Linux 搭建Hadoop集群 ----workcount案例
Posted 秋风伊人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux 搭建Hadoop集群 ----workcount案例相关的知识,希望对你有一定的参考价值。
在
Linux搭建集群---JDK配置
Linux搭建集群---SSH免密登陆
Linux搭建集群---集群搭建成功
的基础上实现workcount案例
注意
虚拟机三台启动集群(自己亲自搭建)
1. wordcount程序
1.1Hadoop集群测试WordCount程序
1.1.1 在hadoop目录下创建一个wordcount文件夹

1.1.2切换到wordcount文件夹,新增两个文件,并且编辑内容

文件内容如下:
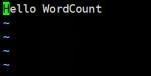

文件内容如下:
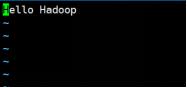
1.1.3在HDFS中创建input文件夹

1.1.4查看HDFS中的文件夹

1.1.5 将创建的两个文件复制到/input目录中

1.1.6查看input文件夹下内容

1.1.7 运行wordcount程序
切换到hadoop安装目录下share/hadoop/mapreduce目录下,hadoop自带运行wordcount程序的jar包

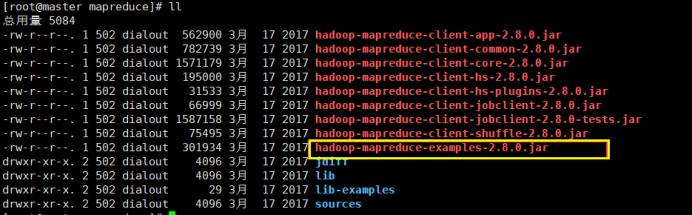
使用jar命令运行wordcount程序,input代表计算文件位置,output代表计算结果指定位置

1.1.8查看运行结果
hadoop fs -cat /output/*

1.2 eclipse集成hadoop插件
1.2.1 如果eclipse安装到windows当中,那么就需要在真机安装Hadoop
配置hadoop环境变量(将hadoop-2.8.0用管理员用户解压)
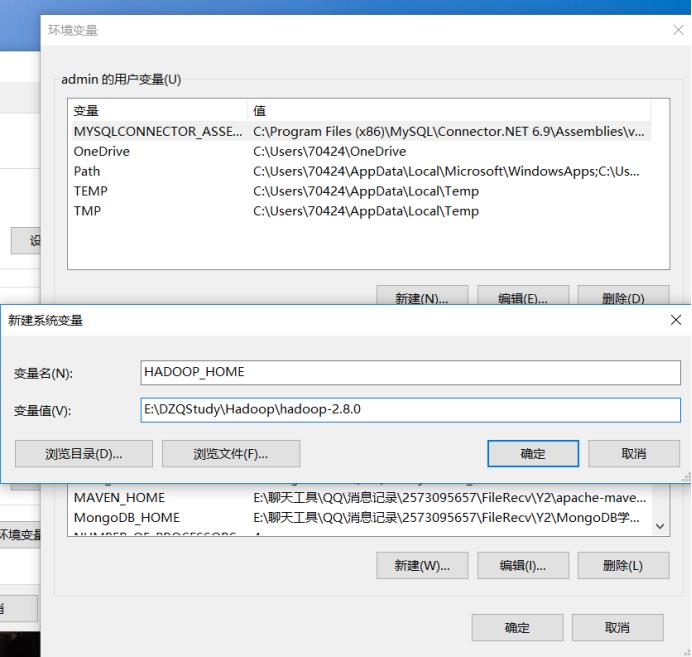
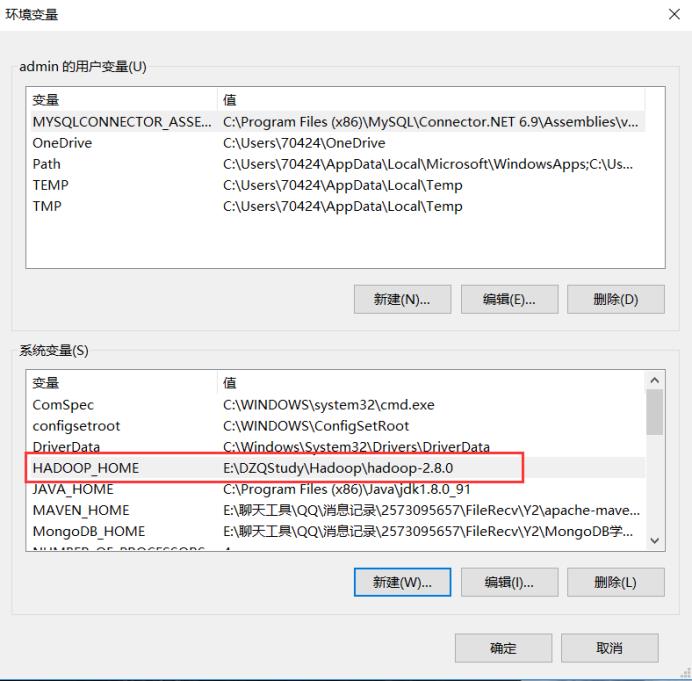
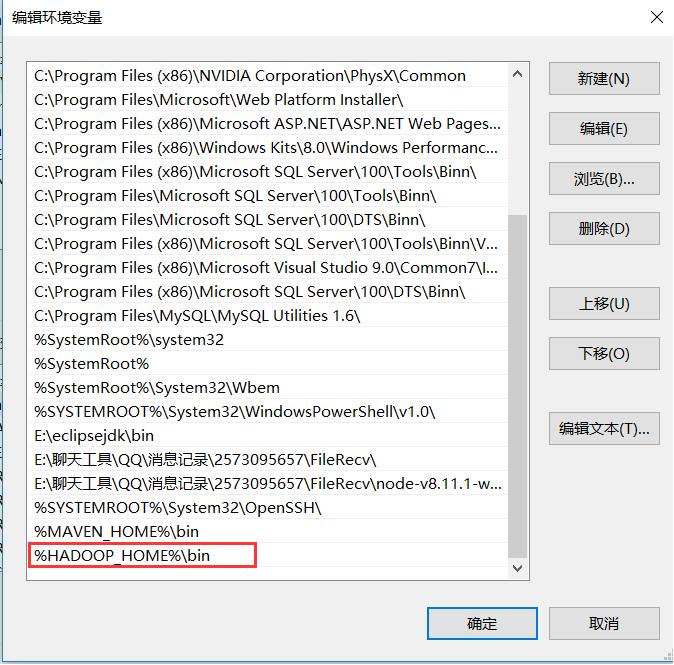
查看JDK 和Hadoop的版本号(不用管理员的身份)

