用SparkSQL构建用户画像
Posted 伪全栈的java工程师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用SparkSQL构建用户画像相关的知识,希望对你有一定的参考价值。
用SparkSQL构建用户画像
二、 前言
大数据时代已经到来,企业迫切希望从已经积累的数据中分析出有价值的东西,而用户行为的分析尤为重要。
利用大数据来分析用户的行为与消费习惯,可以预测商品的发展的趋势,提高产品质量,同时提高用户满意度。
三、 初识用户画像

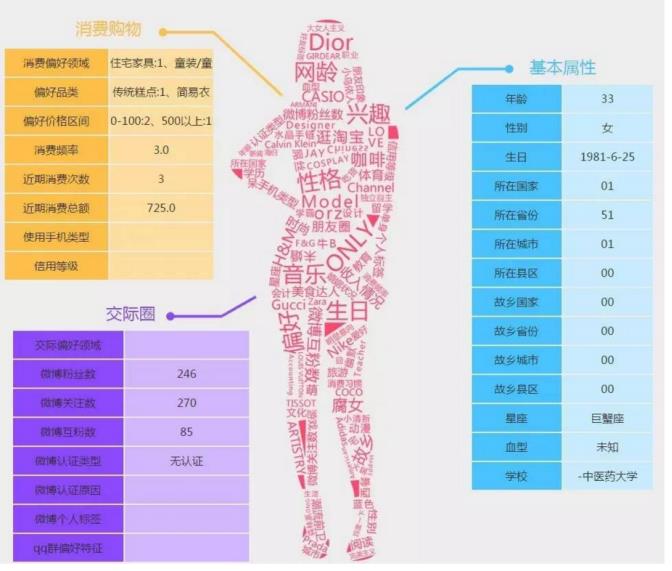
右边是一个人的基本属性,通过一个人的基本属性我们可以了解到这个人的基本信息,左边上图是通过消费购物信息来描述一个人特征,左边下图是通过交际圈信息来描述一个人特征,通过不同的维度,去描述一个人,认识一个人,了解一个人。这就是我们今天所要讲到的用户画像。
用户画像:也叫用户信息标签化、客户标签;根据用户社会属性、生活习惯和消费行为等信息而抽象出的一个标签化的用户模型。从电商的角度看,根据你在电商网站上所填的信息和你的行为,可以用一些标签把你描绘出来,描述你的标签就是用户画像。构建用户画像的核心工作即是给用户贴“标签”,而标签是通过对用户信息分析而来的高度精炼的特征标识。
四、 构建电商用户画像的重大意义
罗振宇在《时间的朋友》跨年演讲举了这样一个例子:当一个坏商家掌握了你的购买数据,他就可以根据你平时购买商品的偏好来决定是给你发正品还是假货以此来提高利润,且不说是否存在这种情况,但这也说明了利用用户画像可以做到“精准营销”,当然这是极其错误的用法。
其作用大体不离以下几个方面:
u 1、精准营销,分析产品潜在用户,针对特定群体利用短信邮件等方式进行营销;
u 2、用户统计,比如中国大学购买书籍人数 TOP10;
u 3、数据挖掘,构建智能推荐系统,利用关联规则计算,喜欢红酒的人通常喜欢什么运动品牌,利用聚类算法分析,喜欢红酒的人年龄段分布情况;
u 4、进行效果评估,完善产品运营,提升服务质量,其实这也就相当于市场调研、用户调研,迅速下定位服务群体,提供高水平的服务;
u 5、对服务或产品进行私人定制,即个性化的服务某类群体甚至每一位用户(个人认为这是目前的发展趋势,未来的消费主流)。比如,某公司想推出一款面向5-10岁儿童的玩具,通过用户画像进行分析,发现形象=“喜羊羊”、价格区间=“中等”的偏好比重最大,那么就给新产品提供了非常客观有效的决策依据。
u 6、业务经营分析以及竞争分析,影响企业发展战略
五、 如何构建电商用户画像
5.1 构建电商用户画像技术和流程
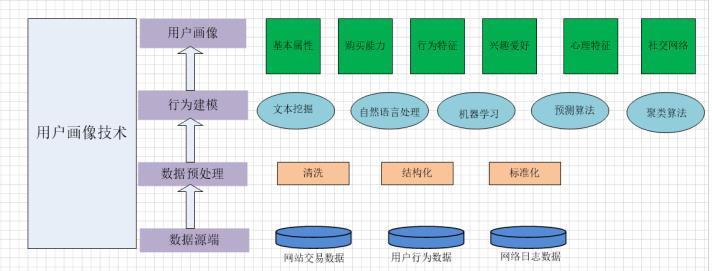
构建一个用户画像,包括数据源端数据收集、数据预处理、行为建模、构建用户画像
有些标签是可以直接获取到的,有些标签需要通过数据挖掘分析到!
