MySQL知识树-查询语句
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL知识树-查询语句相关的知识,希望对你有一定的参考价值。
在日常的web应用开发过程中,一定会涉及到数据库方面的操作,其中查询又是占绝大部分的。我们不仅要会写查询,最好能系统的学习下与查询相关的知识点,这篇文章我们就来一起看看mysql查询知识相关的树是什么样的。
MySQL查询知识树:
一、查询的种类
二、查询的原理
三、查询的应用场景
四、查询的效率比较
五、如何进行查询优化
六、与查询相关的知识扩展
一、查询的种类
MySQL的查询可以分为内连接查询、左连接查询、右连接查询、联合查询。
①内连接是通过关联表中共有的列来匹配出记录,查询出来的数据是两表的交集。
我们使用以下表来对该查询进行说明:
create table t_commodity_type(
`id` BIGINT(20) not null auto_increment comment ‘商品类别ID‘,
`time` TIMESTAMP not null DEFAULT CURRENT_TIMESTAMP comment ‘入库时间‘,
`name` VARCHAR(32) not null DEFAULT ‘‘ comment ‘名称‘,
`is_use` bit(1) not null DEFAULT b‘0‘ comment ‘是否上架‘,
primary key (`id`)
)engine=innodb DEFAULT CHARSET=utf8 comment ‘商品类型表‘;
create table t_commodity(
`id` BIGINT(20) not null auto_increment comment ‘商品ID‘,
`commodity_type_id` BIGINT(20) not null DEFAULT 0 COMMENT ‘商户所属类别ID‘,
`time` TIMESTAMP not null DEFAULT CURRENT_TIMESTAMP comment ‘入库时间‘,
`name` varchar(64) not null DEFAULT ‘‘ comment ‘商品名称‘,
`price` DECIMAL(20,2) not null DEFAULT 0.00 comment ‘价格‘,
`is_use` bit(1) not null DEFAULT b‘0‘ comment ‘是否上架‘,
PRIMARY key (`id`),
key `com_typ_id` (`commodity_type_id`) using BTREE
)engine=innodb DEFAULT charset=utf8 COMMENT ‘商品表‘;
首先从表结构上看t_commodity表通过commodity_type_id列和t_commodity_type表产生了关联,例如有一个查询需求是要通过商品类型查询出该类型下的所有商品(上下架状态都包含在内),则SQL实现可以如下:
select c.id as id, ct.`name` as type_name, c.`name` as `name`, c.time as time
from t_commodity_type ct inner join t_commodity c on ct.id=c.commodity_type_id where ct.id=1;
查询出的结果如下:
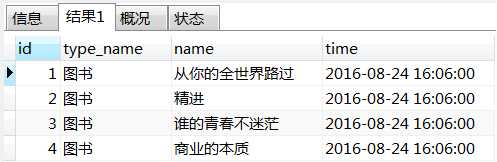
以上SQL可以通过另外一种形式展现,如下:
select c.id as id, ct.`name` as type_name, c.`name` as `name`, c.time as time
from t_commodity_type ct, t_commodity c where ct.id=c.commodity_type_id and ct.id=1;
这两种SQL的效果是等价的,使用哪种取决于你公司的SQL规范。
②左连接查询是获取左边表中所有的记录,即便右边表中并没有与之相匹配的记录
对于我们刚刚那个查询需求,如果用左连接来实现是什么效果呢?SQL如下:
