scrapy_redis实现爬虫
Posted _夕颜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy_redis实现爬虫相关的知识,希望对你有一定的参考价值。
scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目的分布式开发和部署。
有如下特征:
增量式爬虫
可以继续执行程序,会发现程序在前一次的基础之上继续往后执行,是一个基于url地址的增量式的爬虫
分布式爬取
您可以启动多个spider工程,相互之间共享单个redis的requests队列。最适合广泛的多个域名网站的内容爬取。
分布式数据处理
爬取到的scrapy的item数据可以推入到redis队列中,这意味着你可以根据需求启动尽可能多的处理程序来共享item的队列,进行item数据持久化处理
Scrapy即插即用组件
Scheduler调度器 + Duplication复制 过滤器,Item Pipeline,基本spider
1、scrapy_redis的流程
- 在scrapy_redis中,所有的带抓取的对象和去重的指纹都存在所有的服务器公用的redis中
- 所有的服务器公用一个redis中的request对象
- 所有的request对象存入redis前,都会在同一个redis中进行判断,之前是否已经存入过
- 在默认的情况下,所有数据会存放在redis中
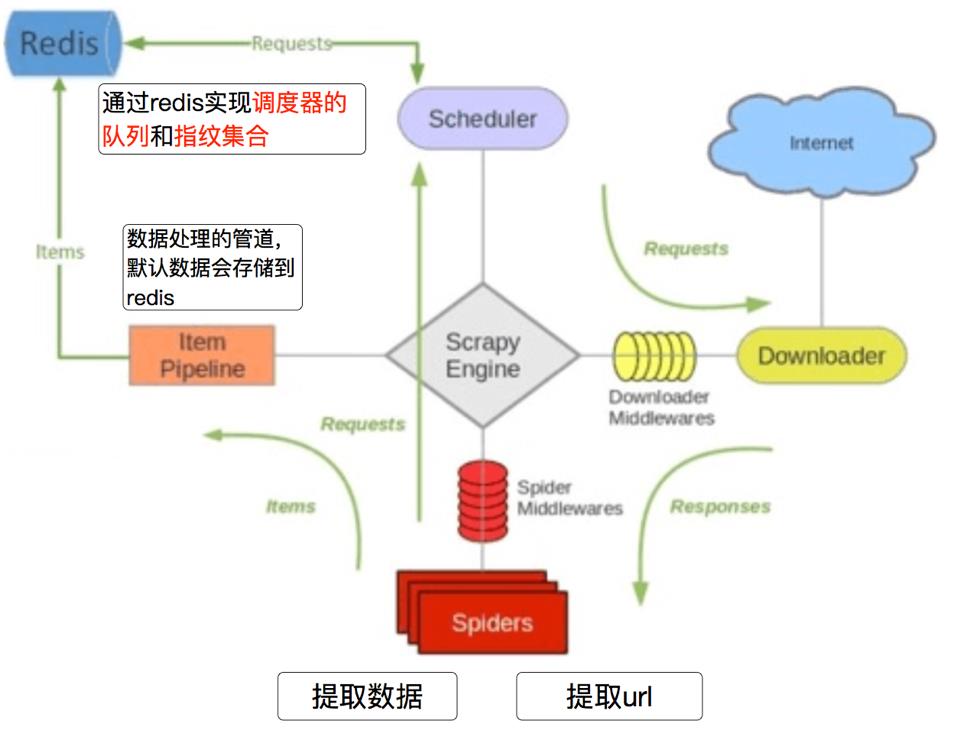
2、scrapy_redis的原理分析
我们从settings.py中的三个配置来进行分析 在settings.py中多了一下几行,这几行表示scrapy_redis中重新实现的了去重的类,以及调度器,并且使用的RedisPipeline:
- RedisPipeline
- RFPDupeFilter
- Schedule
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" SCHEDULER = "scrapy_redis.scheduler.Scheduler" SCHEDULER_PERSIST = True ITEM_PIPELINES = { \'example.pipelines.ExamplePipeline\': 300, \'scrapy_redis.pipelines.RedisPipeline\': 400, }
2.1、Scrapy_redis之RedisPipeline
RedisPipeline中观察process_item,进行数据的保存,存入了redis中

2.2 Scrapy_redis之RFPDupeFilter
RFPDupeFilter 实现了对request对象的加密

2.3 Scrapy_redis之Scheduler
scrapy_redis调度器的实现了决定什么时候把request对象加入带抓取的队列,同时把请求过的request对象过滤掉

由此可以总结出request对象入队的条件
- request之前没有见过
- request的dont_filter为True,即不过滤
- start_urls中的url地址会入队,因为他们默认是不过滤
1、增量式爬虫
在domz爬虫文件中,实现方式crawlspider类型的爬虫
from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class DmozSpider(CrawlSpider): """Follow categories and extract links.""" name = \'dmoz\' allowed_domains = [\'dmoztools.net\'] start_urls = [\'http://dmoztools.net/\'] # 定义数据提取规则,使用了css选择器 rules = [ Rule(LinkExtractor( restrict_css=(\'.top-cat\', \'.sub-cat\', \'.cat-item\') ), callback=\'parse_directory\', follow=True), ] def parse_directory(self, response): for div in response.css(\'.title-and-desc\'): yield { \'name\': div.css(\'.site-title::text\').extract_first(), \'description\': div.css(\'.site-descr::text\').extract_first().strip(), \'link\': div.css(\'a::attr(href)\').extract_first(), }
但是在settings.py中多了一下几行,这几行表示scrapy_redis中重新实现的了去重的类,以及调度器,并且使用的RedisPipeline
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" SCHEDULER = "scrapy_redis.scheduler.Scheduler" SCHEDULER_PERSIST = True ITEM_PIPELINES = { \'example.pipelines.ExamplePipeline\': 300, \'scrapy_redis.pipelines.RedisPipeline\': 400, }
运行dmoz爬虫,观察现象
1、首先我们需要添加redis的地址,程序才能够使用redis
REDIS_URL = "redis://127.0.0.1:6379" #或者使用下面的方式 # REDIS_HOST = "127.0.0.1" # REDIS_PORT = 6379
2、我们执行domz的爬虫,会发现redis中多了一下三个键:

3、继续执行程序
继续执行程序,会发现程序在前一次的基础之上继续往后执行,所以domz爬虫是一个基于url地址的增量式的爬虫
2、分布式爬虫
分析demo中代码

通过观察代码:
- 继承自父类为RedisSpider
- 增加了一个redis_key的键,没有start_urls,因为分布式中,如果每台电脑都请求一次start_url就会重复
- 多了
__init__方法,该方法不是必须的,可以手动指定allow_domains - 和scrapy中的crawlspider的区别在于,继承自的父类不相同,redis_key需要添加
实现当当网分布式爬虫
# -*- coding: utf-8 -*- from copy import deepcopy import scrapy from scrapy_redis.spiders import RedisSpider class DangdangSpider(RedisSpider): name = \'dangdang\' allowed_domains = [\'dangdang.com\'] # start_urls = [\'http://dangdang.com/\'] redis_key = \'dangdang\' def parse(self, response): # 获取大分类列表 div_list = response.xpath("//div[@class=\'con flq_body\']/div")[2:-1] for div in div_list: item = {} # 获取大分类名称 item[\'b_cate\'] = div.xpath(".//dl[contains(@class,\'primary_dl\')]/dt//text()").extract() # 获取中间分类列表 dl_list = div.xpath(".//dl[@class=\'inner_dl\']") for dl in dl_list: # 获取中间分类名称 item[\'m_cate\'] = dl.xpath(".//dt//text()").extract() # 获取小分类列表 a_list = dl.xpath("./dd/a") for a in a_list: # 获取小分类信息 item["s_cate"] = a.xpath("./text()").extract_first() item["s_href"] = a.xpath("./@href").extract_first() yield scrapy.Request( item["s_href"], callback=self.parse_book_list, meta={ "item": deepcopy(item) } ) def parse_book_list(self, response): item = response.meta[\'item\'] # 获取图书列表 li_list = response.xpath("//ul[@class=\'bigimg\']/li") for li in li_list: item[\'book_name\'] = li.xpath("./a/@title").extract_first() item[\'book_href\'] = li.xpath("./a/@href").extract_first() item[\'book_author\'] = li.xpath(".//p[@class=\'search_book_author\']/span[1]/a/text()").extract() item[\'book_press\'] = li.xpath(".//p[@class=\'search_book_author\']/span[3]/a/text()").extract_first() item[\'book_desc\'] = li.xpath(".//p[@class=\'detail\']/text()").extract_first() item[\'book_price\'] = li.xpath(".//span[@class=\'search_now_price\']/text()").extract_first() item["book_store_name"] = li.xpath(".//p[@class=\'search_shangjia\']/a/text()").extract_first() item[\'book_store_name\'] = "当当自营" if item["book_store_name"] is None else item["book_store_name"] yield item next_url = response.xpath("//li[@class=\'next\']/a/@href").extract_first() if next_url is not None: # 构造翻页请求 yield response.follow( next_url, callback=self.parse_book_list, meta={"item": item} )
在settings中进行配置
# 指定了去重的类 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 制定了调度器的类 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 调度器的内容是否持久化 SCHEDULER_PERSIST = True # redis的url地址 REDIS_URL = "redis://127.0.0.1:6379"
配置文件扩展
# 更改默认的配置 DEFAULT_LOG_FILENAME = \'日志文件.log\' # 默认日志文件名称 SPIDERS = [ "spiders.dangdang.Dangdang" ] PIPELINES = [ "pipelines.Pipeline", "pipelines.mysqlPipeline" ] SPIDER_MIDS = [ ] DOWNLOADER_MIDS = [ ] # 控制最大并发数 MAX_ASYNC_NUMBER = 1 # 异步模式 thread, coroutine ASYNC_TYPE = \'thread\' \'\'\'分布式配置\'\'\' # 执行角色 # None 代表非分布式,发起初始请求(_start_requests), 处理请求(_execute_request_response_item) # master代表主,只负责发起初始请求(_start_requests),并维护请求队列 # slave代表从,只负责处理请求(_execute_request_response_item) # ROLE = \'master\' # ROLE = \'slave\' ROLE = None # 最大重试次数 MAX_RETRY_TIMES = 3 # redis 队列的配置 REDIS_QUEUE_NAME = \'request_queue\' REDIS_QUEUE_HOST = \'localhost\' REDIS_QUEUE_PORT = 6379 REDIS_QUEUE_DB = 10 # reids 集合配置 REDIS_SET_NAME = \'filter_container\' REDIS_SET_HOST = \'localhost\' REDIS_SET_PORT = 6379 REDIS_SET_DB = 10 # 利用redis进行请求备份 的配置 REDIS_BACKUP_NAME = \'request_backup\' REDIS_BACKUP_HOST = \'localhost\' REDIS_BACKUP_PORT = 6379 REDIS_BACKUP_DB = 10
以上是关于scrapy_redis实现爬虫的主要内容,如果未能解决你的问题,请参考以下文章