5.2 源数据分析
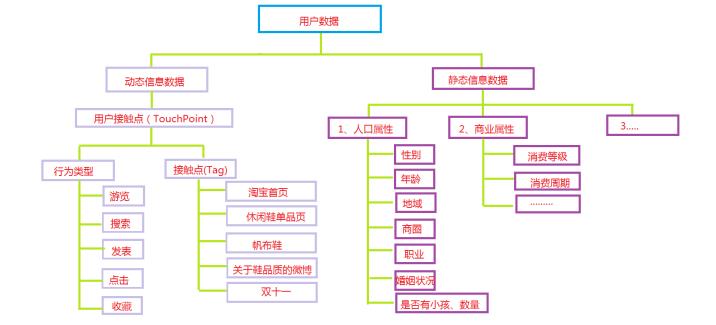
用户数据分为2类:动态信息数据、静态信息数据
静态信息数据来源:
- 用户填写的个人资料,或者由此通过一定的算法,计算出来的数据
- 如果有不确定的,可以建立模型来判断,比如用户的性别注册没有填写,可以建立模型,根据用户的行为来判断用户性别是什么,或者它的概率
动态信息数据来源:
- 用户行为产生的数据:注册、游览、点击、购买、签收、评价、收藏等等。
- 用户比较重要的行为数据:游览商品,收藏商品、加入购物车、关注商品
根据这些行为特性可以计算出:用户注册时间、首单时间、潮妈族、纠结商品、最大消费、订单数量、退货数量、败家指数、品牌偏好等等。
5.3 目标分析
用户画像的目标是通过分析用户行为,最终为每个用户打上标签,以及该标签的权重。
如,红酒 0.8、李宁 0.6。
标签:表现了内容,用户对该内容有兴趣、偏好、需求等等。
权重:表现了指数,用户的兴趣、偏好指数,也可能表现用户的需求度,可以简单的理解为可信度,概率。
5.4 用户画像建模
5.4.1 用户基本属性表
根据用户所填写的属性标签和推算出来的标签。用于了解用户的人口属性的基本情况和按不同属性维度统计。
作用:按人口属性营销、比如营销80后,对金牛座的优惠,生日营销。
主要数据来源:用户表、用户调查表、孕妇模型表、马甲模型表。
用户表:记录用户最基本的属性特性。
用户调查表:补充用户的其他基本信息。
用户所填写的基本信息:用户ID、用户名、密码、性别、手机号、邮箱、年龄、户籍省份、身份证编号、注册时间、收货地址等
用户所填信息计算得到的指标:
生日、星座、城市等级、手机前几位、手机运营商、邮件运营商
用户调查表得到:学历、收入、职业、婚姻、是否有小孩、是否有车有房、使用手机品牌。
根据算法得到:
身高、体重、性别模型、孩子性别概率、潜在汽车用户概率、是否孕妇、孩子年龄概率、手机品牌、更换手机频率、是否有小孩,是否有车,使用手机档次,疑似马甲标准、疑似马甲账号数、用户忠诚度、用户购物类型。
模型算法---性别模型
- 用户自己也填写了性别,但仍然要用算法算一次性别
|
用户性别 |
1男 0女 -1未识别 |
1、商品性别得分 2、用户购买上述商品计算用户性别等得分 3、最优化算法训练阀值,根据阀值判断 |
|
孩子性别 |
0 仅有男孩 1仅有女孩 2男女都有 3无法识别 |
1、选择男孩女孩商品 2、确定用户购买商品的男女性别比例 3、训练阀值,判断孩子性别,同用户性别类似 |
- 性别验证方法
随机抽样几千条数据让客户打电话确认。
与用户自己填的性别做对比,确认百分比。
模型算法---用户汽车模型
|
用户是否有车 |
1有 0 没有 -1 未识别 |
根据用户购买车相关产品 判断用户是否有车 |
|
潜在汽车用户 |
1有 0 没有 -1 未识别 |
用户游览或者搜索汽车 用户数据判断 |
模型算法---用户忠诚度模型
- 忠诚度越高的用户越多,对网站的发展越有利
|
用户忠诚度 |
1忠诚型用户 2偶尔型用户 3投资型用户 4游览型用户 -1未识别 |
总体规则是判断+聚类算法 1、游览用户型:只游览不购买的 2、购买天数大于一定天数的为忠诚用户 3、购买天数小于一定天数,大部分是有优惠才购买的 4、其他类型根据购买天数,购买最后一次距今时间,购买金额进行聚类 |
模型算法---用户身高尺码模型
|
男性用户身高尺码 |
xxx-xxx身高段,-1未识别 |
用户购买服装鞋帽等用户判断 |
|
男性身材 |
1偏瘦、2标准、3偏胖4肥胖、-1未识别 |
用户购买服装鞋帽等用户判断 |
|
女性用户身高尺码 |
xxx-xxx身高段,-1未识别 |
用户购买服装鞋帽等用户判断 |
|
女性身材 |
1偏瘦、2标准、3偏胖4肥胖、-1未识别 |
用户购买服装鞋帽等用户判断 |
模型算法---用户马甲标志模型
- 马甲是指一个用户注册多个账号
- 多次访问地址相同的用户账号是同一个人所有
- 同一台手机登陆多次的用户是同一个人所有
- 收货手机号相同的账号同一个人所有
模型算法---手机相关标签模型
- 对于手机营销参考意义比较大
- 使用手机品牌: 最常用手机直接得到
- 使用手机品牌档次:根据档次维表
