oracle 优化之组合索引
Posted 翰墨文海 QQ1319820057
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了oracle 优化之组合索引相关的知识,希望对你有一定的参考价值。
组合索引适用场景:
1.适用在单独查询返回记录很多,组合查询后忽然返回记录很少的情况:
比如where 学历=硕士以上 返回不少的记录
比如where 职业=收银员 同样返回不少的记录
于是无论哪个条件查询做索引,都不合适。
可是,如果学历为硕士以上,同时职业又是收银员的,返回的就少之又少了。
于是联合索引就可以这么开始建了。
2.组合查询的组合顺序,要考虑单独的前缀查询情况(否则单独前缀查询的索引不能生效或者只能用到跳跃索引)
比如你在建id,object_type的联合索引时,要看考虑是单独where id=xxx查询的多,还是单独where object_type查询的多。
这里细节就暂时略去了,在案例的部分中还有描述
结论就是:
组合索引过滤条件跟顺序有关系(当没有严格按照过略条件建索引时,某些情况下还是会利用组合索引,因为成本低)
3.仅等值无范围查询时,组合索引顺序不影响性能(比如where col1=xxx and col2=xxx,无论COL1+COL2组合还是COL2+COL1组合)
drop table t purge;
create table t as select * from dba_objects;
insert into t select * from t;
insert into t select * from t;
insert into t select * from t;
update t set object_id=rownum ;
commit;
create index idx_id_type on t(object_id,object_type);
create index idx_type_id on t(object_type,object_id);
set autotrace off
alter session set statistics_level=all ;
set linesize 200
select /*+index(t,idx_id_type)*/ * from t where object_id=20 and object_type=\'TABLE\';
select * from table(dbms_xplan.display_cursor(null,null,\'allstats last\'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 7qydm6x641kx4, child number 1
-------------------------------------
select /*+index(t,idx_id_type)*/ * from t where object_id=20 and
object_type=\'TABLE\'
Plan hash value: 1470938839
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 5 |
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 1 | 1 |00:00:00.01 | 5 |
|* 2 | INDEX RANGE SCAN | IDX_ID_TYPE | 1 | 1 | 1 |00:00:00.01 | 4 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=20 AND "OBJECT_TYPE"=\'TABLE\')
Note
-----
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
- cardinality feedback used for this statement
24 rows selected.
可以看出走的是索引范围扫描,并且回表。
过略的条件不同,走的执行计划是不是也不一样?
当不用hints,不同的过略条件是不是走的执行计划不一样?
SQL> select * from t where object_id=20 and object_type=\'TABLE\';
OWNER OBJECT_NAME SUBOBJECT_NAME
------------------------------ -------------------------------------------------------------------------------------------------------------------------------- ------------------------------
OBJECT_ID DATA_OBJECT_ID OBJECT_TYPE CREATED LAST_DDL_ TIMESTAMP STATUS T G S NAMESPACE EDITION_NAME
---------- -------------- ------------------- --------- --------- ------------------- ------- - - - ---------- ------------------------------
SYS IND$
20 2 TABLE 24-AUG-13 24-AUG-13 2013-08-24:11:37:35 VALID N N N 1
SQL> select * from table(dbms_xplan.display_cursor(null,null,\'allstats last\'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID ab3ng9dr3vkfw, child number 1
-------------------------------------
select * from t where object_id=20 and object_type=\'TABLE\'
Plan hash value: 1470938839
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 5 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 1 | 1 |00:00:00.01 | 5 |
|* 2 | INDEX RANGE SCAN | IDX_ID_TYPE | 1 | 1 | 1 |00:00:00.01 | 4 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=20 AND "OBJECT_TYPE"=\'TABLE\')
Note
-----
- cardinality feedback used for this statement
23 rows selected.
很明显,两个过滤条件顺序不一样,执行计划走的索引也不一样,不过后面都是索引范围扫面在通过行id 得出结果。
删除索引后,然后执行不同的过滤条件,结果有什么不一样?