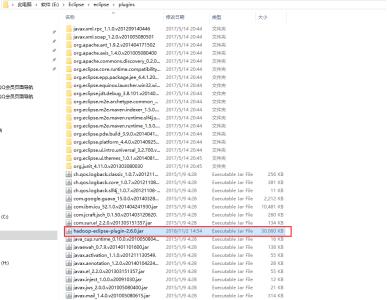
1.2.2 下载hadoop-eclipse-plugin-2.6.0.jar赋值到eclipse安装目录下的plugins目录下
1.2.3配置hadoop安装目录
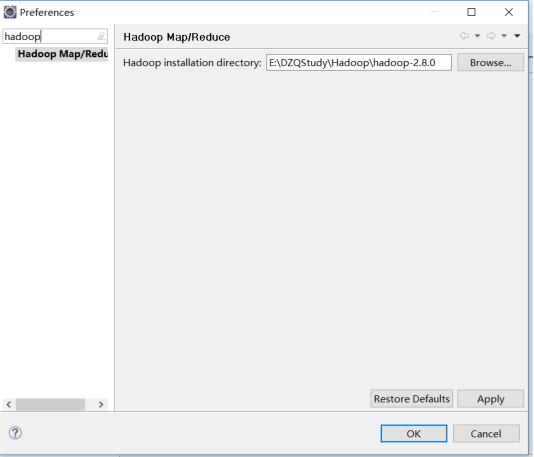
1.2.4配置插件