- 使用多少种不同的手机:手机登陆情况
- 更换手机频率(月份):按时间段看手机登陆情况
5.4.2 客户消费订单表
根据客户消费的情况提取的客户标签,用于了解用户的消费总体情况,
最终的目的根据用户消费习惯与消费能力做营销。
主要数据来源:订单表、退货表、用户表、购物车表
订单表可以得到相关标签:
|
第一次消费时间、 最近一次消费时间、 首单距今时间、 尾单距今时间------分析用户什么时候来购买商品以及多久没有购买了。 最小消费金额、 最大消费金额、 累计消费次数(不含退拒)、 累计消费金额(不含退拒)、 累计使用代金券金额、 累计使用代金券次数。-----分析用户总体消费情况。 客单价(含退拒)、 近60天客单价(含退拒)-----分析用户消费水平。 常用收货地址、 常用支付方式----分析用户常用的消费属性,方便做定向营销。
|
退货表可以得到相关标签:
|
近30天购买次数(不含退拒)、 近30天购买金额(不含退拒) 近30天购买次数(含退拒)、 近30天购买金额(含退拒)----分析用户最近的消费能力。 退货商品数量、 退货商品金额、 拒收商品数量、 拒收商品金额、 最近一次退货时间-----分析用户拒收和退货习惯。
|
购物车表可以得到相关标签:
|
最近30天购物车次数、 最近30天购物车商品件数、 最近30天购物车提交商品件数、 最近30天购物车放弃件数、 最近30天购物车成功率------分析用户购物车使用习惯 |
订单表和用户表可以得到相关标签:
|
学校下单总数、 单位下单总数、 家里下单总数、 上午下单总数、 下午下单总数、 晚上下单总数----分析用户购物时间与地点习惯。 |
5.4.3 客户购买类目表
根据客户购买类目的情况提取客户标签,用于了解类目的购买人群情况和针对某一类目的营销等。
主要数据来源:订单表、购物车表、类目维表
类目维表可以得到相关标签:
|
一级分类ID、 一级分类名称、 二级分类ID、 二级分类名称、 三级分类ID、 三级分类名称-----分析用户都购买了哪些类目。 |
电商的三级类目:
京东商城:

淘宝:
订单表和类目维表可以得到相关标签:
|
近30天购买类目次数、 近30天购买类目金额、 近90天购买类目次数、 近90天购买类目金额、 近180天购买类目次数、 近180天购买类目金额、 累计购买类目次数、 累计购买类目金额----分析用户最近都购买了哪些类目。 最近一次购买类目时间、 最后一次购买类目距今天数----分析用户多久没有购买这个类目。 |
购物车表和类目维表可以得到相关标签:
|
近30天购物车类目次数、 近30天购物车类目金额、 近90天购物车类目次数、 近90天购物车类目金额----分析用户最近都挑中哪些类目。 |
5.4.4 用户访问信息表
根据客户访问的情况提取相关客户标签。
用于了解用户的访问总体情况,方便根据客户游览习惯做营销
主要数据来源:点击流日志行为表(PC/APP端)
点击流日志行为表可以得到相关标签:
|
最近一次APP/PC端访问日期、 最近一次APP/PC端访问使用操作系统、 最近一次APP/PC端访问使用游览器、 最近一次访问IP地址、 最近一次访问城市、 最近一次访问的省份-----分析用户最近一次访问情况。
第一次APP/PC端访问日期、 第一次APP/PC端访问使用操作系统、 第一次APP/PC端访问使用游览器、 第一次访问IP地址、 第一次访问城市、 第一次访问的省份-----分析用户第一次访问情况。
近7天APP/PC端访问次数、 近30天APP/PC访问次数、 近60天APP/PC端访问次数、 近90天APP/PC端访问次数、 近180天APP/PC端访问次数、 近365天APP/PC端访问次数----分析用户APP/PC端访问次数。
近30天PC/APP端访问天数、 近30天PC/APP端访问并购买次数、 近30天PC/APP端访问PV、 近30天PC/APP端访问平均PV、 近30天PC/APP端最常用的游览器、 近30天PC/APP端不同IP数、 近30天PC/APP端最常用IP-----分析用户访问详情。
近30天0-5点访问的次数、 近30天6-7点访问的次数、 近30天8-9点访问的次数、 近30天10-12点访问的次数、 近30天13-14点访问的次数、 近30天15-17点访问的次数、 近30天18-19点访问的次数、 近30天20-21点访问的次数、 近30天22-23点访问的次数----分析用户喜欢在哪个时间上网访问。 |
