MySql 调优
Posted 随笔`
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySql 调优相关的知识,希望对你有一定的参考价值。
1.查询的方式: 二叉树,平衡二叉树(B-tree),完全平衡二叉树(B+Tree)
区别:https://blog.csdn.net/yuxin6866/article/details/52327328
2.数据库sql优化:
1).尽量少用 * 做查询列条件,
2).尽量不要在 列中插入函数计算,
3).尽量不用 like %
3.建联合索引列选择的原则:
1)经常用的列优先[最左匹配原则] 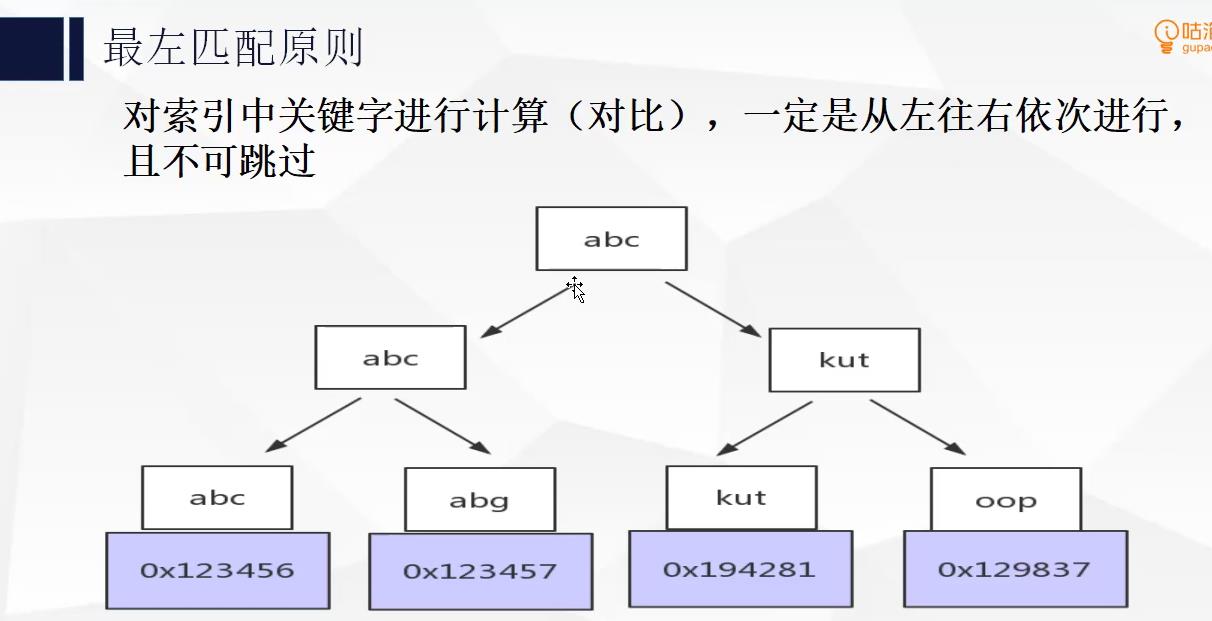
2)选择性(离散度)高的列优先[离散度高原则]
3)宽度小的列优先[最少空间原则]
以上都 二叉树查询相关知识

问题解答:
1.索引列的长度越短,一个数据页(默认是4k)中存储的关键字的数量就越多,树的深度就越浅,查询需要读取的节点就越少,查询效率就更高
2.因为联合索引的规则:类似于多个单列索引按到建索引的顺序拼凑成一个新的单列索引,所以同问题一一样,列数越少,索引长度就越短,查询效率就越高
3. 1)匹配前列9999% 可能用到索引,原因是二叉树中的比较方式 一般是从左往右比,单个字符的asiic码值比较,在遇到%之前的值是确定的,所以可以用索引去匹配一部分,但是有一点需要注意:
①如果%前面的字符存在很多列都相同的话,数据库会认为这个列的值不用索引和用索引查找都是一样的,数据库就会放弃索引,直接全表查找.
2)如果%在前面,二叉树查询的方法默认所有的值都符合要求,这样列的离散度就会变得极低,(相当于3.1.1) 数据库就会弃用索引的方式去匹配,
4.同理 not in 和<> 也是3.2这个原理
一般不要用如下的字句:
"IS NULL", " <>", "!=", "!>", "! <",
"NOT", "NOT EXISTS", "NOT IN", "NOT LIKE", and "LIKE \'%500\'",
因为他们不走索引全是表扫描。也不要在WHere字句中的列名加函数,如Convert,substring等,如果必须用函数的时候,创建计算列再创建索引来替代.还可以变通写法:WHERE SUBSTRING(firstname,1,1) = \'m\'改为WHERE firstname like \'m%\'(索引扫 描),一定要将函数和列名分开。并且索引不能建得太多和太大。NOT IN会多次扫描表,使用EXISTS、NOT EXISTS ,IN , LEFT OUTER JOIN 来替代,特别是左连接,而Exists比IN更快,最慢的是NOT操作.如果列的值含有空,以前它的索引不起作用, 现在2000的优化器能够处理了。相同的是IS NULL,“NOT", "NOT EXISTS", "NOT IN"能优化她,而” <>”等还是不能优化,用不到索引。
在IN后面值的列表中,将出现最频繁的值放在最前面,出现得最少的放在最后面,减少判断的次数
5.原因是,*,在数据库中不能使用索引的方式去查找,而指定列去查找,有可能会出现覆盖索引的情况,会大大提高查询的效率,
后面几条河 3 , 4 类似,都是索引失效的问题.
以下是关于数据库大批量数据数据库设计的建议
https://blog.csdn.net/Jason18086483725/article/details/78519070
以上是关于MySql 调优的主要内容,如果未能解决你的问题,请参考以下文章