select c.id as id, ct.`name` as type_name, c.`name` as `name`, c.time as time
from t_commodity c left join t_commodity_type ct on c.commodity_type_id=ct.id and c.commodity_type_id=1;
查询结果如下:
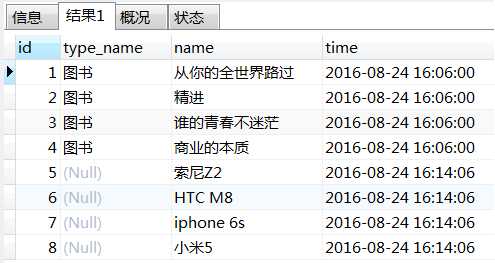
从结果中我们可以看到id为5~8的记录的type_name数据为null,仔细想想这是理所当然的,因为我们的条件限定为了c.commodity_type_id=1,也就是说t_commodity_type表中id为1的记录会被匹配到,但是“索尼Z2、HTC M8、iphone 6s、小米5”这些商品仅能和t_commodity_type表id为3的记录产生匹配,故而它们的type_name就默认填充为null了。
③右连接查询是获取右边表中所有的记录,即便左边表中并没有与之相匹配的记录。
就拿刚刚那个左连接的查询来说,我们可以改造为右连接查询来实现,SQL如下:
select c.id as id, ct.`name` as type_name, c.`name` as `name`, c.time as time
from t_commodity_type ct right join t_commodity c on ct.id=c.commodity_type_id and c.commodity_type_id=1;
需要说明的是内连接的第二种写法在不添加任何条件的情况下会出现笛卡尔积(结果集的记录数是两表记录数相乘)。
我们可以通过如下SQL看到这样的效果:
select * from t_user_order uo, t_user_collect uc;
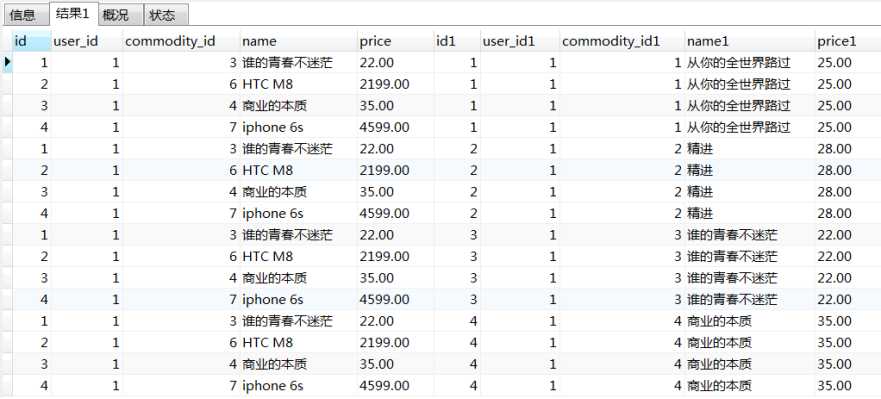
假若我们给这个查询增加一个条件,则MySQL就会筛选掉不相关的记录,最终展示符合我们条件的记录,例如:
select * from t_user_order uo, t_user_collect uc where uo.commodity_id=3 and uc.commodity_id=3;

其实两表做笛卡尔积在查询中是属于正常流程,先做笛卡尔积,然后再通过条件筛选出符合预期的记录,下面会对此进行深入探讨。
二、查询的原理
接下来我们来探讨一下查询的实现原理,首先我们要知道对于查询我们可以将其分为逻辑查询和物理查询,逻辑查询表示执行查询应该得到什么样的结果,可以理解为当我们在写出一个SQL时,我们对这个SQL所预期的结果;物理查询是指MySQL如何得到查询结果,即在执行SQL语句的过程中MySQL做了什么。
在这里我们需要了解下一个查询中可能包含有哪些内容:
1、select,2、distinct,3、join,4、on,5、from,6、where,7、having,8、group by,9、rollup,10、order by,11、limit
1)无论我们的查询是inner join还是left join,from操作总是最先执行的,form操作会得到关联表的笛卡尔积;
2)接着on操作会进行筛选,只有符合on后条件的记录才会被筛选出来;
3)join需要注意如果是left join或right join,则会保留表中未匹配的行(也称之为添加外部行),这是我们做两表联查时能理解的过程,其实做3表、5表联查过程也是一样的,将两表联查得到的记录与表3重复form、on、join的过程,完成后再对表4、表5,以此类推;
这里详细对多表联查的过程做下说明,假设我们联查表A、B、C、D
先是表A、B做笛卡尔积,即两表记录数相乘,然后通过on来筛掉不符合的记录,如果是left join或right join这种方式的联查,则还需要保留外部行,怎么理解保留外部行,就是保留表中被过滤条件过滤掉的数据,这样就得到了表A、B的联查数据,接下来再将得到的数据和表C做笛卡尔积,并重复这一过程,直到最后一张表完成这一过程,最后就得到了A、B、C、D四表联查的数据;
4)通过上述操作得到记录后,where会对记录进行过滤,只有满足where后条件的记录才会被筛选出来;