六、 电商用户画像环境搭建
众所周知,Hive的执行任务是将hql语句转化为MapReduce来计算的,Hive的整体解决方案很不错,但是从查询提交到结果返回需要相当长的时间,查询耗时太长。这个主要原因就是由于Hive原生是基于MapReduce的,那么如果我们不生成MapReduce Job,而是生成Spark Job,就可以充分利用Spark的快速执行能力来缩短HiveHQL的响应时间。
本项目采用SparkSql与hive进行整合(spark on hive),通过SparkSql读取hive中表的元数据,把HiveHQL底层采用MapReduce来处理任务,导致性能慢的特点,改为更加强大的Spark引擎来进行相应的分析处理,快速的为用户打上标签构建用户画像。
6.1 环境准备
- 1、搭建hadoop集群
- 2、安装hive构建数据仓库
- 3、安装spark集群
- 4、sparksql 整合hive
6.2 sparksql整合hive
Spark SQL主要目的是使得用户可以在Spark上使用SQL,其数据源既可以是RDD,也可以是外部的数据源(比如文本、Hive、Json等)。Spark SQL的其中一个分支就是Spark on Hive,也就是使用Hive中HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业。SparkSql整合hive就是获取hive表中的元数据信息,然后通过SparkSql来操作数据。
整合步骤:
① 需要将hive-site.xml文件拷贝到Spark的conf目录下,这样就可以通过这个配置文件找到Hive的元数据以及数据存放位置。
② 如果Hive的元数据存放在mysql中,我们还需要准备好Mysql相关驱动,比如:mysql-connector-java-5.1.35.jar
6.3 测试sparksql整合hive是否成功
先启动hadoop集群,在启动spark集群,确保启动成功之后执行命令:
|
/var/local/spark/bin/spark-sql --master spark://itcast01:7077 --executor-memory 1g --total-executor-cores 4 |
指明master地址、每一个executor的内存大小、一共所需要的核数、
mysql数据库连接驱动。
执行成功后的界面:进入到spark-sql 客户端命令行界面
接下来就可以通过sql语句来操作数据库表:
查看当前有哪些数据库 ---show databases;
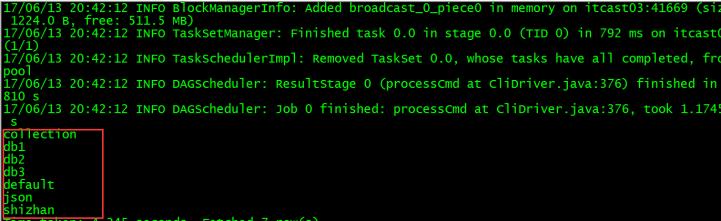
看到以上结果,说明sparksql整合hive成功!
日志太多,我们可以修改spark的日志输出级别(conf/log4j.properties)
前方高能:
在spark2.0版本后由于出现了sparkSession,在初始化sqlContext的时候,会设置默认的spark.sql.warehouse.dir=spark-warehouse,
此时将hive与sparksql整合完成之后,在通过spark-sql脚本启动的时候,还是会在哪里启动spark-sql脚本,就会在当前目录下创建一个spark.sql.warehouse.dir为spark-warehouse的目录,存放由spark-sql创建数据库和创建表的数据信息,与之前hive的数据信息不是放在同一个路径下(可以互相访问)。但是此时spark-sql中表的数据在本地,不利于操作,也不安全。
所有在启动的时候需要加上这样一个参数:
--conf spark.sql.warehouse.dir=hdfs://node1:9000/user/hive/warehouse
保证spark-sql启动时不在产生新的存放数据的目录,sparksql与hive最终使用的是hive同一存放数据的目录。
如果使用的是spark2.0之前的版本,由于没有sparkSession,不会有spark.sql.warehouse.dir配置项,不会出现上述问题。
