大数据生态之 ——HDFS
Posted 力扛九鼎
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据生态之 ——HDFS相关的知识,希望对你有一定的参考价值。
大数据生态之-----HDFS
HDFS工作机制
客户端上传文件时,一方面由datanode存储文件内容,另一方面有namenode负责管理block信息(切块大小,副本数量,位于datanode上的位置信息)
一丶namenode的工作职责:
- 记录元数据
a) 文件的路径
b) 文件的副本数量
c) 文件切块大小
d) block块信息
e) block块的位置信息
2. 响应客户端请求
3. 平衡datanode上block文件块的存储负载
datanode启动后会向namenode汇报自身所持有的block文件块的相关信息,客户端上传文件时,namenode会优先分配剩余空间较多的datanode供客户端使用。当有新的datanode节点加入集群时,namenode也会通知旧的datanode节点转移自身一部分block块到新的datanode上
二丶namenode元数据管理机制:
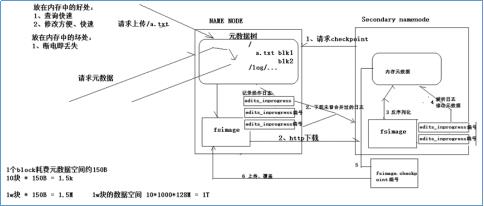
- namenode上完整的元数据存储在内存中
- 内存中的元数据也会序列化到磁盘上生成fsimage文件,整个生命周期中只序列化一次
- namenode会对引起元数据变化的客户端操作进行日志记录
- secondarynamenode定期从namenode上下载编号较新的日志,将fsimage反序列化以后和解析的日志进行合并,合并完成后生成一个新的fsimage并上传到namenode上覆盖掉原来的fsimage文件
- 这样就保证了namenode上的fsimage文件一直处于一个较新的状态,而且namenode上的日志文件数量也处于一个可控范围之内。
三丶datanode的工作职责
1. 接收客户端上传的block块
2. 帮助客户端获取指定的block块
3. 定期向namenode汇报自身所持有的block信息
四丶文件读写流程
4.1写文件流程
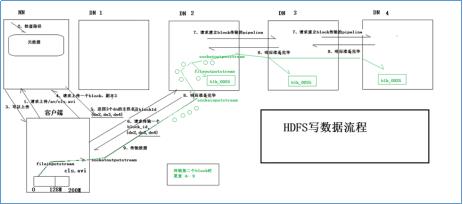
- 客户端向namenode发送文件上传请求(携带文件名和路径信息)
- namenode接收到客户端请求以后会从查询元数据中进行查询
- 如果文件不存在namenode会向客户端返回允许上传响应
- 客户端接收到namenode允许上传响应后会发送上传的block块信息,比如需要上传一个block,存储3个副本
- namenode接收到请求以后会从集群中随机挑选三台可用的datanode并其地址将blockid一起发送给client
- 客户端接收到namenode响应后会选取最近的那台datanode发送block块上传请求和存储该block块的三台datanode的地址信息
- 第一台datanode接收到请求以后会向第二台datanode发送建立block传输pipeline请求,第二台datanode会向第三台datanode发送建立block传输pipeline请求
- 第三台datanode准备完毕后会向第二台datanode发送准备就绪响应,第二台datanode准备完毕后会向第一台datanode发送准备就绪响应,此时三台datanode都以做好准备等待接收block块,第一台datanode会向客户端发送允许上传响应
- 客户端接收到datanode发送的允许上传响应后会利用FileInputStream读取文件并利用SocketOuputStream将文件发送给第一台datanode,该datanode使用SocketInputStream接收数据的同时会通过block pipeline将数据发送到下一台datanode上,三台datanode几乎会同时完成block的接收工作。
- 后续block块的发送重复4-9步骤
4.2读文件流程
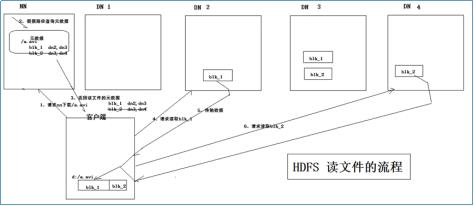
- Client向name发送文件下载请求(含文件名和HDFS上存储的路径信息)
- namenode从元数据中进行查找并将block所在的datanode地址响应给Client
- 客户端接收到block块位置信息后,会选择距离最近的datanode发送block读取请求,
- datanode接收到client发送的block读取请求以后会将数据发送给client
client接收到datanode发送的数据以后会存储到本地磁盘并继续请求下一个block块并根据偏移量与第一块接收到的block块文件进行合并,最终获取完整文件。
以上是关于大数据生态之 ——HDFS的主要内容,如果未能解决你的问题,请参考以下文章