另外需要注意的是对于left join和right join的过滤,on过滤完之后还会添加保留表中被on条件过滤掉的记录,而被where条件过滤的记录则是永久过滤。
5)group by会对刚刚经过了where的记录进行分组;
6)having需要和group by配合使用,因为having使用的前提是group by已经对记录完成了分组,而having就是来对分组的记录再进行筛选,这里需要说明的是因为在分组前执行了where,因此若分组后的记录没有达到我们的预期,就需要使用having;
需要注意的是,若在left join和right join查询中,对select子句后使用count(1)或count(*),可能会把添加的行统计入内从而导致查询结果与预期结果不符合,对于这样的查询最好是count()具体列。
7)select在这里是将需要返回的列筛选出来,可以看到select的优先级并不高,是在最后几步才做的;
需要注意的是列的别名不能在select中的其他别名表达式中使用;
8)如果查询语句中带有了去重子句distinct,则会执行去掉重复记录的操作;
去掉重复记录的操作原理是对进行distinct操作的列增加一个唯一索引,如若SQL中使用了group by,则distinct是无效的,因为已经进行了分组,不会移除任何行。
9)接下来是order by,在我们得到了预期的记录后,就需要对记录进行排序,以方便阅读;
另外在order by中还可以指定select中列的序列号,通过指定序列号就能达到指定列的排序效果。
例如SQL:select id,commodity_type_id from t_commodity order by commodity_type_id,id;
等价于:select id,commodity_type_id from t_commodity order by 2,1;
需要注意的是若不使用order by则查询出来的数据是无序的,并非是按照主键有序排列,这是因为关系型数据库是基于数学来实现的,关系对应数学中的集合,集合本身是无序的,因此在不使用order by的情况下从集合中取数据无法保证是按顺序排列的。
还有在对列进行排序时,若列没有索引,则排序会造成一定的开销。
10)最后执行limit,拿到从指定位置开始(不包含指定位置)的指定行记录,limit常和order by一起使用,其使用方式是limit n,m,表示拿到从n行开始(不包含n行)的m行数据。
另外在大数据量下使用limit来分页效率是比较低的,因为需要在这么多数据量下去定位位置(即定位n),更好的解决方案是在应用层面使用缓存。
额外知识点:
每张表的行中都有可能存在null值,但并不是每个null值都是一样的,或者说你将两个null值进行比较返回的可能不是0或1而是unknown。毕竟关系型数据库中的null值比较和编程语言中的null值比较是不同的。但是有两种情况下我们可以认为两个null值是相等的:
①group by子句把所有null值分到同一组;
②order by子句把所有null值排列在一起,可以理解为在order by子句中,null值被认为是相同的值,同时null值在order by中被认为是最小的,若按照升序排列则null值会排在最前面;
额外知识点:
在where子句后书写过滤条件时,有两种过滤情况是不允许发生的。
①数据没有分组前或者说在group by没有执行前,在where子句中不能使用分组函数,例如max()、min()、count()、sum()等,正因为这个限制的存在就能理解having子句存在的意义了,因为我们还存在对分组后的数据进行统计的可能;
错误的SQL:select id from t_commodity c where count(commodity_type_id)>=5;
②为select子句后的列取别名,并在where子句里直接使用列别名是不允许的。因为where的执行顺序是要高于select的,因此在列还没有被选取的情况下,就开始使用列别名明显是不行的。
错误的SQL:select `name` as n from t_commodity where n=‘精进‘;
--------------------未完待更新--------------------
以上是关于MySQL知识树-查询语句的主要内容,如果未能解决你的问题,请参考以下文章