Redis的安装与使用
Posted 梁颖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis的安装与使用相关的知识,希望对你有一定的参考价值。
一、Redis Mac 安装与使用
- 官网下载,下载 stable 版本,稳定版本。
- 解压:
tar zxvf redis-4.0.9.tar.gz - 移动到:
mv redis-4.0.9 /usr/local/ - 切换到:
cd /usr/local/redis-4.0.9/ -
- 编译测试 sudo make test
- 编译安装 sudo make install
redis 的启动与停止
redis-server 和 redis-cli 位于 redis-4.0.9/src 目录下
- 启动方式一:直接启动 Redis: redis-server ,成功后会看到下图:
- 启动方式二:启动 Redis 并加载配置文件: redis-server /etc/redis.conf
打开redis客户端 redis-cli;如果有密码,可使用 auth yourpassword 做简单的密码登录
- 关闭方式一:在客户端执行 SHUTDOWN 可关闭 redis 服务如果关闭不了就加一个参数,执行 SHUTDOWN NOSAVE 可关闭 redis 服务
- 关闭方式二:如果用了zsh,可以执行kill redis并按tab,结束 redis 进程,也可在活动监视器里结束掉进程
二、Python操作Redis
|
1
2
3
4
5
6
7
|
sudo pip install redisorsudo easy_install redisor源码安装详见:https://github.com/WoLpH/redis-py |
API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
|
1
2
3
4
5
6
7
8
|
#!/usr/bin/env python# -*- coding:utf-8 -*-import redisr = redis.Redis(host=\'10.211.55.4\', port=6379)r.set(\'foo\', \'Bar\')print r.get(\'foo\') |
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
|
1
2
3
4
5
6
7
8
9
10
|
#!/usr/bin/env python# -*- coding:utf-8 -*-import redispool = redis.ConnectionPool(host=\'10.211.55.4\', port=6379)r = redis.Redis(connection_pool=pool)r.set(\'foo\', \'Bar\')print r.get(\'foo\') |
3、操作
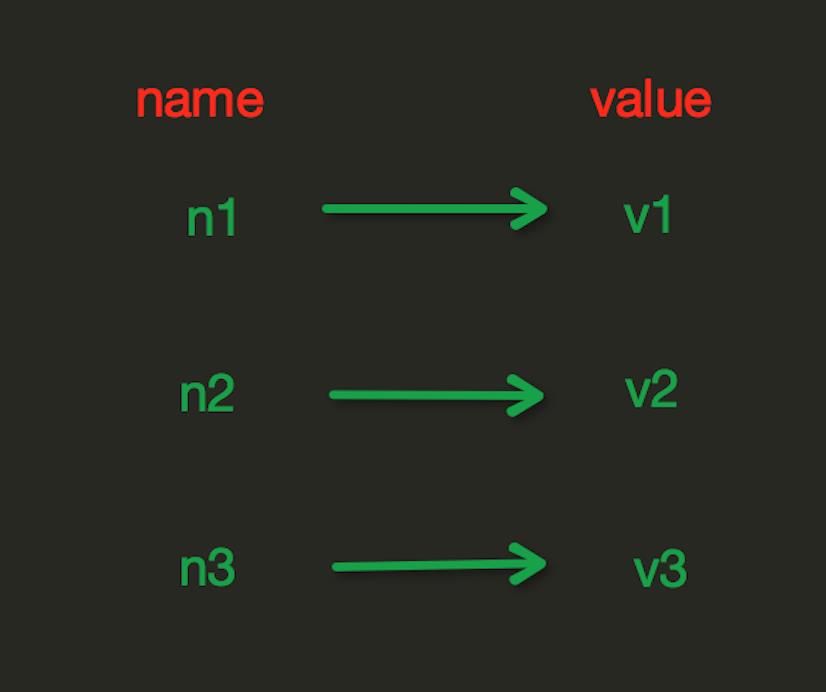
String操作,redis中的String在在内存中按照一个name对应一个value来存储。如图:
set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改参数:ex,过期时间(秒)px,过期时间(毫秒)nx,如果设置为True,则只有name不存在时,当前set操作才执行xx,如果设置为True,则只有name存在时,岗前set操作才执行setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加)setex(name, value, time)
# 设置值# 参数:# time,过期时间(数字秒 或 timedelta对象)psetex(name, time_ms, value)
# 设置值# 参数:# time_ms,过期时间(数字毫秒 或 timedelta对象)mset(*args, **kwargs)
批量设置值如:mset(k1=\'v1\', k2=\'v2\')或mget({\'k1\':\'v1\',\'k2\':\'v2\'})get(name)
获取值mget(keys, *args)
批量获取如:mget(\'ylr\',\'wupeiqi\')或r.mget([\'ylr\',\'wupeiqi\'])getset(name, value)
设置新值并获取原来的值getrange(key, start, end)
# 获取子序列(根据字节获取,非字符)# 参数:# name,Redis 的 name# start,起始位置(字节)# end,结束位置(字节)# 如: "武沛齐" ,0-3表示 "武"setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)# 参数:# offset,字符串的索引,字节(一个汉字三个字节)# value,要设置的值setbit(name, offset, value)
# 对name对应值的二进制表示的位进行操作# 参数:# name,redis的name# offset,位的索引(将值变换成二进制后再进行索引)# value,值只能是 1 或 0# 注:如果在Redis中有一个对应: n1 = "foo",那么字符串foo的二进制表示为:011001100110111101101111所以,如果执行 setbit(\'n1\',7,1),则就会将第7位设置为1,那么最终二进制则变成011001110110111101101111,即:"goo"# 扩展,转换二进制表示:# source = "武沛齐"source="foo"foriinsource:num=ord(i)bin(num).replace(\'b\',\'\')特别的,如果source是汉字"武沛齐"怎么办?答:对于utf-8,每一个汉字占3个字节,那么"武沛齐"则有9个字节对于汉字,for循环时候会按照 字节 迭代,那么在迭代时,将每一个字节转换 十进制数,然后再将十进制数转换成二进制111001101010110110100110111001101011001010011011111010011011110110010000------------------------------------------------------------------------------------武 沛 齐getbit(name, offset)
# 获取name对应的值的二进制表示中的某位的值 (0或1)bitcount(key, start=None, end=None)
# 获取name对应的值的二进制表示中 1 的个数# 参数:# key,Redis的name# start,位起始位置# end,位结束位置bitop(operation, dest, *keys)
# 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值# 参数:# operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或)# dest, 新的Redis的name# *keys,要查找的Redis的name# 如:bitop("AND",\'new_name\',\'n1\',\'n2\',\'n3\')# 获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name 对应的值中strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)incr(self, name, amount=1)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。