不同子系统采用不同MySQL编码LATIN1和UTF8的兼容
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不同子系统采用不同MySQL编码LATIN1和UTF8的兼容相关的知识,希望对你有一定的参考价值。
程序处理
这是一个历史遗留系统, 旧的系统是C++开发的, 插入数据的时候, 没有统一mysql各个层次(服务器, 数据库, 表, 列)的编码, 这个情况基本上是MYSQL的默认安装导致的, 实际的数据编码为LATIN1, 而采用Java 开发的新的系统需要和这个遗留系统公用数据库, 采用的是UTF8编码, 碰到的问题是Java代码中获取到的中文为乱码.
搞清楚了这个问题, Java中把乱码转换为正常显示的UTF8编码的中文很简单, 下面是转换代码
/**
* LATIN1转UTF8
*
* @param latin1 LATIN1(ISO_8859_1)字符串
* @return UTF8字符串
*/
public String encodingConvert(String latin1) {
return new String(
latin1.getBytes(StandardCharsets.ISO_8859_1),
StandardCharsets.UTF_8
);
}这是使用程序代码的处理方式, 有的时候我们需要直接从SQL返回的结果集中直接拿到UTF8的数据, 看下面
SQL内置函数转换
上面通过程序代码可以处理字符集的转换, 下面通过SQL的方式转换
CONVERT和CAST函数: 首先需要把LATIN1的转为BINARY, 然后再把BINARY转为UTF8
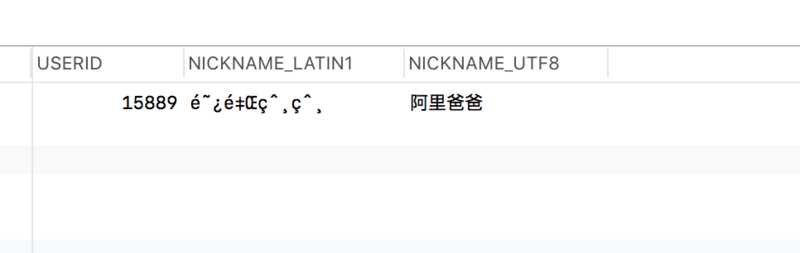
SELECT
USER.USERID AS USERID,
USER.NICKNAME AS NICKNAME_LATIN1,
CONVERT (
CAST(
CONVERT ( USER.NICKNAME USING latin1 ) AS BINARY
) USING utf8
) AS NICKNAME_UTF8
FROM
USER
WHERE
USERID = 15889;其中 LATIN1_COLUMN 是LATIN1 编码的字符集
最后, 我们可以把这样的转换做成一张视图, 程序就不用再转换了.
CREATE VIEW V_USER AS
SELECT
USER.USERID AS USERID,
CONVERT (
CAST(
CONVERT ( USER.NICKNAME USING latin1 ) AS BINARY
) USING utf8
) AS NICKNAME
FROM
USER;原文地址:https://segmentfault.com/a/1190000017061900
以上是关于不同子系统采用不同MySQL编码LATIN1和UTF8的兼容的主要内容,如果未能解决你的问题,请参考以下文章
使用 chardet 检测带有 JDBC 的 MySQL 数据库中的错误编码