SQL> drop index IDX_ID_TYPE;
Index dropped.
SQL>
SQL>
SQL>
SQL> select * from t where object_id=20 and object_type=\'TABLE\';
OWNER OBJECT_NAME SUBOBJECT_NAME
------------------------------ -------------------------------------------------------------------------------------------------------------------------------- ------------------------------
OBJECT_ID DATA_OBJECT_ID OBJECT_TYPE CREATED LAST_DDL_ TIMESTAMP STATUS T G S NAMESPACE EDITION_NAME
---------- -------------- ------------------- --------- --------- ------------------- ------- - - - ---------- ------------------------------
SYS IND$
20 2 TABLE 24-AUG-13 24-AUG-13 2013-08-24:11:37:35 VALID N N N 1
SQL>
SQL> select * from table(dbms_xplan.display_cursor(null,null,\'allstats last\'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID ab3ng9dr3vkfw, child number 1
-------------------------------------
select * from t where object_id=20 and object_type=\'TABLE\'
Plan hash value: 3420768628
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 5 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 1 | 1 |00:00:00.01 | 5 |
|* 2 | INDEX RANGE SCAN | IDX_TYPE_ID | 1 | 1 | 1 |00:00:00.01 | 4 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_TYPE"=\'TABLE\' AND "OBJECT_ID"=20)
