大数据-Hadoop生态-Hadoop集群搭建
Posted duoduotouhenying
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据-Hadoop生态-Hadoop集群搭建相关的知识,希望对你有一定的参考价值。
准备工作
开启全部三台虚拟机,确保hadoop100的机器已经配置完成
脚本
操作hadoop100
新建一个xsync的脚本文件,将下面的脚本复制进去
vim xsync
#这个脚本使用的是rsync命令而不是scp命令,是同步而非覆盖文件,所以仅仅会同步过去修改的文件.但是rsync并不是一个原生的Linux命令,需要手动安装.如果没有,请自行安装
#!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if ((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取当前用户名称 user=`whoami` #5 循环
# 101, 103 是机器的ip地址,大家可以根据情况修改 for((host=101; host<103; host++)); do echo ------------------- hadoop$host -------------- rsync -av $pdir/$fname [email protected]$host:$pdir done
给xsync文件加可执行权限
chmod +x xsync
将xsync拷贝到 /bin 目录下,以后可以随处使用
sudo cp xsync /bin
运行以下命令,根据提示输入密码,将文件进行拷贝(拷贝前,如果hadoop100的hadoop目录里有 data和logs文件 务必删除掉再同步)
sudo xsync /opt/module/hadoop-2.7.2/ sudo xsync /opt/module/jdk1.8.0_144/
sudo xsync /etc/profile
再在全局会话中,使用source命令
source /etc/profile
至此,虚拟机的环境全部搭建完成,下面进行集群的配置
集群搭建
集群部署规划
|
|
hadoop100 |
hadoop101 |
hadoop102 |
|
HDFS
|
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
|
YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
hadoop集群至少需要3个replication,再加上一台NameNode,一台ResourceManager,一台SecondaryNameNode,理论上需要6台机器才能搭建一个集群.但是碍于条件有限,混搭成3台机器.每一台机器都是一个DataNode和NodeManager,同时hadoop100为NameNode,hadoop101为ResourceManager,hadoop102为SecondaryNameNode
配置集群
(1)核心配置文件
配置文件全部在 /opt/module/hadoop-2.7.2/etc/hadoop/目录下,先cd进来
配置core-site.xml
vim core-site.xml
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop100:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property>
(2)HDFS配置文件
配置hadoop-env.sh
vim hadoop-env.sh
修改JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置hdfs-site.xml
sudo vim hdfs-site.xml
<property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop102:50090</value> </property>
(3)YARN配置文件
配置yarn-env.sh vim yarn-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_144
配置yarn-site.xml vim yarn-site.xml 在该文件中增加如下配置 <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop101</value> </property> <!-- 日志聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留时间设置7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
(4)MapReduce配置文件
配置mapred-env.sh vim mapred-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_144
配置mapred-site.xml 首先先cp一份 cp mapred-site.xml.template mapred-site.xml 再编辑 vim mapred-site.xml 在该文件中增加如下配置 <!-- 指定MR运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop102:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop102:19888</value> </property>
(5)配置slaves
vim slaves
将localhost删除
添加三个子节点主机名
hadoop100
hadoop101
hadoop102
wq保存退出
(5) 在集群上分发配置好的Hadoop文件
xsync /opt/module/hadoop-2.7.2/etc/hadoop
集群启动
格式化Namenode 在hadoop100上
hdfs namenode -format
启动hdfs
start-dfs.sh
启动历史服务器
mr-jobhistory-daemon.sh start historyserver
在Hadoop101上启动Resourcemanager start-yarn.sh
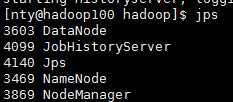
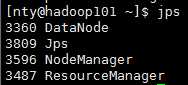
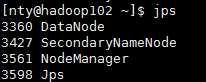
使用jps命令
hadoop100
hadoop101
hadoop102
如果集群出了问题,删除每一台机器上的 data logs文件,再重新启动
cd $HADOOP_HOME rm -rf data logs
如果还不行,请留言.
以上是关于大数据-Hadoop生态-Hadoop集群搭建的主要内容,如果未能解决你的问题,请参考以下文章