scrapy和scrapy_redis入门
Posted L某人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy和scrapy_redis入门相关的知识,希望对你有一定的参考价值。
Scarp框架
- 需求
- 获取网页的url
- 下载网页内容(Downloader下载器)
- 定位元素位置, 获取特定的信息(Spiders 蜘蛛)
- 存储信息(ItemPipeline, 一条一条从管里走)
- 队列存储(scheduler 调度器)
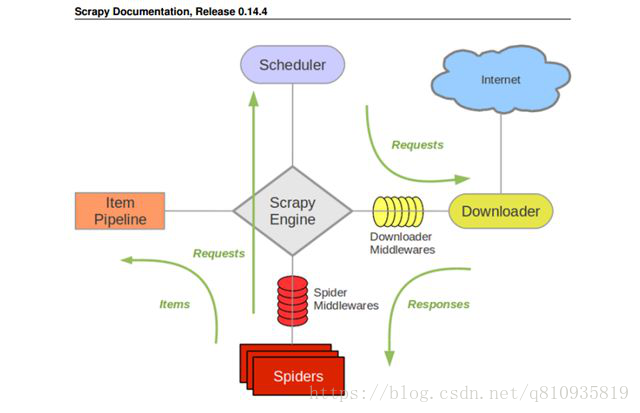
首先, spiders 给我们一个初始的URL, spider获取列表页内的详情页的url.
其次, 将url 存储到scheduler内, 然后 scheduler 就会自动将url放到downloader内执行.
详情页download之后, 返回response给spiders.
再次, spiders会将response获取到并且查找需要的内容, 内容进行封装item.
最后, 这个item就会被传输到itempipeline中, 存储或者其他操作.
安装scrapy的方法:
pip install wheel
pip install 你的路径/Twisted-18.7.0-cp35-cp35m-win_amd64.whl
pip install scrapy
缺少win32api
https://germey.gitbooks.io/python3webspider/content/1.8.2-Scrapy%E7%9A%84%E5%AE%89%E8%A3%85.html
创建项目:
在pycharm中选中目录右键open terminal 进入命令窗口执行如下:
scrapy startproject scrapy_project(项目名)
创建spider 进入scrapy_project中
cd scrapy_project
scrapy genspider bole jobbole.com
(scrapy genspider 项目名(spider.py) 爬取网址)
运行, 创建一个main.py, main.py 的内容就是:(用于运行启动整个项目,可以避免每次都去terminal输入命令)
from scrapy.cmdline import execute
execute(‘scrapy crawl bole‘.split())
bole:要执行的spider里的py文件名
Scrapy文件结构
- Items.py定义scrapy内部数据的模型文件
继承scrapy.item
属性 变量名=scrapy.Field()
- Pipelines.py (管道)当我们的items.py被返回的时候,会自动调用我们的pipelines.py类中的process_item()函数;所以pipelines.py中的类需要加到settings.py中的ITEM_PIPELINES字典中
ITEM_PIPELINES = {
‘myproject.pipelines.XiaochengxuPipeline‘: 300,
#’项目名+pipelines+pipelines.py中的类’:300,
}
- Settings.py 配置各种参数 ROBOTSTXT_OBEY = False (是否遵守君子协议)
#下载延迟
3.1 DOWNLOADER_MIDDLEWARES = {
‘myproject.middlewares.MyprojectDownloaderMiddleware‘: 543,
}
Isinstance 判断那个类的实例
- bole.py
通过xpath获取内容, xpath返回的元素内容是selector: extract_first() = [0]extract()
zan = response.xpath(‘//h10[@id="89252votetotal"]/text()‘).extract_first()
extract_first() 获取selector内的data的内容
items.py
# 添加内容到item中 固定格式
titile = scrapy.Field()
zan = scrapy.Field()
bole.py
from myproject.items import BoleItem
#创建Item的类
item = BoleItem()
# 通过字典的形式填充item的类
item[‘title’] = title
item[‘zan’] = zan
# 相当于将item传给pipelines
yield item
Items.py
class BoleItem(scrapy.Item):
# 变量=scrapy.Field() 将bole.py的内容获取过来
title = scrapy.Field()
zan = scrapy.Field()
- 我们自己定义的item类需要继承scrapy.Item
- 我们需要定义的类里面的变量
名称 = scrapy.Field()
- pipelines.py
class BolePipeline(object):
def process_item(self, item, spider):
#变量=item[‘title‘] 接收items中的内容
item 相关的操作:
- 打印
- 存储到mysql
- 其它
Settings.py
ITEM_PIPELINES = {
# ‘myproject.pipelines.MyprojectPipeline‘: 300,
‘myproject.pipelines.BolePipeline‘: 300,