Note
-----
- dynamic sampling used for this statement (level=2)
23 rows selected.
发现也会走索引扫面,只是用的另外一个顺序不一样的索引(因为cbo成本比全表扫描低,还是会走另一个成本低的组合索引)
--4.组合索引最佳顺序一般是将列等值查询的列置前。
(测试组合索引在条件是不等的情况下的情况,条件经常是不等的,要放在后面,让等值的在前面)
Execution Plan
----------------------------------------------------------
Plan hash value: 1470938839
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 16 | 3312 | 52 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 16 | 3312 | 52 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_ID_TYPE | 50 | | 51 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID">=20 AND "OBJECT_TYPE"=\'TABLE\' AND "OBJECT_ID"<2000)
filter("OBJECT_TYPE"=\'TABLE\')
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
89 consistent gets
0 physical reads
0 redo size
51596 bytes sent via SQL*Net to client
875 bytes received via SQL*Net from client
34 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
493 rows processed
通过索引快速扫面获得行ID进行回表。
5.注意组合索引与组合条件中关于IN 的优化
案例1
UPDATE t SET OBJECT_ID=20 WHERE ROWNUM<=26000;
UPDATE t SET OBJECT_ID=21 WHERE OBJECT_ID<>20;
COMMIT;
set linesize 1000
set pagesize 1
alter session set statistics_level=all ;
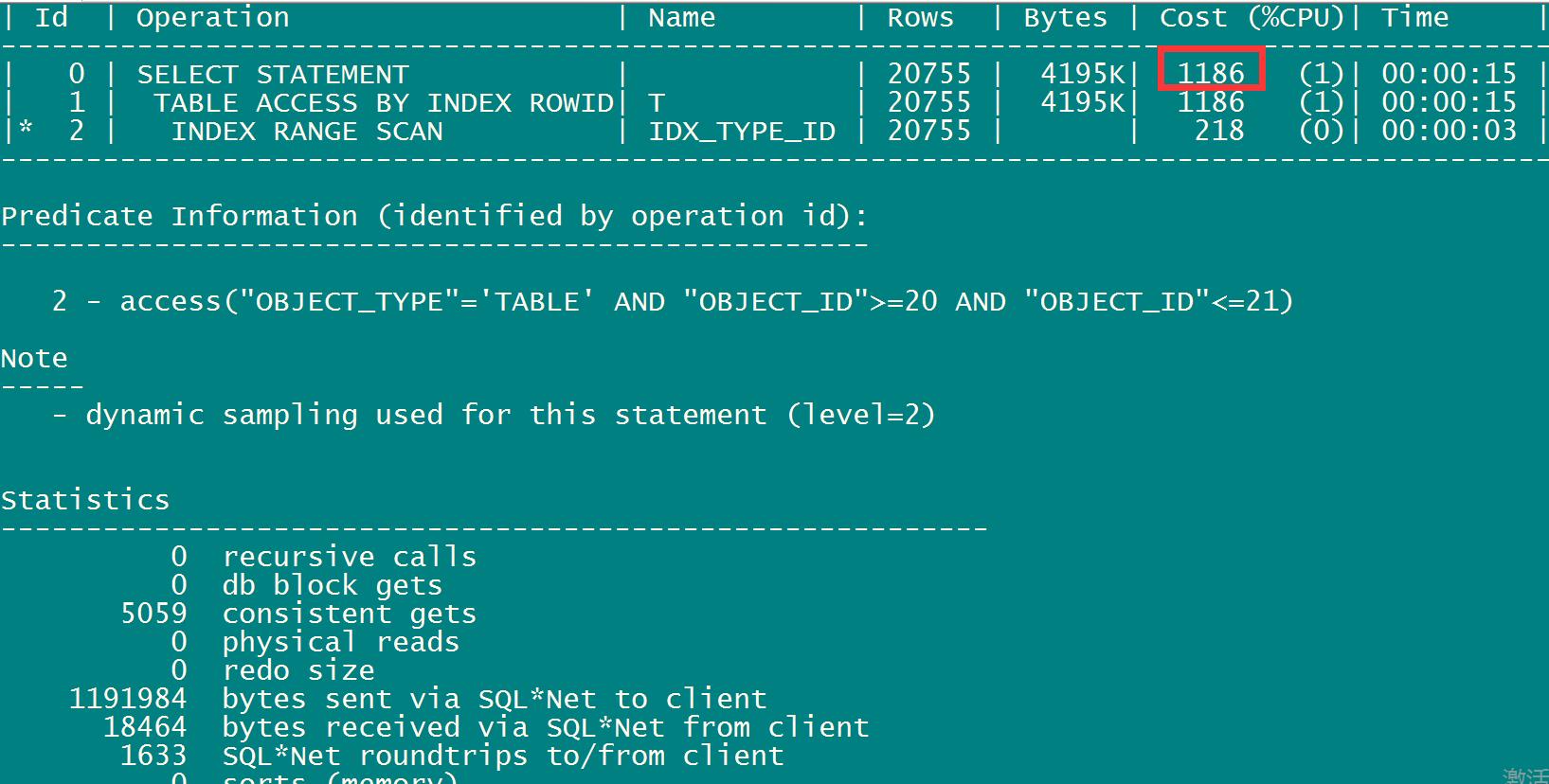