最后的执行脚本;
|
spark-sql \\ --master spark://node1:7077 \\ --executor-memory 1g \\ --total-executor-cores 2 \\ --conf spark.sql.warehouse.dir=hdfs://node1:9000/user/hive/warehouse |
七、 电商用户画像数据仓库建立
7.1 数据仓库准备工作
为什么要对数据仓库分层?星型模型 雪花模型
User----->web界面展示指标表
l 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;
l 如果不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大
l 通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
数据仓库标准上可以分为四层:ODS(临时存储层)、PDW(数据仓库层)、MID(数据集市层)、APP(应用层)
ODS层:
为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。一般来说ODS层的数据和源系统的数据是同构的,主要目的是简化后续数据加工处理的工作。从数据粒度上来说ODS层的数据粒度是最细的。ODS层的表通常包括两类,一个用于存储当前需要加载的数据,一个用于存储处理完后的历史数据。历史数据一般保存3-6个月后需要清除,以节省空间。但不同的项目要区别对待,如果源系统的数据量不大,可以保留更长的时间,甚至全量保存;
PDW层:
为数据仓库层,PDW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。这一层的数据一般是遵循数据库第三范式的,其数据粒度通常和ODS的粒度相同。在PDW层会保存BI系统中所有的历史数据,例如保存10年的数据
MID层:
为数据集市层,这层数据是面向主题来组织数据的,通常是星形或雪花结构的数据。从数据粒度来说,这层的数据是轻度汇总级的数据,已经不存在明细数据了。从数据的时间跨度来说,通常是PDW层的一部分,主要的目的是为了满足用户分析的需求,而从分析的角度来说,用户通常只需要分析近几年(如近三年的数据)的即可。从数据的广度来说,仍然覆盖了所有业务数据。
APP层:
为应用层,这层数据是完全为了满足具体的分析需求而构建的数据,也是星形或雪花结构的数据。从数据粒度来说是高度汇总的数据。从数据的广度来说,则并不一定会覆盖所有业务数据,而是MID层数据的一个真子集,从某种意义上来说是MID层数据的一个重复。从极端情况来说,可以为每一张报表在APP层构建一个模型来支持,达到以空间换时间的目的数据仓库的标准分层只是一个建议性质的标准,实际实施时需要根据实际情况确定数据仓库的分层,不同类型的数据也可能采取不同的分层方法。
这里我们采用的是京东的数据仓库分层模式,是根据标准的模型演化而来。
数据仓库分层:
BDM:缓冲数据,源数据的直接映像
FDM:基础数据层,数据拉链处理、分区处理
GDM:通用聚合
ADM:高度聚合
先把数据从源数据库中抽取加载到BDM层中,
然后FDM层根据BDM层的数据按天分区
7.2 数据仓库基本表介绍
|
BDM层数据表 (贴源缓存层)
|
订单表
|
itcast_bdm_order |
|
订单明细表
|
itcast_bdm_order_desc |
|
|
订单商品表
|
itcast_bdm_order_goods |
|
|
用户表
|
itcast_bdm_user |
|
|
购物车表
|
itcast_bdm_order_cart |
|
|
用户上网记录表
|
itcast_bdm_user_pc_click_log itcast_bdm_user_app_click_log |
|
FDM层数据表 (拉链表、分区表)
|
用户宽表 |
itcast_fdm_user_wide |
|
购物车表 |
itcast_fdm_order_cart |
|
|
订单表 |
itcast_fdm_order |
|
|
订单表明细表 |
