LevelDB速记
Posted boiledwater
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LevelDB速记相关的知识,希望对你有一定的参考价值。
LevelDb的基本结构如下:
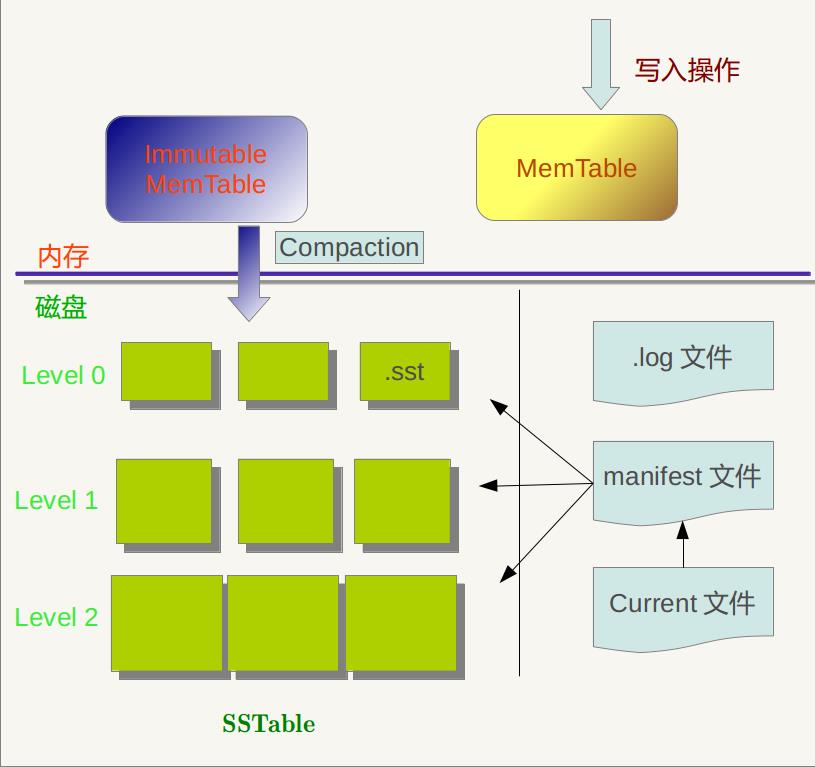
由六大部分组成:
一、MemTable,用户写入和读取的直接对象,
二、Immutable MemTable,用户状态写入的对象写满的MemTable之后会转为ImmutableMemTable,之后会写sst文件,
三、LOG文件,是WAL机制的部分,用户在写入MemTable的时候会先写入LOG文件,用来进行灾备恢复
四、SST文件,在磁盘上的文件,基本是一种KV结构,进行state持久存储的地方,
五、Current文件,有多个manifest文件,current文件指明了最新的manifest文件是哪个,
六、Manifest文件,记载了所有的sst文件的level层级,以及响应的key的范围分布。
杂记如下:
leveldb Compaction 会在以下场景触发:
DB::Open时检查条件满足时,触发
DB::Write操作里的MakeRoomForWrite的条件满足时,触发
DB::Get操作时,在内存中没有命中且Seek文件超过阈值时,触发
DB::CompactRange时,触发
Compaction带来的问题
写放大
从上面的compaction可以得知,当一个key频繁更新时,每次compaction在该key上都会导致重叠,
因此会 发生一次该key的搬移,导致实际的磁盘写量大于用户调用的写量。
读放大
leveldb是以文件为单位读取的,当Get一个已经被compaction搬移到深层次的key时,会发生多次文件的 读取,
导致实际的磁盘读量大于用户Get的调用量。同时compaction时也会产生大量的读取操作。
level的文件大小的限制
level0 有4个文件 每个1M 是4M
level1 十倍之 10M
level2 十倍之 100M
level3 1000M
level4 10G
level5 100G
level6 无限制
每一层文件的大小限制 为了控制每一层的文件是数量 进而优化每次major compaction的参与文件的多少和大小 优化效率
minor compaction的优先级高于major compaction 当需要进行minor compaction的时候发现有major compaction 则暂停major compaction
以进行minor compaction 因为minor compaction会影响到数据的插入
minor compaction
从memTable到sstFile 需要选择Level 根据memTable中的key的范围 如果和上层level中的数据有overlap 则直接合并到上层 但是
一般会是L1或者L2 这个也有参数控制
如果是比较新的key 则直接都生成在level0里面
Major compaction
从level0到上层level之间的合并
1.选择一个L层的文件,选择L+1层的所有key重叠的文件,与L层的文件做多路归并排序,生成新的文件到L+1层,原始的文件被删除。
记录L层文件的endKey
2.下次合并的时候,在L层中选择上次记录的endKey的近邻的key的文件用来合并。
3.如果L层的文件,没有和L+1层的有overlap,则直接更改指针,不发生文件的读写
4.选择L0层的文件时,会首先确定一个key range,但是由于L0的key在文件之间会有重叠,则需要选择该范围之内的
所有L0层的文件参与合并。
5.积分计算 计算每一层的积分 如果积分小于1 则不发生合并 如果大于1 则选择最大的一个 进行合并
寻找输入文件
正常合并 轮询选择 记录上一次的最大key 下次选择此key之后的文件
seek失效合并 则输入文件即该失效文件
sstFile
data block 固定大小存储kv数据
meta block 存储kv对应的filter 即bloom filter 可能存在多个filter 目前就一个
metaindex block 指向meta block的索引 目前就一个filter 所以也就一行记录
index block 指向data block的索引 包含data block的偏移和大小以及包含的key的范围
footer 指向索引的索引 包含metaindex和index
读取的时候,根据metaFile定位到sstFile,读取footer定位到block,进而读取metaBlock判断是否存在,如果存在再读取dataBlock
cache
table cache 缓存文件指针 metablock index-block
block cache 缓存数据 datablock indexblock
snapshot
insert sequence number 对应每一次的插入 亦即对应到一个key上
做快照 就只是保存一下这个number
读快照的时候 就需要读取所有小于这个Number的数据即可
以上是关于LevelDB速记的主要内容,如果未能解决你的问题,请参考以下文章