select /*+index(t,idx1_object_id)*/ * from t where object_TYPE=\'TABLE\' AND OBJECT_ID >= 20 AND OBJECT_ID<= 21;
Execution Plan
----------------------------------------------------------
Plan hash value: 3420768628
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20755 | 4195K| 1186 (1)| 00:00:15 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 20755 | 4195K| 1186 (1)| 00:00:15 |
|* 2 | INDEX RANGE SCAN | IDX_TYPE_ID | 20755 | | 218 (0)| 00:00:03 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_TYPE"=\'TABLE\' AND "OBJECT_ID">=20 AND "OBJECT_ID"<=21)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
5059 consistent gets
0 physical reads
0 redo size
1191984 bytes sent via SQL*Net to client
18464 bytes received via SQL*Net from client
1633 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
24472 rows processed
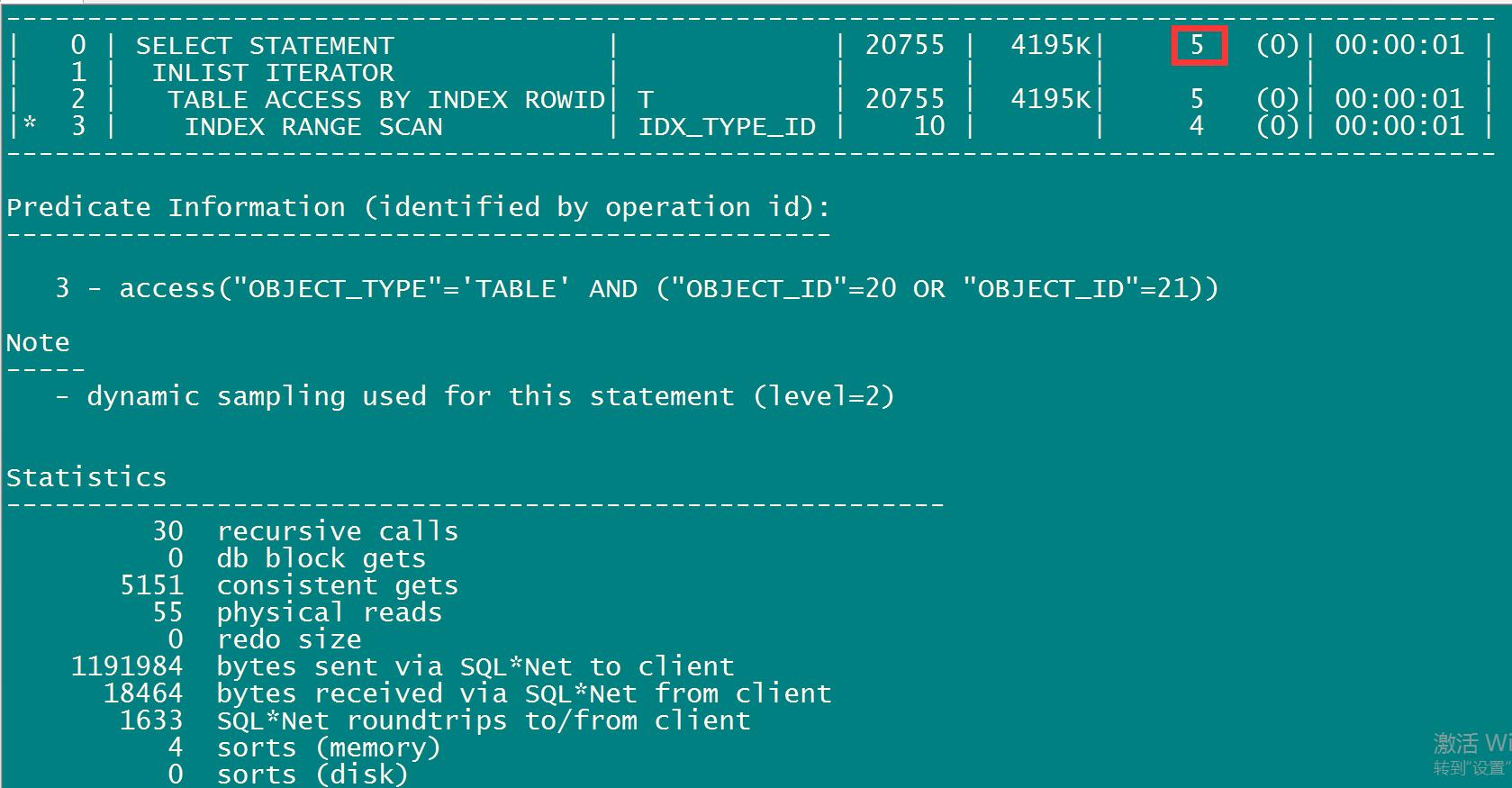
select /*+index(t,idx1_object_id)*/ * from t where object_TYPE=\'TABLE\' AND OBJECT_ID in (20,21);
以上两个语句:
select /*+index(t,idx1_object_id)*/ * from t where object_TYPE=\'TABLE\' AND OBJECT_ID >= 20 AND OBJECT_ID<= 21; --CPU cost消耗1186
select /*+index(t,idx1_object_id)*/ * from t where object_TYPE=\'TABLE\' AND OBJECT_ID in (20,21); -- CPU cost消耗仅仅为5
为何消耗的CPU成本差距这么大?