#固定格式.固定格式.pipeline.py中创建的类名:300 300是优先级 优先级越低优先级越高
}
Pycharm中点击Terminal 输入:
Scarpy shell +要访问的url
进入输入命令行然后输入要匹配的xpath或用其他方法要匹配的信息
//td[not(@class)][1]/a/text() 取没有class中的第一个
Yield 返回时多个参数meta={‘item‘:item}
参数一:item[‘url_herf‘]让函数parse_detail去处理的url
参数二:meta={‘item‘:item}可在函数parse_detail中item = response.meta[‘item‘]调用之后一同返回yield item
参数三:callback=self.parse_detail 之后要处理的函数
Yield scrapy.Request(item[‘url_herf‘],meta={‘item‘:item},callback=self.parse_detail)
# 没有此步数据库会报错1241 因为里面有换行符需要处理连接成字符串
新变量 = ‘‘.join(旧变量)
返回302错误需要添加headers头
ImagesPipeline
- 我们需要将这个ImagesPipeline放到setting的pipline的配置中
- 我们需要将这个图片存储的位置配置成功, setting中的IMAGES_STORE=‘img_download‘
- 需要下载的URL必须存储在 item 中的 image_urls
拉勾网需要不记录cookie,需要在setting中将cookie:False 开启
Crawl模板
- scrapy genspider -t crawl lagou lagou.com
- LinkExtractor 获取需要的url的正则表达式
- callback就是页面返回以后,使用哪个函数处理页面的返回信息
- follow就是如果是true, 就会继续寻找当前页面的url处理, 如果是false, 就不在当前页面寻找url继续处理
数据的流程
- scrapy初始的内容是添加在 spiders内部的, 它的初始的url的获取通过两种方式, 第一种就是: start_urls, 第二种就是: 函数 start_request()
- spiders会将url 传递并存储到sheduler中, scheduler就是一个存储url(Request)的队列.
- scheduler 中的url, 我们会获取这些url放到downloader中去下载页面. CONCURRENT_REQUESTS就是downloader中同时下载的页面的最大值.
- downloader在下载结束之后, 会将下载后的response返回给spiders.
- downloader 在下载之前会经过 download middware, 可以在这里添加1, headers, 2, 代理
- spiders在获取到response之后, 会解析这个response, 获取特定需要的信息并生成items, yield item
- 在spiders获取到response之后, 还有可能生成新的url, 就再次执行2.
- item会被传递到item pipeline中, item pipeline会执行后续的操作(可能是存储, 展示, 函数).
每一个部分的作用于他们的输入输出
1 spiders:
- url生成的地方
- 返回值解析的地方
- item生成
输入:
- start_urls , start_request
- response(downloader给的)
输出:
- request
- item
2 Scheduler
- 存储Request
输入:
url(Request) 输入的模块是:spiders, pipeline, downloader
输出:
url (Request) 输出的模块只有downloader
3 Downloader
- 接受Request, 并下载这个Request
- 将response返回给spiders
输入:
Request, 来源是scheduler
输出:
response: 接收方spiders
request 接收方就是scheduler
4 itempipline
- 获取到item之后, 将它(存储, 展示, 其它)
输入:
item, spiders生成的
输出:
不确定, (数据库, 文件, 其它)
Request, 给scheduler
5 downloader middlewares
- 当scheduler的request经过的时候, 此时还没下载页面, 我们可以对Request进行修改 process_request
- 当 downloader 下载页面结束的时候, 也会经过downloader middlewares 我们可以根据response的内容做一些处理 process_response
- 当下载的过程中出现了异常, 也会经过downloader middlewares, process_exception
6 spiders middlewares
- 当Reuqest从spider发给sheduler的时候, 会经过spiders middleware, 可以做的操作是过滤Request, 去重等
- 当downloader 返回response的时候, 也能经过spiders middlewares, 这里一样是可以做一些根据返回值的过滤操作.