itcast_fdm_order_desc |
|
|
用户app端view表 |
itcast_fdm_user_app_pageview |
|
|
用户pc端view表 |
itcast_fdm_user_pc_pageview |
|
|
GDM层数据表 (通用数据模型层)
|
客户基本属性表 |
itcast_gdm_user_basic |
|
客户消费订单表 |
itcast_gdm_user_consume_order |
|
|
订单模型表 |
itcast_gdm_order |
|
|
客户购买类目表 |
itcast_gdm_user_buy_category |
|
|
客户访问信息表 |
itcast_gdm_user_visit |
八、 电商用户画像开发
8.1用户画像--数据开发的步骤
u 数据开发前置依赖
-需求确定 pv uv topn
-建模确定表结构 create table t1(pv int,uv int,topn string)
-实现方案确定
u 数据开发过程
-表落地
-写sql语句实现业务逻辑
-部署代码
-数据测试
-试运行与上线
在接下来的客户基本属性表开发中演示开发的流程。
8.2 用户画像开发--客户基本属性表
|
--用户画像-客户基本属性模型表 create database if not exists gdm; create table if not exists gdm.itcast_gdm_user_basic( user_id string ,--用户ID user_name string ,--用户登陆名 user_sex string ,--用户性别 user_birthday string ,--用户生日 user_age bigint ,--用户年龄 constellation string ,--用户星座 province string ,--省份 city string ,--城市 city_level string ,--城市等级 hex_mail string ,--邮箱 op_mail string ,--邮箱运营商 hex_phone string ,--手机号 fore_phone string ,--手机前3位 op_phone string ,--手机运营商 add_time timestamp ,--注册时间 login_ip string ,--登陆ip地址 login_source string ,--登陆来源 request_user string ,--邀请人 total_mark bigint ,--会员积分 used_mark bigint ,--已使用积分 level_name string ,--会员等级名称 blacklist bigint ,--用户黑名单 is_married bigint ,--婚姻状况 education string ,--学历 monthly_money double ,--收入 profession string ,--职业 sex_model bigint ,--性别模型 is_pregnant_woman bigint ,--是否孕妇 is_have_children bigint ,--是否有小孩 children_sex_rate double ,--孩子性别概率 children_age_rate double ,--孩子年龄概率 is_have_car bigint ,--是否有车 potential_car_user_rate double ,--潜在汽车用户概率 phone_brand string ,--使用手机品牌 phone_brand_level string ,--使用手机品牌档次 phone_cnt bigint ,--使用多少种不同的手机 change_phone_rate bigint ,--更换手机频率 majia_flag string ,--马甲标志 majie_account_cnt bigint ,--马甲账号数量 loyal_model bigint ,--用户忠诚度 shopping_type_model bigint ,--用户购物类型 figure_model bigint ,--身材 stature_model bigint ,--身高 dw_date timestamp ) partitioned by (dt string); |