在人为的思考中,我们人为认为 (OBJECT_ID >= 20 AND OBJECT_ID<= 21) = in (20,21),而其实oracle 不这么认为in (20,21) 只有两个值,而(OBJECT_ID >= 20 AND OBJECT_ID<= 21)走索引中间有无穷个键值。所以第二句消耗的CPU COST仅仅为5。
6.依然是关于IN的优化 (col1,col2,col3的索引情况,如果没有为COL2赋予查询条件时,COL3只能起到检验作用)
drop table t purge;
create table t as select * from dba_objects;
UPDATE t SET OBJECT_ID=20 WHERE ROWNUM<=26000;
UPDATE t SET OBJECT_ID=21 WHERE OBJECT_ID<>20;
Update t set object_id=22 where rownum<=10000;
COMMIT;
create index idx_union on t(object_type,object_id,owner);
set autotrace traceonly
select * from t where object_type=\'VIEW\' and OWNER=\'SYS\';
select * from table(dbms_xplan.display_cursor(null,null,\'allstats last\'));
Execution Plan
----------------------------------------------------------
Plan hash value: 1570829420
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3369 | 681K| 20 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 3369 | 681K| 20 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_UNION | 14 | | 19 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_TYPE"=\'VIEW\' AND "OWNER"=\'SYS\')
filter("OWNER"=\'SYS\')
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
686 consistent gets
0 physical reads
0 redo size
157650 bytes sent via SQL*Net to client
3405 bytes received via SQL*Net from client
264 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
3938 rows processed
SQL>
23 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3713220770
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8168 | 16336 | 29 (0)| 00:00:01 |
| 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY_CURSOR | 8168 | 16336 | 29 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
27 recursive calls
0 db block gets
136 consistent gets
0 physical reads
0 redo size
1925 bytes sent via SQL*Net to client
534 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
23 rows processed
select /*+INDEX(T,idx_union)*/ * from t T where object_type=\'VIEW\' and OBJECT_ID IN (20,21,22) AND OWNER=\'SYS\';
select * from table(dbms_xplan.display_cursor(null,null,\'allstats last\'));
Execution Plan
----------------------------------------------------------
Plan hash value: 306189815
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3369 | 681K| 6 (0)| 00:00:01 |
| 1 | INLIST ITERATOR | | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T | 3369 | 681K| 6 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | IDX_UNION | 1 | | 5 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("OBJECT_TYPE"=\'VIEW\' AND ("OBJECT_ID"=20 OR "OBJECT_ID"=21 OR
"OBJECT_ID"=22) AND "OWNER"=\'SYS\')
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
687 consistent gets
0 physical reads
0 redo size
157650 bytes sent via SQL*Net to client
3405 bytes received via SQL*Net from client
264 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
3938 rows processed
SQL>
23 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3713220770
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8168 | 16336 | 29 (0)| 00:00:01 |
| 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY_CURSOR | 8168 | 16336 | 29 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
15 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
1862 bytes sent via SQL*Net to client
534 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
23 rows processed
可以看出,select * from t where object_type=\'VIEW\' and OWNER=\'SYS\'; 这一条语句跟select /*+INDEX(T,idx_union)*/ * from t T where object_type=\'VIEW\' and OBJECT_ID IN (20,21,22) AND OWNER=\'SYS\';这一条语句代价等价,因为此案例中object_type=\'VIEW\' 且OBJECT_ID 只有20,21,22 这三条记录,所以如果没有为COL2赋予查询条件时,COL3只能起到检验作用。
以上是关于oracle 优化之组合索引的主要内容,如果未能解决你的问题,请参考以下文章