大数据技术HBase基本知识介绍及典型案例分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术HBase基本知识介绍及典型案例分析相关的知识,希望对你有一定的参考价值。
1.HBase简介
1.1 Hbase是什么
HBase是一种构建在HDFS之上的分布式、面向列、多版本、非关系型的数据库,是Google Bigtable 的开源实现。
在需要实时读写、随机访问超大规模数据集时,可以使用HBase。
1.2 HBase特点
大:一个表可以有上亿行,上百万列。
面向列:面向列(组)的存储和权限控制,列(组)独立检索。
稀疏矩阵:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
数据类型单一:HBase中的数据都是字符串,没有类型,存储在hbase上的都是字节数组。
强一致性:Hbase是一个强一致性数据库,不是“最终一致性”数据库。
1.3 HBase缺点
单一RowKey固有的局限性决定了它不可能有效地支持多条件查询
不适合于大范围扫描查询
(2)支持上亿行、百万列;
(3)强一致性、高扩展、高可用
HBase数据读写,更新的数据是放在Memstore,只有当Memstore里的数据达到阈值,或者时间达到阈值,就会flush到磁盘上,生成HFile,而一旦生成HFile就是不可改变的。
当某一个DataNode上生成一个HFile后,就会异步更新到其他两个DataNode上(假设为3副本),这3个HFile是一模一样的。
PS:当客户端提交删除操作的时候,数据不是真正的删除,只是做了一个删除标记(delete marker,又称母被标记),表明给定航已经被伤处了,在检索过程中,这些删除标记掩盖了实际值,客户端读不到实际值。直到发生compaction的时候数据才会真正被删除。
HBase采用Master/Slave架构搭建集群,它隶属于Hadoop生态系统,由一下类型节点组成:HMaster节点、HRegionServer节点、ZooKeeper集群,而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等,总体结构如下
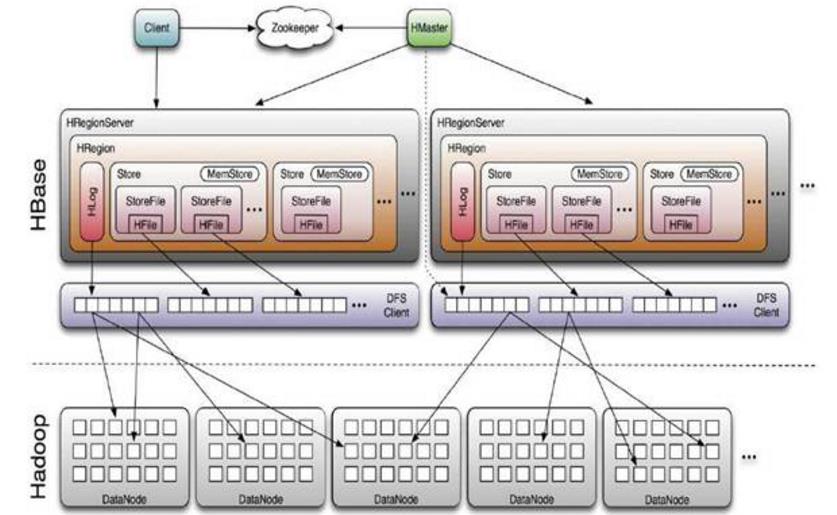
ROOT:系统内部表,里面存储了对应的.meta地址和开始结束信息。
.META:系统内部表,同样存储了对应HRegion地址和开始结束信息。
-ROOT-和.META.
参考文档:
以上是关于大数据技术HBase基本知识介绍及典型案例分析的主要内容,如果未能解决你的问题,请参考以下文章