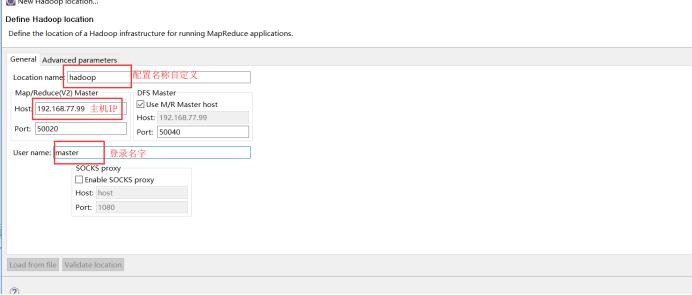
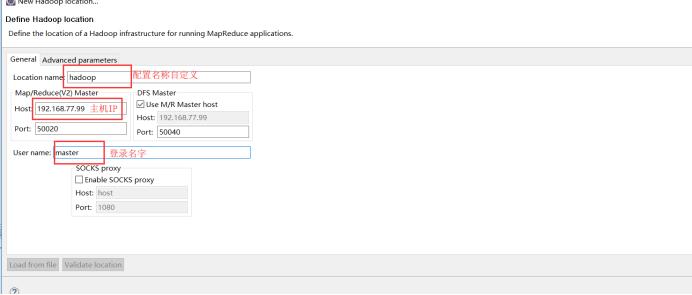
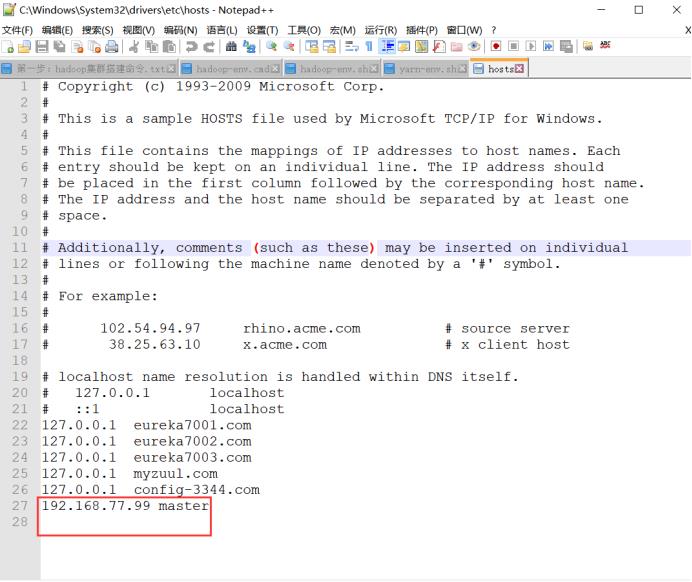
注意:主机名称亦可以换成ip地址,但是真机hosts文件要配置对应关系
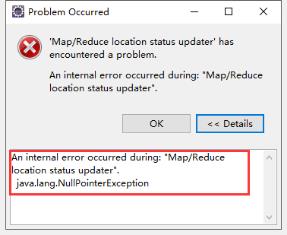
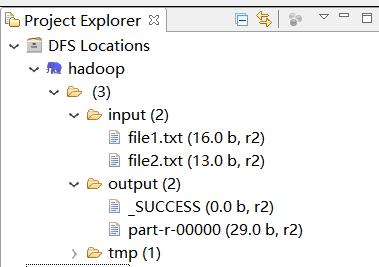
1.3 eclipse运行wordcount程序
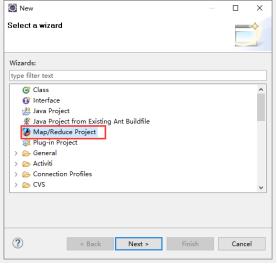
1.3.1新建一个mapreduce程序
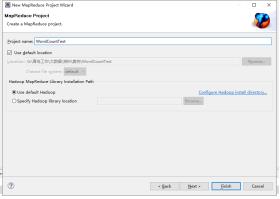
1.3.2创建WordCount运行程序
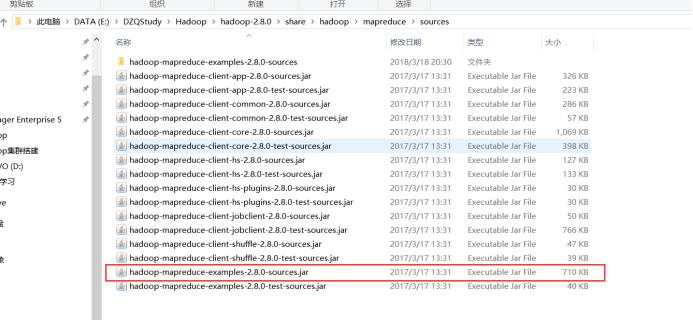
在真机安装的hadoop下找到hadoop-mapreduce-examples-2.8.0-sources.jar,目录为..../hadoop-2.8.0\\share\\hadoop\\mapreduce\\sources
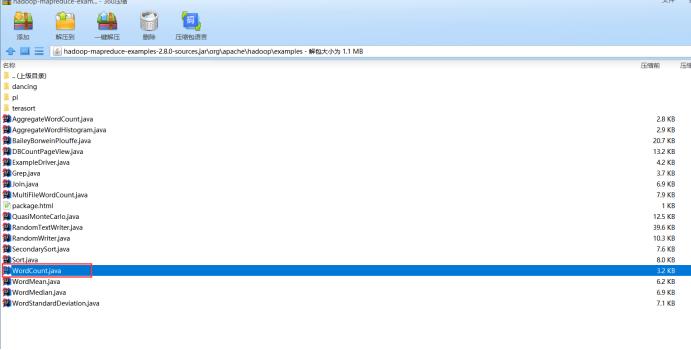
以解压包方式打开,找到WordCount.java,目录为:
hadoop-mapreduce-examples-2.8.0-sources.jar\\org\\apache\\hadoop\\examples
右键打开方式---360压缩
1.3.3运行WordCount程序
点击WordCount.java文件,配置启动参数
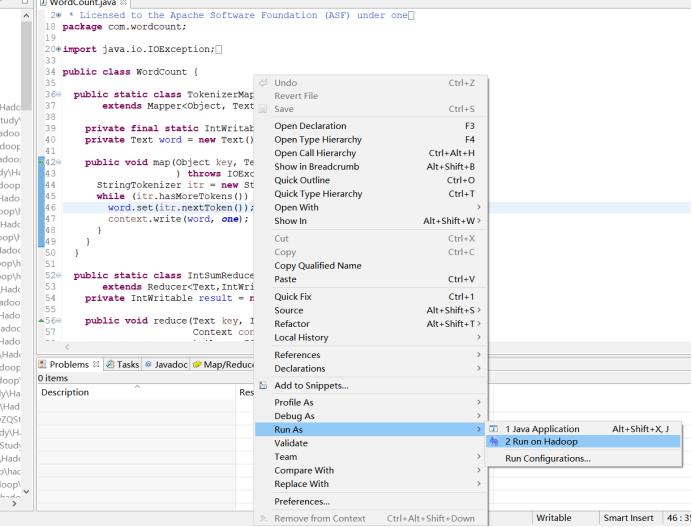
报错:
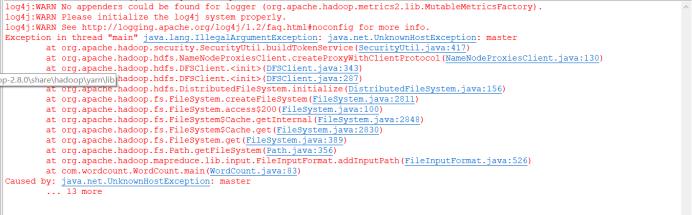
其中配置参数中master可以改为ip地址,如果配置成master那么需要在真机hosts文件当中配置master和ip的对应关系!
参考网址:
https://blog.csdn.net/Biexiansheng/article/details/78019642?tdsourcetag=s_pcqq_aiomsg
如下操作:
添加以下信息:
第一种错误信息:

此错误可能在hadoop安装目录下缺少文件,将次压缩包的所有文件复制到hadoop安装目录下的bin

第二个错误
hadoop-2.8.0\\share\\hadoop\\common\\sources文件夹中找到hadoop-common-2.8.0-sources.jar,然后以压缩包的方式打开,找到hadoop-common-2.8.0-sources\\org\\apache\\hadoop\\io\\nativeio\\NativeIO.java,复制到项目中,注意,包名和报错的包名保持一致,org.apache.hadoop.io.nativeio
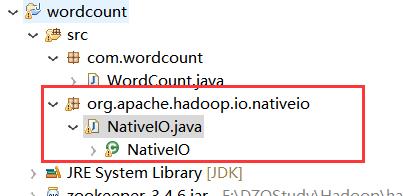
打开代码:
将

改为:

错误2:
org.apache.hadoop.security.AccessControlException: Permissiondenied: user=zhengcy, access=WRITE,inode="/user/root/output":root:supergroup:drwxr-xr-x
在集群中运行hadoop fs -chmod 777 /
运行结果如下所示:

1.4将WordCount程序打成jar包放在集群中运行
1.4.1将程序打包
点击项目-->右键-->选择Export-->找到Runnable JAR File
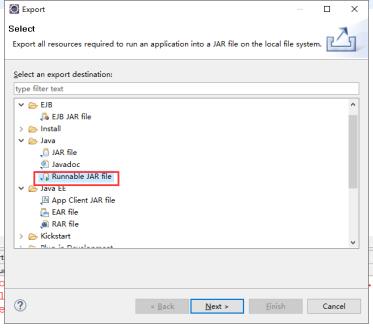
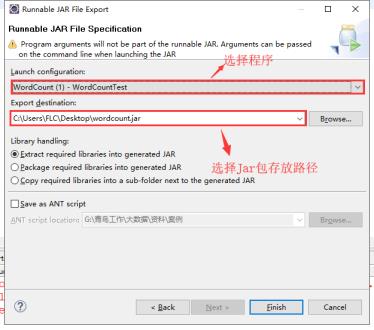
点击Finish,将打包好的Jar包通过XFTP传入到Linux指定位置(/usr/bigdata/hadoop)

在XShell中切换到Jar文件存放位置路径,通过命令运行查看 切入到wordcount.jar 架包所存放的位置 执行以下命令


以上是关于Linux 搭建Hadoop集群 ----workcount案例的主要内容,如果未能解决你的问题,请参考以下文章