该模型表其基本信息主要来源于用户表、用户调查表。有静态信息和动态信息、后面的一些是数据挖掘模型(数据挖掘模型比较多,逻辑比较复杂,在机器学习课程中给大家介绍)。
|
#*************************** --客户基本属性模型表BDM层 create database if not exists bdm; create external table if not exists bdm.itcast_bdm_user( user_id string ,--用户ID user_name string ,--用户登陆名 user_sex string ,--用户性别 user_birthday string ,--用户生日 user_age bigint ,--用户年龄 constellation string ,--用户星座 province string ,--省份 city string ,--城市 city_level string ,--城市等级 hex_mail string ,--邮箱 op_mail string ,--邮箱运营商 hex_phone string ,--手机号 fore_phone string ,--手机前3位 op_phone string ,--手机运营商 add_time string ,--注册时间 login_ip string ,--登陆ip地址 login_source string ,--登陆来源 request_user string ,--邀请人 total_mark bigint ,--会员积分 used_mark bigint ,--已使用积分 level_name string ,--会员等级名称 blacklist bigint ,--用户黑名单 is_married bigint ,--婚姻状况 education string ,--学历 monthly_money double ,--收入 profession string --职业 ) partitioned by (dt string) row format delimited fields terminated by \',\'; alter table itcast_bdm_user add partition (dt=\'2017-01-01\') location \'/business/itcast_bdm_user/2017-01-01\';
--客户基本属性表FDM层 create database if not exists fdm; create table if not exists fdm.itcast_fdm_user_wide( user_id string ,--用户ID user_name string ,--用户登陆名 user_sex string ,--用户性别 user_birthday string ,--用户生日 user_age bigint ,--用户年龄 constellation string ,--用户星座 province string ,--省份 city string ,--城市 city_level string ,--城市等级 hex_mail string ,--邮箱 op_mail string ,--邮箱运营商 hex_phone string ,--手机号 fore_phone string ,--手机前3位 op_phone string ,--手机运营商 add_time string ,--注册时间 login_ip string ,--登陆ip地址 login_source string ,--登陆来源 request_user string ,--邀请人 total_mark bigint ,--会员积分 used_mark bigint ,--已使用积分 level_name string ,--会员等级名称 blacklist bigint &n 以上是关于用SparkSQL构建用户画像的主要内容,如果未能解决你的问题,请参考以下文章 |