Redis安装
找到文件Redis-x64-3.2.100.msi安装
解压redis-desktop-manager.rar中一个文件夹 高版本为中文
在Python环境中安装scrapy-redis:pip install scrapy-redis
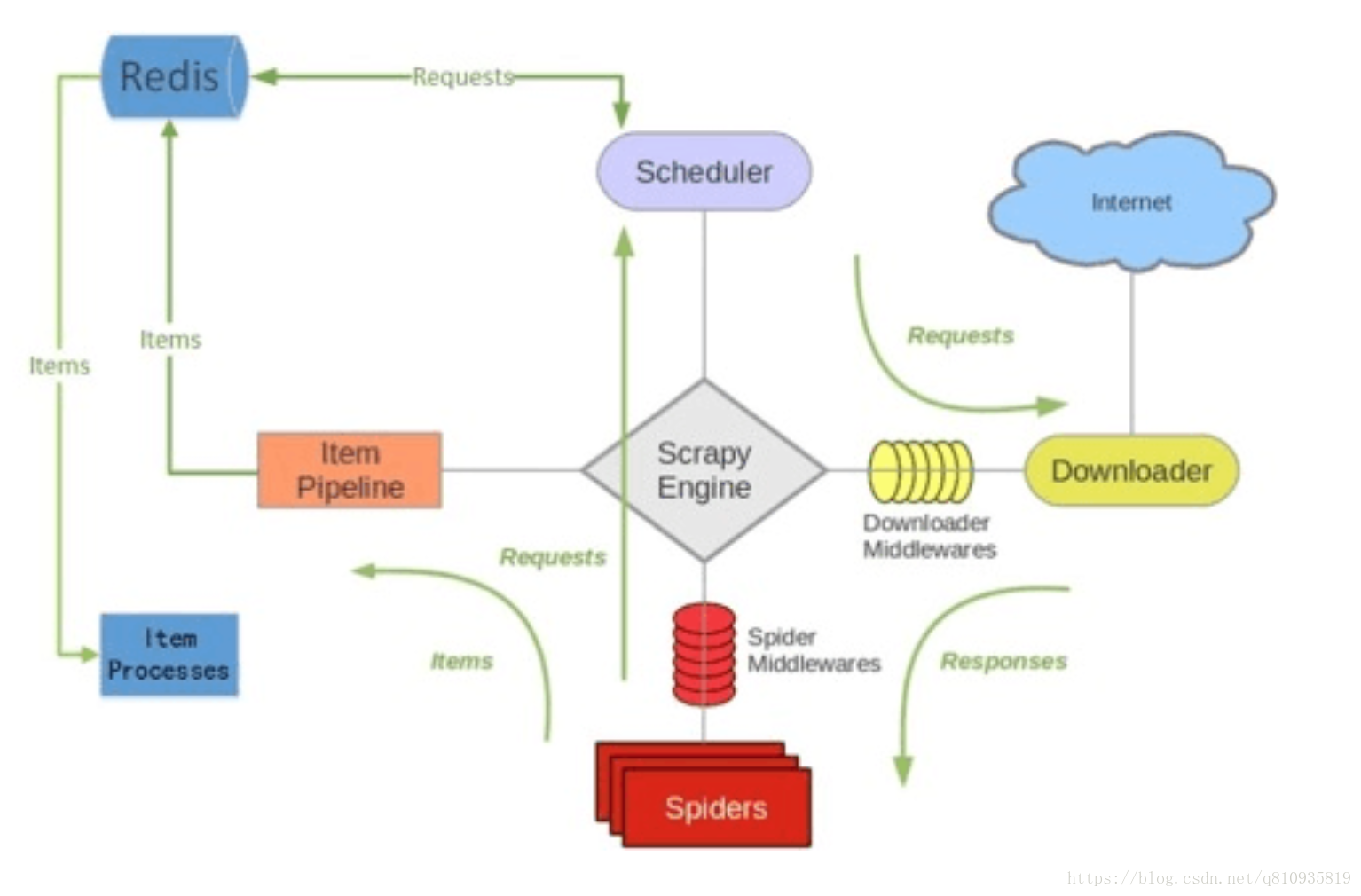
scrapy-redis 的改造方法
- 要将一个Scrapy项目变成一个Scrapy-redis项目只需修改以下三点就可以了:
导包:from scrapy_redis.spiders import RedisSpider
- 将爬虫的类从scrapy.Spider变成RedisSpider;或者是 从scrapy.CrawlSpider变成scrapy_redis.spiders.RedisCrawlSpider。
2.将爬虫中的start_urls删掉。增加一个redis_key="xxx"。这个redis_key是为了以后在redis中控制爬虫启动的。爬虫的第一个url,就是在redis中通过这个发送出去的。
3.在配置文件中增加如下配置:
Scrapy-Redis相关配置
确保request存储到redis中
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
确保所有爬虫共享相同的去重指纹
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
设置redis为item pipeline
ITEM_PIPELINES = { ‘scrapy_redis.pipelines.RedisPipeline‘: 300}
在redis中保持scrapy-redis用到的队列,不会清理redis中的队列,从而可以实现暂停和恢复的功能。
SCHEDULER_PERSIST = True
设置连接redis信息
REDIS_HOST = ‘127.0.0.1‘
REDIS_PORT = 6379
REDIS_PASSWORD = 123456
运行爬虫:
在爬虫服务器上(pychong)。进入爬虫文件所在的路径,然后输入命令: scrapy runspider [爬虫文件.py]。
在Redis服务器上,推入一个开始的url链接:在redis安装目录下运行redis-cli.exe;命令行输入:lpush [redis_key] start_url 开始爬取。
在Mysql中添加用户:grant all on *.* to [email protected]’%’ identified by ’密码’;
在Mysql中查询用户:select user,host from mysql.user;
以上是关于scrapy和scrapy_redis入门的主要内容,如果未能解决你的问题,请参考以下文章