可以是 ziplist 或者 linkedlist。
列表对象使用 ziplist 编码:
- 列表对象保存的所有字符串元素的长度都小于
64字节; - 列表对象保存的元素数量小于
512个;
不能满足这两个条件的列表对象需要使用 linkedlist 编码。以上两个条件的上限值可以通过配置文件中的list-max-ziplist-value 和 list-max-ziplist-entries 选项进行修改。
ziplist编码的列表对象:

linkedlist编码的列表对象:

编码转换的部分代码如下:
void listTypeTryConversion(robj *subject, robj *value) {if (sdsEncodedObject(value) && // 看字符串是否过长 sdslen(value->ptr) > server.list_max_ziplist_value) // 将编码转换为双端链表 listTypeConvert(subject,REDIS_ENCODING_LINKEDLIST); } // PUSH操作 void listTypePush(robj *subject, robj *value, int where) { // 是否需要转换编码? listTypeTryConversion(subject,value); if (subject->encoding == REDIS_ENCODING_ZIPLIST && ziplistLen(subject->ptr) >= server.list_max_ziplist_entries) listTypeConvert(subject,REDIS_ENCODING_LINKEDLIST); // ZIPLIST if (subject->encoding == REDIS_ENCODING_ZIPLIST) { int pos = (where == REDIS_HEAD) ? ZIPLIST_HEAD : ZIPLIST_TAIL; // 取出对象的值,因为 ZIPLIST 只能保存字符串或整数 value = getDecodedObject(value); subject->ptr = ziplistPush(subject->ptr,value->ptr,sdslen(value->ptr),pos); decrRefCount(value); // 双端链表 } else if (subject->encoding == REDIS_ENCODING_LINKEDLIST) { if (where == REDIS_HEAD) { listAddNodeHead(subject->ptr,value); } else { listAddNodeTail(subject->ptr,value); } incrRefCount(value); // 未知编码 } else { redisPanic("Unknown list encoding"); } }
阻塞行为
待填坑
哈希对象
哈希对象的编码可以是 ziplist 或者 hashtable 。
当哈希对象可以同时满足以下两个条件时, 哈希对象使用 ziplist 编码:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于
64字节; - 哈希对象保存的键值对数量小于
512个;
不能满足这两个条件的哈希对象需要使用 hashtable 编码。以上两个条件的上限值可以通过配置文件中的 hash-max-ziplist-value 和 hash-max-ziplist-entries 选项进行修改。
ziplist编码的哈希对象:

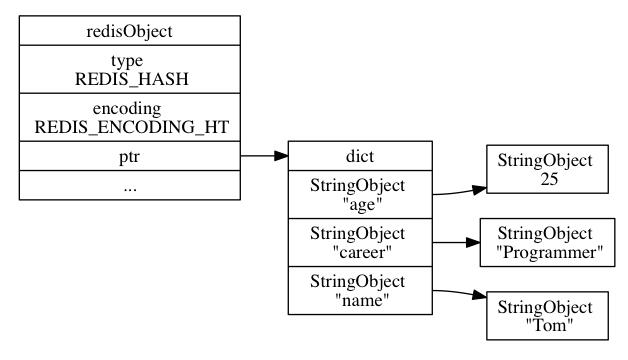
另一方面, hashtable 编码的哈希对象使用字典作为底层实现, 哈希对象中的每个键值对都使用一个字典键值对来保存:
- 字典的每个键都是一个字符串对象;
- 字典的每个值都是一个字符串对象。
hashtable编码的哈希对象:
集合对象
集合对象的编码可以是 intset 或者 hashtable 。
当集合对象可以同时满足以下两个条件时, 对象使用 intset 编码:
- 集合对象保存的所有元素都是整数值;
- 集合对象保存的元素数量不超过
512个;
不能满足这两个条件的集合对象需要使用 hashtable 编码。元素数量的上限值是可以通过配置文件 set-max-intset-entries 选项进行修改。
intset编码的集合对象:

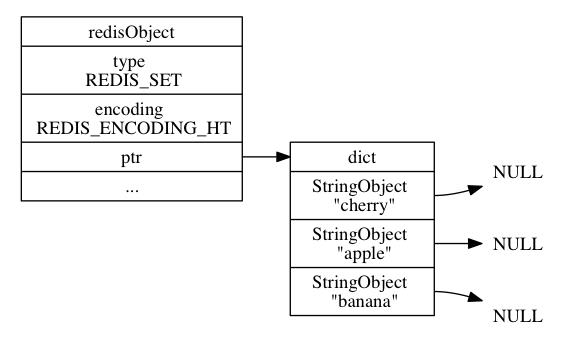
hashtable编码的集合对象
有序集合对象
有序集合的编码可以是 ziplist 或者 skiplist 。
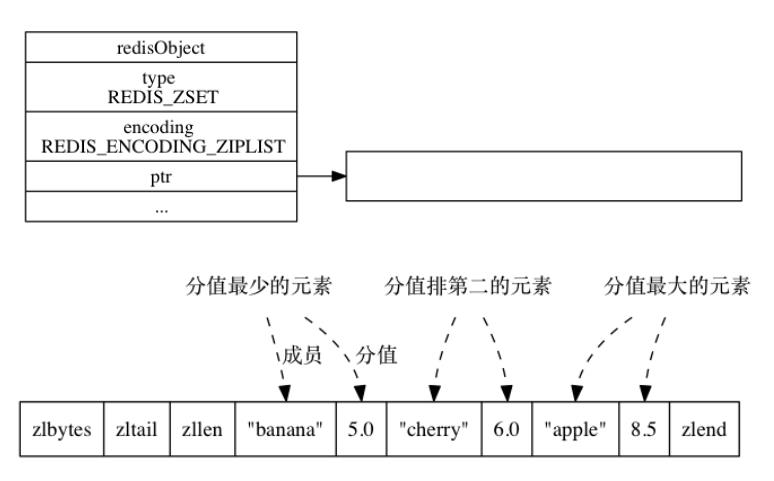
当使用ziplist编码作为有序集合对象底层实现时,每个集合元素使用两个压缩列表节点来保存, 第一个节点保存元素的成员(member), 而第二个元素则保存元素的分值(score)。压缩列表内的集合元素按分值从小到大进行排序。
ziplist编码的有序集合对象如下:
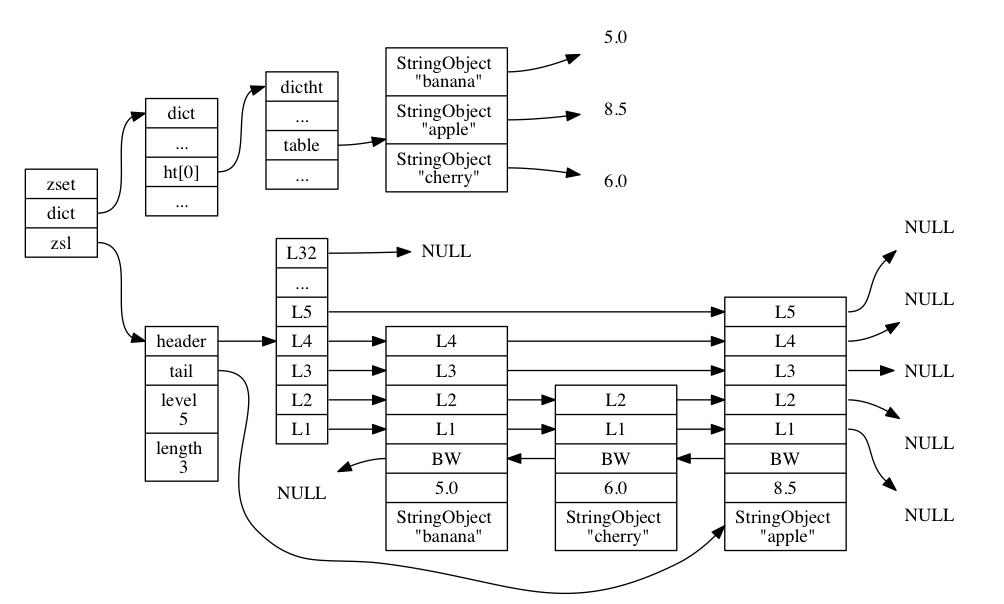
skiplist 编码的有序集合对象使用 zset 结构作为底层实现:
typedef struct zset { zskiplist *zsl; dict *dict; } zset;
zset 结构中的 zsl 跳跃表按分值从小到大保存了所有集合元素: 跳跃表节点的 object 属性保存了元素的成员, score 属性则保存了元素的分值。 ZRANK、 ZRANGE 等命令就是基于跳跃表 API 来实现的。
除此之外, zset 结构中的 dict 字典为有序集合创建了一个从成员到分值的映射: 字典的键保存了元素的成员, 而字典的值则保存了元素的分值。 通过字典, 可以用 O(1) 复杂度查找给定成员的分值。
skiplist编码的有序集合对象如下:
这两种数据结构都会通过指针来共享相同元素的成员和分值,不会因此而浪费额外的内存。
内存回收
Redis 使用引用计数技术实现的内存回收机制。引用计数信息由 redisObject 结构的 refcount 属性记录。
以list的PUSH操作为例:
void listTypePush(robj *subject, robj *value, int where) { ...... // ZIPLIST if (subject->encoding == REDIS_ENCODING_ZIPLIST) { ...... decrRefCount(value); // 双端链表 } else if (subject->encoding == REDIS_ENCODING_LINKEDLIST) { ...... incrRefCount(value); } }
incrRefCount的实现,当引用计数为0时会释放对象内存:
void decrRefCount(robj *o) { if (o->refcount <= 0) redisPanic("decrRefCount against refcount <= 0"); // 释放对象 if (o->refcount == 1) { switch(o->type) { case REDIS_STRING: freeStringObject(o); break; case REDIS_LIST: freeListObject(o); break; case REDIS_SET: freeSetObject(o); break; case REDIS_ZSET: freeZsetObject(o); break; case REDIS_HASH: freeHashObject(o); break; default: redisPanic("Unknown object type"); break; } zfree(o); // 减少计数 } else { o->refcount--; } }
对象的空转时长
redisObject 结构中的 lru 属性记录了对象最后一次被命令程序访问的时间。可以通过OBJECT IDLETIME 命令可以打印出给定键的空转时长。
除了可以被 OBJECT IDLETIME 命令打印出来之外, 键的空转时长还有另外一项作用: 如果服务器打开了 maxmemory 选项, 并且服务器用于回收内存的算法为 volatile-lru 或者 allkeys-lru , 那么当服务器占用的内存数超过了 maxmemory 选项所设置的上限值时, 空转时长较高的那部分键会优先被服务器释放, 从而回收内存。
以上是关于Redis源码剖析--对象系统的主要内容,如果未能解决你的问题,请参考以下文章