# 参数:# name,Redis的name# amount,自增数(必须是整数)# 注:同incrbyincrbyfloat(self, name, amount=1.0)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。# 参数:# name,Redis的name# amount,自增数(浮点型)decr(self, name, amount=1)
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。# 参数:# name,Redis的name# amount,自减数(整数)append(key, value)
# 在redis name对应的值后面追加内容# 参数:key, redis的namevalue, 要追加的字符串
Hash操作,redis中Hash在内存中的存储格式如下图:

hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)# 参数:# name,redis的name# key,name对应的hash中的key# value,name对应的hash中的value# 注:# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)hmset(name, mapping)
# 在name对应的hash中批量设置键值对# 参数:# name,redis的name# mapping,字典,如:{\'k1\':\'v1\', \'k2\': \'v2\'}# 如:# r.hmset(\'xx\', {\'k1\':\'v1\', \'k2\': \'v2\'})hget(name,key)
# 在name对应的hash中获取根据key获取valuehmget(name, keys, *args)
# 在name对应的hash中获取多个key的值# 参数:# name,reids对应的name# keys,要获取key集合,如:[\'k1\', \'k2\', \'k3\']# *args,要获取的key,如:k1,k2,k3# 如:# r.mget(\'xx\', [\'k1\', \'k2\'])# 或# print r.hmget(\'xx\', \'k1\', \'k2\')hgetall(name)
获取name对应hash的所有键值hlen(name)
# 获取name对应的hash中键值对的个数hkeys(name)
# 获取name对应的hash中所有的key的值hvals(name)
# 获取name对应的hash中所有的value的值hexists(name, key)
# 检查name对应的hash是否存在当前传入的keyhdel(name,*keys)
# 将name对应的hash中指定key的键值对删除hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount# 参数:# name,redis中的name# key, hash对应的key# amount,自增数(整数)hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount# 参数:# name,redis中的name# key, hash对应的key# amount,自增数(浮点数)# 自增name对应的hash中的指定key的值,不存在则创建key=amounthscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆# 参数:# name,redis的name# cursor,游标(基于游标分批取获取数据)# match,匹配指定key,默认None 表示所有的key# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数# 如:# 第一次:cursor1, data1 = r.hscan(\'xx\', cursor=0, match=None, count=None)# 第二次:cursor2, data1 = r.hscan(\'xx\', cursor=cursor1, match=None, count=None)# ...# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据# 参数:# match,匹配指定key,默认None 表示所有的key# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数# 如:# for item in r.hscan_iter(\'xx\'):# print item
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:

lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边# 如:# r.lpush(\'oo\', 11,22,33)# 保存顺序为: 33,22,11# 扩展:# rpush(name, values) 表示从右向左操作lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边# 更多:# rpushx(name, value) 表示从右向左操作llen(name)
# name对应的list元素的个数linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值# 参数:# name,redis的name# where,BEFORE或AFTER# refvalue,标杆值,即:在它前后插入数据# value,要插入的数据r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值# 参数:# name,redis的name# index,list的索引位置